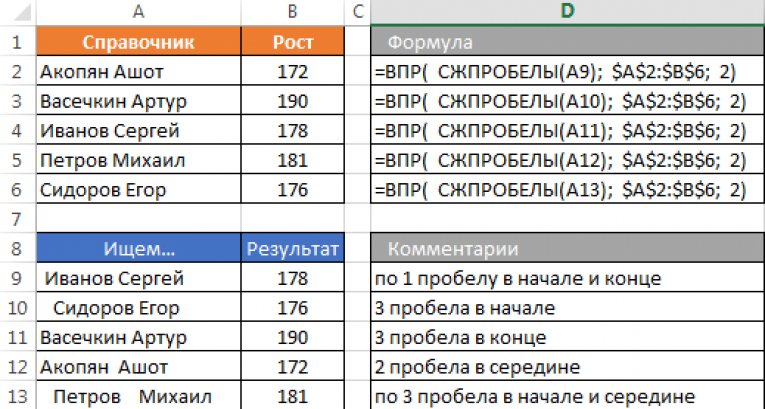
Впр использование: Использование функции ВПР (VLOOKUP) для подстановки значений
Содержание
Функция ПРОСМОТРX — наследник ВПР
5334
21.01.2020
Скачать пример
В мае 2019 года руководитель команды разработчиков Microsoft Excel Joe McDaid анонсировал выход новой функции, которая должна прийти на замену легендарной ВПР (VLOOKUP). Новая функция получила сочное английское название XLOOKUP и не очень внятное русское ПРОСМОТРX (причем последняя буква тут именно английская «икс», а не русская «ха» — забавно).
Полгода Microsoft тренировалась на кошках тестировала эту функцию на своих сотрудниках и добровольцах-инсайдерах и, наконец, в январе 2020 года было объявлено, что XLOOKUP готова к использованию и будет в ближайшее время разослана с обновлениями всем подписчикам Office 365.
Давайте разберёмся, в чем её преимущества перед классической ВПР (VLOOKUP), и как она может нам помочь в повседневной работе с данными в Microsoft Excel.
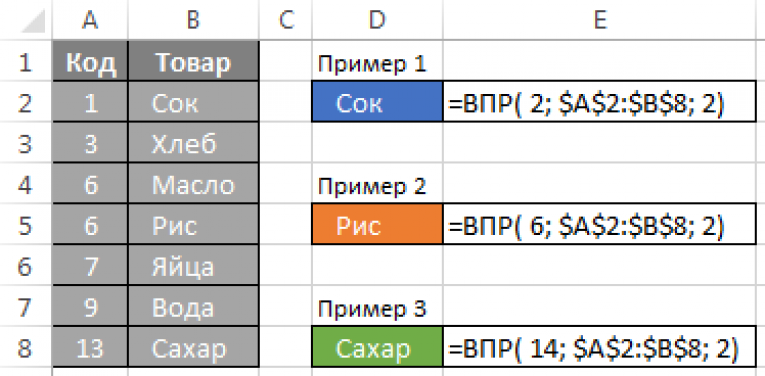
Старый добрый ВПР
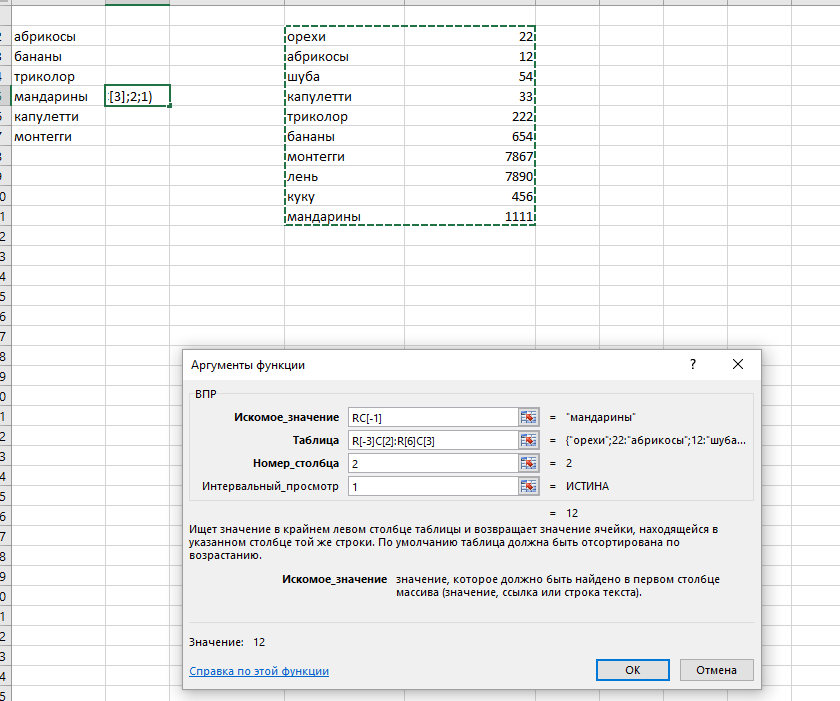
Предположим, перед нами стоит задача найти в прайс-листе цену, например, для гречки. При помощи привычно функции ВПР (VLOOKUP) это решалось бы примерно так:
На всякий случай, напомню:
- Первый аргумент здесь — искомое значение («гречка» из h5).
- Второй — область поиска, причем обязательно начиная со столбца, где хранятся искомые данные, т.е. с товара, а не с артикула.
- Третий — порядковый номер столбца в таблице, из которого мы хотим извлечь нужное нам значение (цена в четвертом столбце).
- Последний аргумент отвечает за режим поиска: 0 — точный поиск, 1 — поиск ближайшего наименьшего значения (для чисел). Причем 0 не подразумевается по умолчанию — нужно вводить его явно.
Привычно, знакомо и делается многими на автомате, не приходя в сознание. ОК.
