Таблица соответствия gpu и cpu: Таблица совместимости процессор/видеокарты
3DNews Видеокарты Общая информация Заметки на полях. Что быстрее, CPU или G… Самое интересное в новостях Центральные процессоры и видеочипы долгое время занимались решением принципиально разных задач. Но, так или иначе, их «область интересов» стала пересекаться. Существует ли способ сравнить их производительность? И если да, то кто из них быстрее? Время идет, процессоры становятся все мощнее и многоядернее. Видеокарты также наращивают количество вычислительных блоков и помимо создания 3D-изображения пытаются решать те задачи, которыми до сих пор занимались центральные процессоры. При этом разработчики видеокарт обещают значительное повышение производительности, что, в общем-то, подкрепляется цифрами. Но остается вопрос — на самом ли деле архитектура видеокарт лучше подходит для решения хорошо распараллеливаемых задач и потоковой обработки больших массивов данных? Если так, то зачем нам тогда многоядерные процессоры, может действительно стоит «переложить» нагрузку на видеокарты?
Тестовое оборудование
Тестирование
— Обсудить материал в конференции
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER. Материалы по теме Постоянный URL: https://3dnews.ru/580351 Теги: ⇣ Комментарии | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Данный материал не претендует на полноту и всеохватность, более того — рассматриваемые здесь вопросы являются далеко не единственным примером «соревнования» CPU и GPU в области вычислений. Собственно, эти заметки и появились лишь в результате дискуссии с коллегами по поводу «кто сильнее, CPU или GPU». Не откладывая в долгий ящик, решено было проверить, а действительно — кто? Вы не поверите, но итог соревнования оказался не столь очевиден, и результаты удивили обе стороны. А почему так получилось, сейчас и увидим.
Данный материал не претендует на полноту и всеохватность, более того — рассматриваемые здесь вопросы являются далеко не единственным примером «соревнования» CPU и GPU в области вычислений. Собственно, эти заметки и появились лишь в результате дискуссии с коллегами по поводу «кто сильнее, CPU или GPU». Не откладывая в долгий ящик, решено было проверить, а действительно — кто? Вы не поверите, но итог соревнования оказался не столь очевиден, и результаты удивили обе стороны. А почему так получилось, сейчас и увидим.
 Один из них уже довольно стар — Intel Core 2 Quad QX6850. Второй процессор более современный — AMD Phenom II X4 965. Третий еще современнее — AMD Athlon II X4 620. Конечно, надо было бы взять еще Core i7 или Core i5, но в это время они были заняты в других тестах. Впрочем, и трех имеющихся представителей «процессорного «лагеря будет вполне достаточно для получения качественных и количественных оценок.
Один из них уже довольно стар — Intel Core 2 Quad QX6850. Второй процессор более современный — AMD Phenom II X4 965. Третий еще современнее — AMD Athlon II X4 620. Конечно, надо было бы взять еще Core i7 или Core i5, но в это время они были заняты в других тестах. Впрочем, и трех имеющихся представителей «процессорного «лагеря будет вполне достаточно для получения качественных и количественных оценок.

 Данный метод неидеален, но для наших задач его вполне хватит. Кстати, несмотря на то, что процессор Intel Core 2 Quad QX6850 по сути состоит из двух ядер на одной подложке, какого либо влияния в данном тесте это не оказало. То есть, вариант, когда два ядра используют общий кэш объемом 4 Мб и случай, когда каждое из ядер использует кэш по 4 Мб, показали результаты, совпадающие в пределах погрешности. Ну а масштабирование по частоте осуществлялось путем изменения коэффициента умножения процессора в сторону понижения, прочие параметры системы оставались неизменными. Смотрим, что получилось.
Данный метод неидеален, но для наших задач его вполне хватит. Кстати, несмотря на то, что процессор Intel Core 2 Quad QX6850 по сути состоит из двух ядер на одной подложке, какого либо влияния в данном тесте это не оказало. То есть, вариант, когда два ядра используют общий кэш объемом 4 Мб и случай, когда каждое из ядер использует кэш по 4 Мб, показали результаты, совпадающие в пределах погрешности. Ну а масштабирование по частоте осуществлялось путем изменения коэффициента умножения процессора в сторону понижения, прочие параметры системы оставались неизменными. Смотрим, что получилось.