Теперь посмотрим как то же самое можно вычислить с помощью новой функции ПРОСМОТРX (XLOOKUP).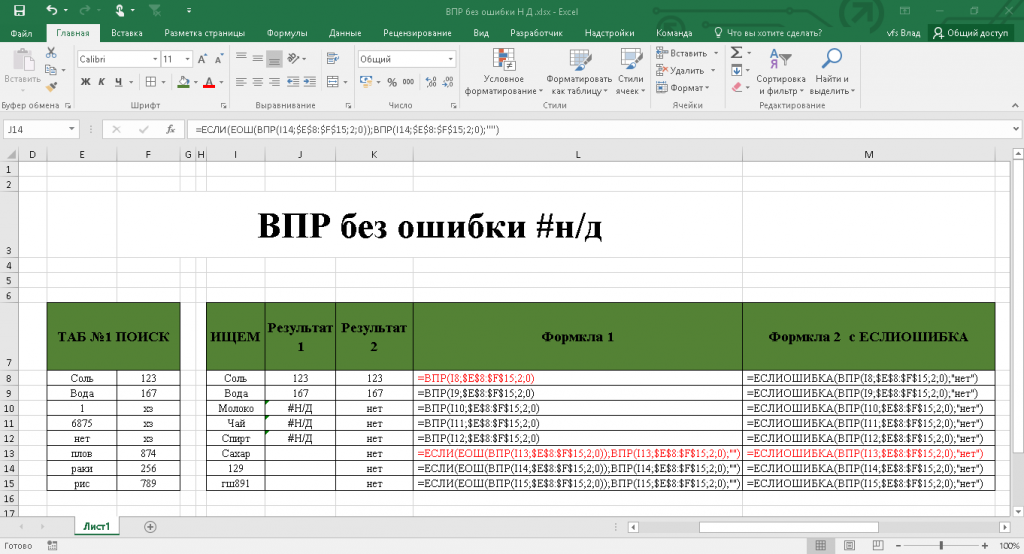
Синтаксис ПРОСМОТРX (XLOOKUP)
Сначала, для порядка, давайте озвучим официальный синтаксис. У нашей новой функции 6 аргументов:
=ПРОСМОТРX(искомое_значение; просматриваемый_массив; возвращаемый_массив; [если_ничего_не_найдено]; [режим_сопоставления]; [режим_поиска])
Выглядит немного громоздко, но последние три аргумента [в квадратных скобках] не являются обязательными (мы разберёмся с ними чуть позже). Так что, на самом деле, всё проще:
- Первый аргумент (искомое_значение) — что мы ищем («гречка» из ячейки h5)
-
Второй аргумент (просматриваемый_массив) — диапазон ячеек, где мы ищем (столбец Товар в прайс-листе). -
Третий аргумент (возвращаемый_массив) — диапазон, откуда хотим получить результаты (столбец Цена в прайс-листе).
Если сравнивать с ВПР, то стоит отметить, что:
- По умолчанию используется точный поиск, т.
 е. не нужно это явно прописывать как в ВПР (последний нолик).
е. не нужно это явно прописывать как в ВПР (последний нолик). - Не нужно отсчитывать и задавать номер столбца (третий аргумент ВПР). В больших таблицах это бывает непросто (особенно с учетом наличия скрытых столбцов).
- Из предыдущего пункта автоматом следует, что вставка/удаление столбцов в прайс не ломают формулу (как было бы с ВПР).
- Нет проблемы «левого ВПР», когда нужно извлечь значение левее просматриваемого столбца (например, артикул в нашем случае) — просматриваемый и возвращаемый массивы в ПРОСМОТРX могут располагаться как угодно (даже на разных листах, в общем случае!)
- В общем и целом синтаксис гораздо проще и понятнее, чем у ВПР.
 е. не нужно это явно прописывать как в ВПР (последний нолик).
е. не нужно это явно прописывать как в ВПР (последний нолик).
Также приятно, что ПРОСМОТРX отлично работает и в горизонтальном варианте без каких-либо доработок:
Раньше для этого нужно было использовать уже функцию ГПР (HLOOKUP) вместо ВПР (VLOOKUP).
Перехват ошибок #Н/Д
Если искомое значение отсутствует в списке, то функция ПРОСМОТРX, как и ВПР, выдаёт знакомую ошибку #Н/Д (#N/A):
Раньше для перехвата таких ошибок и замены их на что-нибудь более осмысленное применяли вложнную конструкцию из функций ЕСЛИОШИБКА (IFERROR) и ВПР (VLOOKUP). Теперь же можно сделать всё «на лету», используя 4-й аргумент [если_ничего_не_найдено] нашей новой функции :
Удобно.
Приблизительный поиск
Если мы ищем числа, то возможен поиск не только точного совпадения, но и ближайшего наименьшего или наибольшего к заданному числу. Например, для поиска ближайшей скидки, соответствующей определенному количеству товара или тарифа для расчета стоимости доставки на определенное расстояние.
В старой ВПР за это отвечал последний аргумент [интервальный_просмотр] — если задать его равным 1, то ВПР переходила в режим поиска ближайшего наименьшего значения. В ПРОСМОТРХ за этот функционал отвечает 5-й аргумент [режим_сопоставления]:
В ПРОСМОТРХ за этот функционал отвечает 5-й аргумент [режим_сопоставления]:
Он может работать по четырём различным сценариям:
- 0 — точный поиск (это режим по-умолчанию)
- -1 — поиск предыдущего, т.е. ближайшего наименьшего значения (для 29 шт. товара это будет скидка 5%)
- 1 — поиск следующего, т.е. ближайшего наибольшего (для 29 шт. товара это будет уже 10% скидки)
- 2 — неточный поиск текста с использованием подстановочных символов
Если с первыми тремя вариантами тут всё более-менее понятно, то последний стоит прокомментировать дополнительно. Имеется ввиду ситуация, когда мы ищем значение, где помимо букв и цифр использованы подстановочные символы * (звёздочка = любое количество любых символов) и ? (вопросительный знак = один любой символ).
На практике это может использоваться, например, так:
Заметьте, что, например, капуста в прайс-листе и бланке заказа здесь записана по-разному, но ПРОСМОТРX всё равно её находит, т. к. ищем мы уже не просто капусту, а капусту с приклеенными в начале и конце звёздочками и четвёртый аргумент нашей функции равен 2.
к. ищем мы уже не просто капусту, а капусту с приклеенными в начале и конце звёздочками и четвёртый аргумент нашей функции равен 2.
Функция ВПР, кстати говоря, всегда умела такое «из коробки», так что особого преимущества у ПРОСМОТРX здесь нет. Но важен другой нюанс: функция ВПР при включенном приблизительном поиске (последний аргумент =1) строго требовала сортировки искомой таблицы по возрастанию. Новая функция прекрасно ищет ближайшее наибольшее или наименьшее и в неотсортированном списке.
Направление поиска
Если в таблице есть не одно, а несколько совпадений с искомым значением, то функция ВПР всегда выдает первое, т.к. ведёт поиск исключительно сверху-вниз. ПРОСМОТРX может искать и в обратном направлении (снизу-вверх) — за это отвечает последний 6-й её аргумент [режим_поиска]:
Благодаря ему, поиск первого и (главное!) последнего совпадения больше не представляет сложности — различие будет только в значении этого аргумента:
Раньше для поиска последнего совпадения приходилось неслабо шаманить с формулами массива и несколькими вложенными функциями типа ИНДЕКС, НАИБОЛЬШИЙ и т. п.
п.
Резюме
Если вы дочитали до этого места, то выводы, я думаю, уже сделали сами 🙂 На мой взгляд, у Microsoft получилось создать очень достойного наследника легендарной функции ВПР, добавив мощи и красоты и сохранив, при этом, простоту и наглядность использования.
Минус же пока только в том, что эта функция в ближайшее время появится только у подписчиков Office 365. Пользователи standalone-версий Excel 2013, 2016, 2019 эту функцию не получат, пока не обновятся до следующей версии Office (когда она выйдет). Но, рано или поздно, эта замечательная функция появится у большинства пользователей — вот тогда заживём! 🙂
Ссылки по теме
- Как использовать функцию ВПР (VLOOKUP) для поиска и подстановки значений
- Левый ВПР
- Связка функций ИНДЕКС и ПОИСКПОЗ как аналог ВПР
Как использовать ВПР в Google Таблицах
В этой статье вы узнаете больше о том, как работает ВПР в Google Таблицах и как ее использовать, с несколькими полезными примерами.
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Если вы когда-либо использовали функцию ВПР в Excel, то вы знаете, насколько это мощная функция. Если вы не знаете, что делает ВПР в Google Таблицах, она работает так же, как и в Excel.
Функция ВПР позволяет выполнять поиск в крайнем левом столбце диапазона, чтобы вернуть значение из любого другого столбца в том же диапазоне.
В этой статье вы узнаете больше о том, как работает ВПР в Google Таблицах и как ее использовать, с несколькими полезными примерами.
Что такое ВПР в Google Таблицах?
Думайте о ВПР в Google Таблицах как о очень простом поиске в базе данных. Если вам нужна информация из базы данных, вам нужно найти в определенной таблице значение из одного столбца. Какая бы строка ни находила совпадение в этом столбце, вы можете затем найти значение из любого другого столбца в этой строке (или записи в случае базы данных).
Точно так же это работает в Google Таблицах. Функция ВПР имеет четыре параметра, один из которых является необязательным. Эти параметры следующие:
Функция ВПР имеет четыре параметра, один из которых является необязательным. Эти параметры следующие:
- search_key: Это конкретное значение, которое вы ищете. Это может быть строка или число.
- диапазон: Любой диапазон столбцов и ячеек, который вы хотите включить в поиск.
- индекс: Это номер столбца (в выбранном диапазоне), в котором вы хотите получить возвращаемое значение.
- отсортировано (необязательно): если установлено значение ИСТИНА, вы сообщаете функции ВПР, что первый столбец отсортирован.
Об этих параметрах следует помнить несколько важных вещей.
Во-первых, вы можете выбрать диапазон при вводе функции VLOOKUP, когда вы дойдете до параметра «диапазон». Это упрощает задачу, поскольку вам не нужно запоминать правильный синтаксис для определения диапазона.
Во-вторых, «индекс» должен быть от 1 до максимального количества столбцов в выбранном диапазоне. Если вы введете число, превышающее количество столбцов в диапазоне, вы получите сообщение об ошибке.
Использование ВПР в Google Таблицах
Теперь, когда вы понимаете, как работает ВПР, давайте рассмотрим несколько примеров.
Пример 1: простой поиск информации
Допустим, у вас есть список сотрудников и связанные с ними личные данные.
Затем, возможно, у вас есть Google Sheet с зарегистрированными продажами сотрудников. Поскольку вы рассчитываете их комиссионные на основе даты их начала, вам понадобится ВПР, чтобы получить их из поля Дата начала.
Для этого в первом поле «Стаж» вы начнете вводить функцию VLOOKUP, набрав «= VLOOKUP («.
Первое, что вы заметите, это появится окно справки. Если этого не произошло, нажмите синий «?» значок слева от ячейки.
Это окно справки сообщит вам, какой параметр вам нужно ввести дальше. Первый параметр — это search_key, поэтому вам просто нужно выбрать имя сотрудника в столбце A. Это автоматически заполнит функцию с правильным синтаксисом для этой ячейки.
Окно справки исчезнет, но когда вы введете следующую запятую, оно появится снова.
Как видите, он показывает, что следующий параметр, который вам нужно заполнить, — это диапазон, который вы хотите найти. Это будет диапазон поиска данных о сотрудниках на другом листе.
Поэтому выберите вкладку, на которой хранятся данные о сотрудниках, и выделите весь диапазон с данными о сотрудниках. Убедитесь, что поле, в котором вы хотите выполнить поиск, находится в крайнем левом выбранном столбце. В данном случае это «Имя».
Вы заметите небольшое поле с функцией VLOOKUP, и параметры будут плавать над этим листом, пока вы выбираете диапазон. Это позволяет вам увидеть, как диапазон вводится в функцию, когда вы ее выбираете.
Как только вы закончите, просто введите еще одну запятую, чтобы перейти к следующему параметру ВПР. Возможно, вам придется выбрать исходную вкладку, на которой вы были, чтобы вернуться к таблице результатов.
Следующий параметр — это индекс. Мы знаем, что дата начала для сотрудника — это третий столбец в выбранном диапазоне, поэтому вы можете просто ввести 3 для этого параметра.
Введите «FALSE» для отсортировано параметр, поскольку первый столбец не отсортирован. Наконец, введите закрывающую скобку и нажмите Войти.
Теперь вы увидите, что поле заполнено правильной датой начала работы для этого сотрудника.
Заполните остальные поля под ним, и все готово!
Пример 2: извлечение данных из справочной таблицы
В следующем примере мы собираемся создать справочную таблицу буквенных оценок, чтобы получить правильную буквенную оценку для числовой оценки учащегося. Чтобы настроить это, вам просто нужно убедиться, что где-то есть справочная таблица для всех буквенных оценок.
Чтобы найти правильную буквенную оценку в ячейке C2, просто выберите ячейку и введите: «= VLOOKUP (B2, $ E $ 1: $ F $ 6,2, TRUE)»
Вот объяснение того, что означают эти параметры.
- Би 2: Ссылка на числовую оценку теста для поиска
- $ E $ 1: $ F $ 6: Это буквенная таблица оценок с символами доллара, чтобы диапазон не изменился даже при заполнении остальной части столбца.
- 2: Ссылается на второй столбец таблицы поиска — Letter Grade.
- ПРАВДА: Сообщает функции ВПР, что оценки в таблице поиска отсортированы
Просто заполните оставшуюся часть столбца C, и вы увидите, что применяются правильные буквенные оценки.