 При увеличении частоты ядер частота L3-кэш процессора остается неизменной, и он может вносить какие-то задержки, поэтому результаты «переходят» на прямую, коэффициент наклона которой ниже.
При увеличении частоты ядер частота L3-кэш процессора остается неизменной, и он может вносить какие-то задержки, поэтому результаты «переходят» на прямую, коэффициент наклона которой ниже.
 001252
001252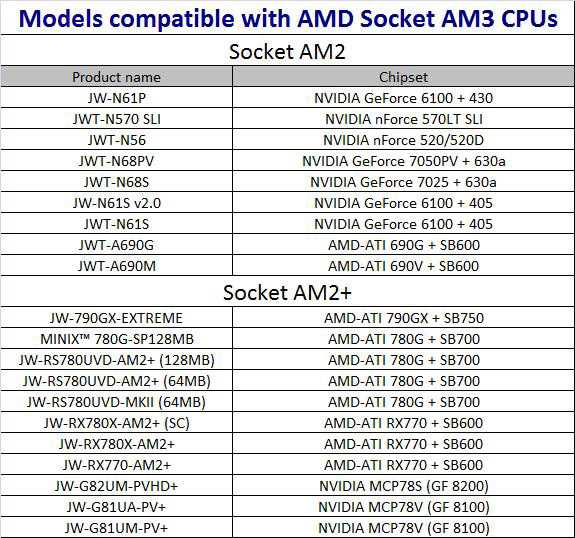 Что касается частоты блоков ROP, то она выбиралась максимально возможной при данной частоте шейдеров. Как оказалось, минимальный коэффициент частоты шейдерных блоков по отношению к частоте ROP-блоков равен двум. Именно такое соотношение частот и сохранялось на протяжении всех тестов.
Что касается частоты блоков ROP, то она выбиралась максимально возможной при данной частоте шейдеров. Как оказалось, минимальный коэффициент частоты шейдерных блоков по отношению к частоте ROP-блоков равен двум. Именно такое соотношение частот и сохранялось на протяжении всех тестов.
 Как оказалось, они сходятся не в начале координат, а пересекают ось ординат на уровне примерно 20 FPS. Странно, не правда ли? Как оказалось, ничего странного нет, а поведение линий вполне закономерно. Для этого достаточно было посмотреть на загрузку CPU во время выполнения теста — она достигала 100% для каждого из ядер. Если вернуться к данным графика №1, то легко заметить, что результат теста на процессоре Intel Core 2 Quad QX6850 @ 3600 МГц как раз и составляет 18 FPS. Мы пробовали снижать частоту процессора и уменьшать количество активных ядер, и каждый раз уровень вертикального смещения линий результатов для GPU с хорошей точностью совпадал с производительностью центрального процессора в данном тесте.
Как оказалось, они сходятся не в начале координат, а пересекают ось ординат на уровне примерно 20 FPS. Странно, не правда ли? Как оказалось, ничего странного нет, а поведение линий вполне закономерно. Для этого достаточно было посмотреть на загрузку CPU во время выполнения теста — она достигала 100% для каждого из ядер. Если вернуться к данным графика №1, то легко заметить, что результат теста на процессоре Intel Core 2 Quad QX6850 @ 3600 МГц как раз и составляет 18 FPS. Мы пробовали снижать частоту процессора и уменьшать количество активных ядер, и каждый раз уровень вертикального смещения линий результатов для GPU с хорошей точностью совпадал с производительностью центрального процессора в данном тесте.
 Как бы там ни было, давайте вычислим «удельную мощность» GPU, используя, как и прежде, коэффициент наклона построенных прямых, поделенный на количество потоковых процессоров. Полученные результаты отображены в таблице ниже. Также в ней указана «удельная мощность» Intel Core 2 Quad QX6850.