Как видите, способ, которым это работает с отсортированными диапазонами, заключается в том, что функция ВПР получает результат для меньшего конца отсортированного диапазона. Таким образом, все от 60 до 79 возвращает D, от 80 до 89 возвращает C и так далее.
Пример 3: двусторонний поиск ВПР
Последний пример — использование функции ВПР с вложенной функцией ПОИСКПОЗ. Вариант использования для этого — когда вы хотите искать в таблице разные столбцы или строки.
Например, предположим, что у вас есть та же таблица сотрудников, что и в первом примере выше. Вы хотите создать новый лист, где вы можете просто ввести имя сотрудника и какую информацию о нем вы хотите получить. Третья ячейка затем вернет эту информацию. Звучит круто, правда?
Третья ячейка затем вернет эту информацию. Звучит круто, правда?
Вы можете создать эту таблицу поиска на том же или другом листе. Тебе решать. Просто создайте одну строку для значения поиска в крайнем левом столбце (выбор строки). Создайте еще одну строку для поля, в котором вы хотите найти результат. Это должно выглядеть примерно так.
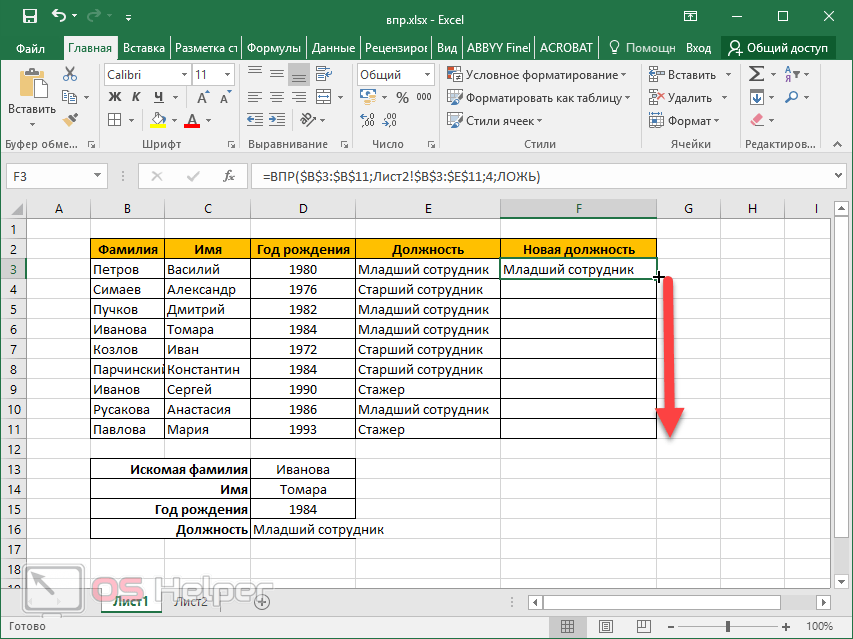
Теперь выберите пустое поле «Результат» и введите «= ВПР (I2, A1: F31, MATCH (I3, A1: F1,0), FALSE)» и нажмите Войти.
Прежде чем смотреть на результаты, давайте разберемся, как работают параметры в этой функции ВПР.
- I2: Это имя, которое вы ввели в поле поиска имени, которое VLOOKUP попытается сопоставить с именем в крайнем левом столбце диапазона.
- A1: F31: Это весь диапазон имен, включая всю связанную информацию.
- ПОИСКПОЗ (I3; A1: F1,0): Функция сопоставления будет использовать введенное вами поле поиска, найдет его в диапазоне заголовков и вернет номер столбца. Этот номер столбца затем передается в параметр индекса функции ВПР.
- ЛОЖНЫЙ: Порядок данных в левом столбце не сортируется.
 Этот номер столбца затем передается в параметр индекса функции ВПР.
Этот номер столбца затем передается в параметр индекса функции ВПР.Теперь, когда вы понимаете, как это работает, давайте посмотрим на результаты.
Как видите, набрав имя и поле для возврата (Электронная почта), вы можете найти любую понравившуюся информацию.
Вы также можете использовать этот подход двустороннего поиска для поиска в любой таблице как по строке, так и по столбцу. Это одно из самых полезных приложений функции ВПР.
Использование ВПР в Google Таблицах
Добавление функции ВПР в Google Таблицы было одной из лучших вещей, которые мог бы сделать Google. Это увеличивает полезность ваших электронных таблиц и позволяет выполнять поиск и даже объединять несколько листов.
Если у вас есть какие-либо проблемы с этой функцией, многие советы по устранению неполадок, которые работают с ВПР в Excel, будут работать и для нее в Google Таблицах.
Как использовать кофеварку Bunn серии VPR для заваривания за 7 шагов
Хотите знать, почему серия Bunn VPR лучшая и как ее использовать? Если ДА, вот простое руководство из 7 шагов по использованию кофеварки Bunn VPR для заваривания. Кофеварка Bunn VPR стала очень популярной как коммерческая кофеварка для небольших офисов по всей стране. Эта конкретная кофеварка является простой, надежной, простой в использовании и достаточно прочной, чтобы варить отличный кофе в течение многих лет.
Кофеварка Bunn VPR стала очень популярной как коммерческая кофеварка для небольших офисов по всей стране. Эта конкретная кофеварка является простой, надежной, простой в использовании и достаточно прочной, чтобы варить отличный кофе в течение многих лет.
Как следует из названия, эта кофеварка производится корпорацией Bunn-O-Matic. Корпорация Bunn-O-Matic была основана в 1957 году и известна тем, что представила первый бумажный фильтр для кофе. Благодаря постоянным инновациям эта компания с годами развивалась и начала производить коммерческое оборудование для напитков, а в последнее время и домашние кофеварки.
Содержание
- Почему BunnVPR — одна из лучших кофеварок
- Первоначальная настройка
- Этапы приготовления кофе
- Очистка
Почему BunnVPR — одна из лучших кофеварок
Кофеварка Bunn VPR имеет 2 подогревателя и может приготовить 8 чашек горячего кофе за час. Резервуар для горячей воды поддерживает идеальную температуру воды для заваривания до тех пор, пока не понадобится кофе. Чтобы начать процесс заваривания, просто налейте воду из кувшина (входит в комплект поставки) во входное отверстие в верхней части кофеварки. VPR варит 64 унции. порция кофе примерно за 3 минуты.
Чтобы начать процесс заваривания, просто налейте воду из кувшина (входит в комплект поставки) во входное отверстие в верхней части кофеварки. VPR варит 64 унции. порция кофе примерно за 3 минуты.
Каждый нагреватель имеет собственный переключатель управления, и его можно выключить, если он не используется. С помощью центрального выключателя питания на задней панели VPR вы можете отключить питание резервуара с горячей водой, если кофеварка не будет использоваться в течение нескольких дней.
Уникальный дизайн Bunn VPR Brewer позволяет устанавливать его заподлицо со стеной. Включите в любую розетку на 120 вольт. Сантехника не нужна. Черные рисунки не размазываются. Гарантийный срок компании на данную кофеварку начинается с момента установки.
BUNN гарантирует, что оборудование изготовлено и не имеет дефектов материалов и изготовления до тех пор, пока оно не будет продано и доставлено покупателям. Гарантия компании не распространяется на какое-либо оборудование, компоненты или детали, которые не были произведены BUNN или на которые, по мнению BUNN, повлияло неправильное использование, небрежное отношение, изменение, неправильная установка или эксплуатация, неправильное техническое обслуживание или ремонт, непериодические очистка и удаление накипи, отказы оборудования, связанные с плохим качеством воды, повреждением или аварией.
Кроме того, гарантия не распространяется на замену элементов, подлежащих нормальному использованию, включая, помимо прочего, заменяемые пользователем детали, такие как уплотнения и прокладки.
Как и было сказано выше, кофеварка BUNN VPR имеет 2 подогревателя и может приготовить 8 чашек горячего кофе за час. Резервуар для горячей воды поддерживает идеальную температуру воды для заваривания до тех пор, пока не понадобится кофе. Однако, чтобы эффективно настроить и использовать кофеварку Bunn серии VPR, прочтите подробные инструкции и следуйте им.
Первоначальная настройка
Во-первых, обратите внимание, что во время начальной настройки кофеварка должна быть отключена от источника питания, за исключением случаев, когда это указано в инструкциях.
- Вставьте пустую воронку в направляющие воронки.
- Поместите пустой дозатор под воронку.
- Откройте откидную крышку в верхней части кофеварки и налейте три кувшина водопроводной воды. Подождите около двух минут между кувшинами, чтобы вода могла стечь в резервуар. Пока в бак поступает третий кувшин с водой, бак наполняется до отказа, а излишки воды вытекают из распылительной головки из воронки в дозатор.
- Когда поток воды из воронки прекратится, вы можете подключить кофеварку к источнику питания и подождать примерно двадцать минут, пока вода в баке не нагреется до нужной температуры. Некоторое количество воды будет капать из воронки в течение этого времени из-за расширения и больше не должно появляться.
- Опорожните дозатор и поставьте его под воронку.
- Откройте откидную крышку в верхней части кофеварки и налейте один кувшин водопроводной воды.
- Когда вода перестанет течь из воронки, дайте воде в баке нагреться до нужной температуры.
- Опорожните диспенсер. Теперь кофеварка готова к использованию в соответствии с приведенными ниже инструкциями по приготовлению кофе.
 Подождите около двух минут между кувшинами, чтобы вода могла стечь в резервуар. Пока в бак поступает третий кувшин с водой, бак наполняется до отказа, а излишки воды вытекают из распылительной головки из воронки в дозатор.
Подождите около двух минут между кувшинами, чтобы вода могла стечь в резервуар. Пока в бак поступает третий кувшин с водой, бак наполняется до отказа, а излишки воды вытекают из распылительной головки из воронки в дозатор. Обратите внимание, что контрольный термостат необходимо отрегулировать в сторону уменьшения, чтобы компенсировать большую высоту. Инструкции см. в руководстве по обслуживанию.
Инструкции см. в руководстве по обслуживанию.
Этапы приготовления кофе
- Вставьте фильтр BUNN® в воронку.
- Насыпьте свежий кофе в фильтр и выровняйте слой молотого кофе, слегка встряхнув его.
- Вставьте воронку в направляющие.
- Поместите пустой дозатор под воронку. Для серии VPR с обогревателями – включите нижний переключатель обогревателя.
- Откройте откидную крышку в верхней части кофеварки и налейте один кувшин водопроводной воды.
- Когда приготовление завершено, просто выбросьте гущу и профильтруйте.
Очистка
- Обратите внимание, что для очистки всех поверхностей оборудования Bunn – O – Matic рекомендуется использовать влажную ткань, смоченную в любом мягком неабразивном жидком моющем средстве.
- Проверьте и очистите распылительную головку. Следите за тем, чтобы отверстия распылительной головки всегда оставались открытыми.
- После снятия распылительной головки полностью вставьте пружину для удаления накипи (прилагается) в трубку распылительной головки. При правильной установке пружина должна быть видна не более чем на два дюйма. Пила назад и вперед пять или шесть раз.
 При правильной установке пружина должна быть видна не более чем на два дюйма. Пила назад и вперед пять или шесть раз.
При правильной установке пружина должна быть видна не более чем на два дюйма. Пила назад и вперед пять или шесть раз.Важно отметить, что в районах с жесткой водой это может потребоваться ежедневно. Это поможет предотвратить проблемы с известью в пивоварне, и это займет меньше минуты.
Заключение
Серия Bunn VPR варит кофе с крепким вкусом без горечи, характерной для некоторых кофемашин. Как и любая другая кофеварка, произведенная Bunn, они делают это с помощью запатентованной системы, которая поддерживает идеальную температуру заваривания в 2000 градусов по Фаренгейту.
Эта кофеварка также оснащена циклом быстрого заваривания, при котором вода подвергается воздействию молотых кофейных зерен в течение оптимального периода времени для идеального вкуса кофе. Кофеварка Bunn также создала идеальное количество турбулентности с помощью своей распылительной головки, чтобы взвесить молотый кофе и равномерно извлечь весь аромат для идеальной чашки кофе.
Что такое VPR и чем он отличается от CVSS? — Блог
В этой серии блогов будет представлено подробное обсуждение рейтинга приоритета уязвимости (VPR) с различных точек зрения. В первой части основное внимание будет уделено отличительным характеристикам VPR, которые делают его более подходящим инструментом для определения приоритетов усилий по исправлению, чем Общая система оценки уязвимостей (CVSS).
Что такое ВПР?
Рейтинг приоритета уязвимостей (VPR), вывод Tenable Predictive Prioritization, помогает организациям повысить эффективность и результативность исправления, оценивая уязвимости на основе уровня серьезности — критического, высокого, среднего и низкого — определяемого двумя компонентами: техническое воздействие и угроза.