Как бы там ни было, давайте вычислим «удельную мощность» GPU, используя, как и прежде, коэффициент наклона построенных прямых, поделенный на количество потоковых процессоров. Полученные результаты отображены в таблице ниже. Также в ней указана «удельная мощность» Intel Core 2 Quad QX6850.
 46
46 Если подсчитать «удельную мощность» новинки, то получаем величину 0.00178 FPS/(МГц*кол-во ядер), что в 1.44 раза больше «удельной мощности» процессора Core 2 Quad QX6850. То есть 44% прибавки достигаются за счет преимуществ архитектуры Core i9 и технологии HyperThreading.
Если подсчитать «удельную мощность» новинки, то получаем величину 0.00178 FPS/(МГц*кол-во ядер), что в 1.44 раза больше «удельной мощности» процессора Core 2 Quad QX6850. То есть 44% прибавки достигаются за счет преимуществ архитектуры Core i9 и технологии HyperThreading.
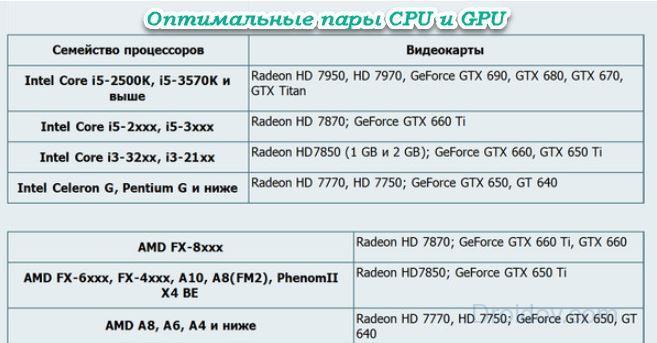
Совместимость процессора и видеокарты — как проверить?
Совместимость компонентов – это основополагающий фактор любого апгрейда компьютера. Особенно остро встает вопрос на совместимость процессора и видеокарты для геймеров. В данном материале вы узнаете, какие роли возложены на CPU и GPU, как проверить совместимость процессора и видеокарты, чтобы отыскать наилучший баланс между ними опираясь на статистику бенчмарков и приобретенные знания.
Особенно остро встает вопрос на совместимость процессора и видеокарты для геймеров. В данном материале вы узнаете, какие роли возложены на CPU и GPU, как проверить совместимость процессора и видеокарты, чтобы отыскать наилучший баланс между ними опираясь на статистику бенчмарков и приобретенные знания.
Совместимость процессора и видеокарты — базовая информация
Для проверки совместимости в дебри работы компонентов лезть не нужно. Важно понимать логику работу отдельных компонентов и всей системы в целом. Кто за что отвечает:
- Центральный процессор (CPU) – отвечает за физику и геометрию. ЦП создает всю ту картинку, которую в последствии отрисовывает видеокарта.
- Видеокарта (GPU) – отвечает за отрисовку картинки (сетка, ланшафт) и все красоты, воспринимающиеся нашими глазами.
- Материнская карта – связующее звено всех элементов компьютера, в том числе CPU и GPU. Чтобы оба компонента успешно могли сосуществовать в одном компьютере, их разъемы должны поддерживаться материнкой.
 Например, одинаковая версия сокета для процессора и одинаковая (желательно) системной шины PCI Express для дискретной видеокарты.
Например, одинаковая версия сокета для процессора и одинаковая (желательно) системной шины PCI Express для дискретной видеокарты.
 Например, одинаковая версия сокета для процессора и одинаковая (желательно) системной шины PCI Express для дискретной видеокарты.
Например, одинаковая версия сокета для процессора и одинаковая (желательно) системной шины PCI Express для дискретной видеокарты.Вернемся к совместимости процессора и видеокарты. Когда ЦП не успевает отрендерить нужное количество кадров (FPS), которые нужны графической карточке, начинается ботлнекинг (bottleneck). То есть один из компонентов системы не дает другому (или другим) компонентам раскрыть весь свой потенциал. Узкое горлышко (перевод bottleneck) демонстрирует показательный пример этому явлению.
При ботлнекинге ЦП загрузка видеокарты может постоянно манятся от 0 до 100%, может не доходить до 100%. Такие поведенческие факторы говорят о том, что процессор не успевает за графической картой.