Техническое воздействие измеряет воздействие на конфиденциальность, целостность и доступность после эксплуатации уязвимости. Это эквивалентно субоценке влияния CVSSv3. Компонент угрозы отражает как недавнюю, так и потенциальную будущую активность угроз в отношении уязвимости. Некоторыми примерами источников угроз, влияющих на VPR, являются общедоступные доказательства концепции (PoC), отчеты об эксплуатации в социальных сетях, появление кода эксплойта в наборах эксплойтов и фреймворках, упоминания об эксплуатации в даркнете и на хакерских форумах, а также обнаружение хэши вредоносных программ в дикой природе. Такая информация об угрозах играет ключевую роль в определении приоритетности тех уязвимостей, которые представляют наибольший риск для организации.
Некоторыми примерами источников угроз, влияющих на VPR, являются общедоступные доказательства концепции (PoC), отчеты об эксплуатации в социальных сетях, появление кода эксплойта в наборах эксплойтов и фреймворках, упоминания об эксплуатации в даркнете и на хакерских форумах, а также обнаружение хэши вредоносных программ в дикой природе. Такая информация об угрозах играет ключевую роль в определении приоритетности тех уязвимостей, которые представляют наибольший риск для организации.
VPR предназначен для приоритезации уязвимостей.
Платформа CVSS уже давно подвергается критике за ее неспособность эффективно и действенно приоритизировать устранение уязвимостей. В основном это связано с тем, что он был разработан для измерения технической серьезности уязвимостей, а не риска, который они представляют. В отчете, опубликованном Университетом Карнеги-Меллона [CMU2019], указано:
.
Общая система оценки уязвимостей (CVSS) широко используется для определения приоритетов уязвимостей и оценки рисков, несмотря на то, что она предназначена для измерения технической серьезности.

Одной из часто критикуемых проблем при использовании для устранения уязвимостей является большая доля уязвимостей High и Critical в рейтинге CVSS. На момент написания этого сообщения в блоге было более 16 000 уязвимостей с рейтингом 9.0 или выше (по CVSSv2), что составляет 13% всех уязвимостей. CVSSv3, последняя основная версия CVSS, не улучшает эту проблему. CVSSv3 оценил более 60 000 уязвимостей с момента его выпуска в июне 2015 года. Около 9400 уязвимостей CVSSv3 получили оценку 9,0 или выше, что составляет 16% всех уязвимостей CVSSv3. Когда большой процент уязвимостей считается критическими, расстановка приоритетов становится громоздкой.
Рисунок 1. Сравнение распределений уязвимостей CVSSv3 и VPR по рейтингам критичности
VPR разработан для того, чтобы избежать проблем такого типа за счет включения информации об угрозах в свою формулу. На приведенной выше диаграмме сравнивается распределение уязвимостей VPR и CVSSv3. Из-за динамического характера угроз количество Критиков VPR немного меняется каждый день. В среднем в день VPR оценивает около 700 уязвимостей как критические и менее 5000 — как высокие. Эти цифры составляют менее 1% и 4% соответственно от всех уязвимостей. Имея меньше критических уязвимостей, на которых нужно сосредоточиться, группы безопасности могут более эффективно разрабатывать планы устранения уязвимостей.
В среднем в день VPR оценивает около 700 уязвимостей как критические и менее 5000 — как высокие. Эти цифры составляют менее 1% и 4% соответственно от всех уязвимостей. Имея меньше критических уязвимостей, на которых нужно сосредоточиться, группы безопасности могут более эффективно разрабатывать планы устранения уязвимостей.
На этом этапе возникает естественный вопрос об эффективности: сколько опасных уязвимостей может быть обнаружено с помощью VPR? В оставшейся части этого сообщения в блоге будет сравниваться эффективность VPR и CVSSv3 при выявлении опасных уязвимостей. Но сначала мы рассмотрим, как генерируется VPR.
VPR: под капотом
В основе VPR лежат модели машинного обучения, совместно работающие для прогнозирования угроз. В частности, прогноз угроз призван ответить на вопрос: каков соответствующий уровень краткосрочной угрозы для уязвимости на основе последних доступных данных? Чтобы научить модели VPR отвечать на этот вопрос, в нее загружаются исторические данные, полученные из различных источников:
- Каналы информации об угрозах предоставляют информацию об эксплойтах и атаках, связанных с уязвимостями, таких как наблюдения индикаторов компрометации (IoC), ссылки на эксплойты в даркнете, отчеты об эксплойтах в социальных сетях или репозиториях кода и т. д. Они предоставляют VPR информацию о том, какие уязвимости потенциально связаны с эксплуатацией, а какие подвергались активным атакам.
- Репозитории/наборы эксплойтов предоставляют информацию о зрелости кода эксплойтов. Различные уровни зрелости (от PoC до оружия) по-разному влияют на угрозу.
- Репозитории уязвимостей и рекомендации по безопасности содержат внутренние характеристики уязвимости, которые также могут быть связаны с угрозой.
 д. Они предоставляют VPR информацию о том, какие уязвимости потенциально связаны с эксплуатацией, а какие подвергались активным атакам.
д. Они предоставляют VPR информацию о том, какие уязвимости потенциально связаны с эксплуатацией, а какие подвергались активным атакам.В совокупности эти необработанные данные ежедневно передаются в конвейер VPR. Оценка VPR (9,6 в приведенном ниже примере) создается путем объединения прогнозируемой угрозы и воздействия (взятого из оценки воздействия CVSSv3) для каждой уязвимости. Рисунок 2 иллюстрирует этот процесс.
Рис. 2. Трубопровод VPR
Сравнение VPR с CVSS для устранения уязвимостей
Сравнительный анализ показывает, что стратегия исправления, основанная на VPR, может иметь более высокую эффективность, чем подход, основанный на CVSS.
VPR уделяет первоочередное внимание уязвимостям с новыми возможностями эксплуатации
Занятие упреждающей позиции в отношении возникающих угроз может помочь группам безопасности получить временной буфер для защиты своей поверхности атаки. Одним из примеров проактивной защиты является частое сканирование сети и исправление каждой уязвимости, классифицированной как CVSS Critical в окне исправления. Этот подход может привести к высокой эффективности защиты сети, но обычно его трудно реализовать из-за огромного количества уязвимостей, подпадающих под эту категорию.
VPR предназначен для приоритизации уязвимостей с более высокой вероятностью того, что они станут целью злоумышленников в ближайшем будущем, при этом отфильтровывая те, которые считаются менее рискованными. Это прогностический характер VPR. В этот момент кому-то может быть любопытно, как делаются прогнозы. Здесь нет никакой магии! Прогноз VPR основан на простом правиле: эволюция угрозы для уязвимости в дикой природе обычно происходит по той же схеме, что и аналогичные уязвимости в прошлом.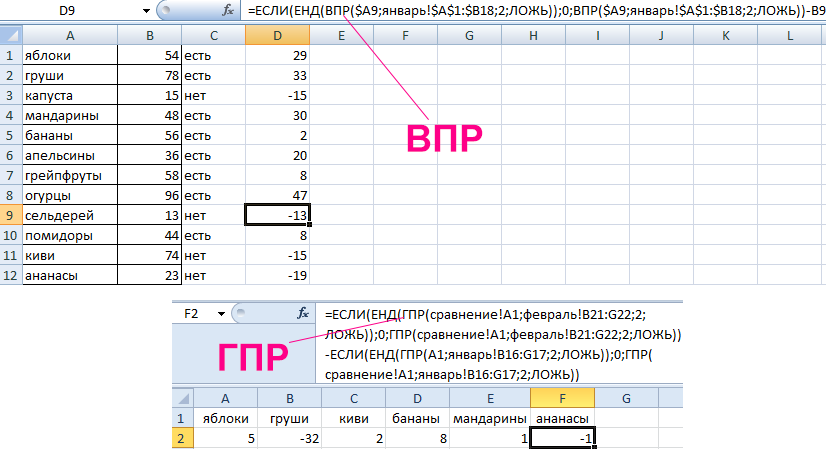
В следующих таблицах показано, что стратегии исправления, разработанные с учетом VPR, могут достичь того же уровня эффективности, что и исправление всех критических ситуаций CVSS с гораздо более высокой эффективностью. Здесь мы используем возможность выявления уязвимостей с помощью IoC в течение следующих 28 дней для сравнения VPR с CVSSv3. IoC — это артефакты, которые часто считаются убедительным свидетельством эксплуатации. Они включают хэши вредоносных программ, IP-адреса, URL-адреса и так далее. Мы получаем IoC от коммерческих поставщиков данных, таких как ReversingLabs и VirusTotal.
Таблица 1. Количество уязвимостей с IoC, обнаруженных в реальных условиях в течение следующих 28 дней для VPR (слева) и CVSSv3 (справа)
False — IoC не обнаружено в течение 28 дней после расчета VPR
True — IoC, обнаруженный в течение 28 дней после расчета VPR
В приведенных выше таблицах сравнивается производительность VPR (слева) с CVSSv3 (справа) для прогнозирования уязвимостей с угрозами в течение следующих 28 дней. Оценки VPR, используемые в этом примере, взяты с января 2020 года, а IoC уязвимостей собираются за 28-дневный период после создания VPR. VPR High и Critical имеют такое же покрытие, как и CVSSv3, для выявления уязвимостей с IoC. Другими словами, обе стратегии охватывают одинаковое количество уязвимостей с реальными IoC в течение следующих четырех недель: 365 из 428 для VPR High и Critical, 376 для CVSS High и Critical.
Оценки VPR, используемые в этом примере, взяты с января 2020 года, а IoC уязвимостей собираются за 28-дневный период после создания VPR. VPR High и Critical имеют такое же покрытие, как и CVSSv3, для выявления уязвимостей с IoC. Другими словами, обе стратегии охватывают одинаковое количество уязвимостей с реальными IoC в течение следующих четырех недель: 365 из 428 для VPR High и Critical, 376 для CVSS High и Critical.
Однако VPR намного эффективнее CVSSv3 в прогнозировании уязвимостей с IoC в течение следующих 28 дней. При сравнении этих двух показателей VPR составляет 26 % Critical и 17 % VPR High по сравнению с 1 % для CVSSv3 Critical и High. Исправление 1500 лучших оценок VPR столь же эффективно, как исправление 33 000 лучших оценок CVSSv3, — примерно в 22 раза эффективнее.
VPR отдает приоритет уязвимостям с известным кодом эксплойта
Наличие очень зрелого кода эксплойта повышает вероятность того, что киберпреступники воспользуются этой уязвимостью в кибератаке. Следовательно, для VPR важно определить приоритет уязвимостей с общедоступным кодом эксплойта. Обратите внимание, что наша классификация зрелости кода эксплойта, используемая в этом анализе, соответствует соглашению CVSS. Таким образом, высокая зрелость означает, что существует функциональный, автономный код эксплойта. Функциональность означает, что код эксплойта используется в качестве оружия, а PoC означает, что код эксплойта теоретически работает. Дополнительные сведения можно найти в спецификациях CVSSv3 [CVSSv3]. Мы получаем код эксплойта из нескольких репозиториев и наборов эксплойтов, таких как Metasploit, Core Impact, Exploit DB, D2 Elliot, Packet Storm, и это лишь некоторые из них.
Следовательно, для VPR важно определить приоритет уязвимостей с общедоступным кодом эксплойта. Обратите внимание, что наша классификация зрелости кода эксплойта, используемая в этом анализе, соответствует соглашению CVSS. Таким образом, высокая зрелость означает, что существует функциональный, автономный код эксплойта. Функциональность означает, что код эксплойта используется в качестве оружия, а PoC означает, что код эксплойта теоретически работает. Дополнительные сведения можно найти в спецификациях CVSSv3 [CVSSv3]. Мы получаем код эксплойта из нескольких репозиториев и наборов эксплойтов, таких как Metasploit, Core Impact, Exploit DB, D2 Elliot, Packet Storm, и это лишь некоторые из них.
На рис. 3 сравнивается доля уязвимостей с известным кодом эксплойта, доступным для VPR и CVSSv3. Более половины критических уязвимостей VPR (54%) имеют общедоступный код эксплойта (т. е. высокий, функциональный и PoC) по сравнению с 15% критических уязвимостей CVSS. Это показывает, что приоритизация уязвимостей с использованием VPR снизит риск, связанный с уязвимостями с кодом эксплойта в Интернете.
Рис. 3. Доля уязвимостей в каждой группе критичности с разбивкой по зрелости кода эксплойта для VPR (вверху) и CVSSv3 (внизу)
Следующий вопрос, который следует задать: какая доля уязвимостей с высоким и функциональным кодом эксплойта захватывается VPR? Другими словами, каково покрытие VPR для уязвимостей с очень зрелым кодом эксплойта? На рис. 4 сравнивается доля критичности VPR и CVSS для всех уровней зрелости кода эксплойта:
- Уязвимости с более высокой степенью зрелости кода эксплойта (высокая и функциональная) в основном захватываются критическими и высокими уязвимостями в VPR. Это похоже на CVSS. Но, учитывая большое количество CVE, которые оцениваются как критические и высокие в CVSSv3, VPR более эффективен для определения приоритетов уязвимостей с известным кодом эксплойта.
- Распределение критичности VPR сильно отличается для уязвимостей с кодом эксплойта с более высокой степенью зрелости (т. Большинство уязвимостей с кодом эксплойта PoC имеют рейтинг Medium VPR. Кроме того, VPR оценивает уязвимости с непроверенным кодом эксплойта как низкий. С другой стороны, CVSSv3 имеет более равномерное распределение по всем уровням зрелости кода эксплойта. С другой стороны, это показывает, что VPR High и Critical сильнее коррелируют с высокой/функциональной зрелостью кода эксплойта, чем CVSS High и Critical.
 Кроме того, VPR оценивает уязвимости с непроверенным кодом эксплойта как низкий. С другой стороны, CVSSv3 имеет более равномерное распределение по всем уровням зрелости кода эксплойта. С другой стороны, это показывает, что VPR High и Critical сильнее коррелируют с высокой/функциональной зрелостью кода эксплойта, чем CVSS High и Critical.
Кроме того, VPR оценивает уязвимости с непроверенным кодом эксплойта как низкий. С другой стороны, CVSSv3 имеет более равномерное распределение по всем уровням зрелости кода эксплойта. С другой стороны, это показывает, что VPR High и Critical сильнее коррелируют с высокой/функциональной зрелостью кода эксплойта, чем CVSS High и Critical.Рисунок 4. Доля уязвимостей в каждом диапазоне зрелости кода эксплойта в разбивке по уровням критичности уязвимости: VPR (вверху) и CVSSv3 (внизу) , но не являются единственным признаком угроз. Еще одним сигналом является активное исследование того, как использовать уязвимость: становится доступным эксплойт-код уязвимости или его зрелость увеличивается.
Таблица 2. Количество уязвимостей с повышенной зрелостью кода эксплойта в течение следующих 28 дней с помощью VPR (вверху) и CVSSv3 (внизу)
переросла в PoC, функциональную или высокую, соответственно, через 28 дней после оценки VPR. Это уязвимости, находящиеся в стадии активного изучения эксплуатации в этот период. Строки в таблицах относятся к критичности уязвимостей. Столбцы относятся к зрелости кода эксплойта. Значения в ячейках представляют количество уязвимостей с расширенным или устаревшим кодом эксплойта за 28 дней после оценки VPR. Например, код эксплойта для четырех уязвимостей с рейтингом VPR Critical будет повышен до высокого уровня зрелости в течение следующих 28 дней. Вот наш анализ:
Строки в таблицах относятся к критичности уязвимостей. Столбцы относятся к зрелости кода эксплойта. Значения в ячейках представляют количество уязвимостей с расширенным или устаревшим кодом эксплойта за 28 дней после оценки VPR. Например, код эксплойта для четырех уязвимостей с рейтингом VPR Critical будет повышен до высокого уровня зрелости в течение следующих 28 дней. Вот наш анализ:
- VPR имеет более высокий процент попаданий, чем CVSSv3, при прогнозировании уязвимостей, для которых зрелость кода эксплойта достигнет высокого уровня в течение 28 дней после оценки VPR. Из восьми уязвимостей в этой категории VPR оценил четыре как критические по сравнению с двумя для CVSS.
- Не все уровни зрелости кода эксплойта одинаково обрабатываются VPR. VPR Critical выделяет уязвимости с более высоким уровнем зрелости:
- 50 % (четыре из восьми) уязвимостей, оцененных как критические для VPR.
- 30% (две из шести) уязвимостей, эскалированных до функциональных, имеют рейтинг VPR Critical.
- Только 4% (одна из 24) уязвимостей, эскалированных до PoC, оцениваются как VPR Critical.
.
- Сравните это с CVSSv3 Critical, который содержит набор уровней зрелости: 25 % для высокого, 50 % для функционального и 21 % для PoC.
- CVSSv3 имеет более высокий охват при обнаружении уязвимостей с эскалацией кода эксплойта: больше уязвимостей с рейтингом CVSSv3 Critical и High имеют более высокую зрелость кода эксплойта, чем VPR Critical и High:
- В общей сложности 31 уязвимости с растущим уровнем зрелости кода эксплойта имеют рейтинг CVSSv3 Critical или High. Среди них эксплойты семи уязвимостей эскалированы до высокой зрелости, четырех до функциональных и 20 до PoC.
- В общей сложности 11 уязвимостям с растущим уровнем зрелости кода эксплойта имеют рейтинг VPR Critical или High. Среди них эксплойты пяти уязвимостей эскалированы до высокой зрелости, двух до функциональных и четырех до PoC.
Таким образом, в обстоятельствах, когда целью является исправление уязвимостей с эскалацией кода эксплойта, хорошей стратегией будет, во-первых, расставить приоритеты на основе VPR Critical, чтобы получить высокий процент попаданий, а во-вторых, CVSS High и Critical, в свою очередь, для увеличения покрытие.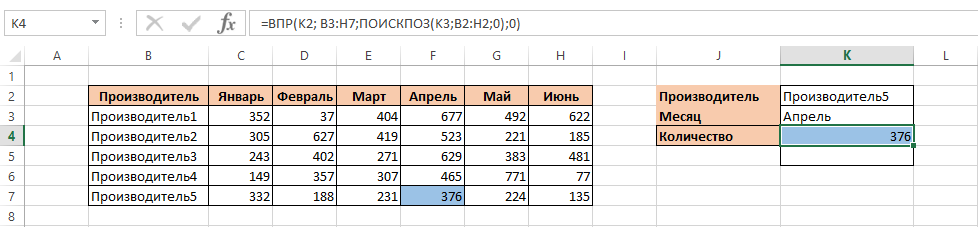
Резюме
В этом посте мы обсудили VPR и то, что делает его чем-то большим, чем просто еще один CVSS. Вкратце:
- VPR предназначен для определения приоритетов устранения уязвимостей. Его формула оценки учитывает как технические характеристики, так и информацию об угрозах.
- VPR более эффективен, чем CVSSv3, при прогнозировании уязвимостей под угрозой:
- Для защиты вашей сети от появляющихся эксплойтов в дикой природе приоритизация уязвимостей на основе ~400 VPR Critical может достичь того же уровня эффективности, что и ~9,000 CVSSv3 Критический.
- Для защиты вашей сети от уязвимостей с известным кодом эксплойта приоритизация уязвимостей на основе ~1500 VPR Critical and High может достичь того же уровня эффективности, что и 33 000 CVSSv3 Critical and High.
- Для защиты вашей сети от уязвимостей с повышением зрелости кода эксплойта сначала отдайте предпочтение критическим уязвимостям VPR, чтобы получить высокий процент попаданий, а затем используйте CVSS High и Critical, чтобы увеличить охват.