Или наоборот – процессор довольно мощный, а видеокарта не успевает ним. Это заметить сложнее, потому как явных фризов не будет, а будет попросту низкий FPS. Чтобы как-то стабилизировать ситуацию, следует понижать настройки игры.
Избавит от такого явления проверка совместимости процессора и видеокарты.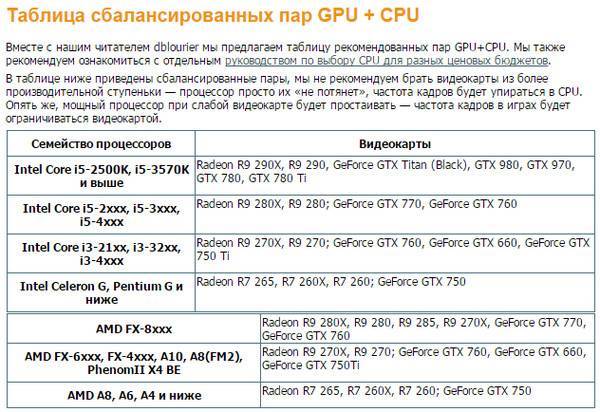
Проверка совместимости процессора и видеокарты
Есть три способа подбора видеокарты под процессор:
- Просмотр характеристик и соответствие между компонентами. Это нужно для того, чтобы выявить, смогут ли вообще сосуществовать CPU и GPU в единой системе.
- Проверка процессора и видеокарты через прогнанный бенчмарк. Сравнение голых цифр чтобы выявить «зеленую зону» для наилучшего баланса.
- Собственный опыт определения в тех играх, которые вы запускаете.
По характеристикам
Современные дискретные карты графики подключаются к материнской плате через слот PCIe версии 3.0. При этом поддержка PCIe должна быть не только у материнской платы, но и у ЦП, иначе могут наблюдаться проблемы стандартного функционирования всего ПК.
В 2019 году ознаменовалась эра поддержки версии PCIe 4.0 с выходом материнских плат X570 Aorus от Gigabite. Теперь на рынке 2020 года можно найти все компоненты (материнка, ЦП, дискретная карта) с поддержкой новой версии слота, с лучшей пропускной способностью. Но цены – кусаются.
Но цены – кусаются.
Если же видеокарта совместно с материнкой поддерживает PCIe 4.0, а процессор только PCIe 3.0 – вся система будет работать с PCIe 3.0. То есть возвращается к тебе ботлнекинга.
В целом сейчас материнские платы создаются под различные модели и различные производители, поэтому ошибиться в дефолтных характеристиках не получится:
1. За совместимость материнки и CPU отвечает сокет. Популярными являются Socket 1050, 1151, 2011, 2066, AM3+, AM4, FM2+.
2. За совместимость GPU отвечает слот PCIe x.
Этой совместимости достаточно для запуска системы.
Совместимость процессора и видеокарты — тесты бенчмарка
Если вы прицениваетесь или у вас на руках уже есть ЦП и дискретная карта, повести проверку на «идеальную пару» поможет PassMark Software. Пользоваться им довольно легко. Исходные данные можно найти в таблице:
- Для видеокарт — https://www.videocardbenchmark.net/gpu_list.php
- Для процессоров — https://www. cpubenchmark.net/cpu_list.php
 cpubenchmark.net/cpu_list.php
cpubenchmark.net/cpu_list.phpИнструкция использования такая:
1. В поисковую строку первой таблицы введите модель графической карты (например GTX 1070).
2. В поисковую строку второй таблицы введите модель процессора (например Intel Core i5 6600K).
3. Сравните оба показателя по рейтингу Passmark. Идеальный баланс достигается при показателях равных или отличающихся друг от друга не более чем на 10%.
4. В данном примере видно, что процессор Intel Core i5 6600K не дает раскрыть весь потенциал графической карты Geforce GTX
5. В зеленой зоне вместе с Geforce GTX 1070 будут ЦП Core i7 6900K, AMD Ryzen 5 2600, Core i9 9900T.
6. В зеленой зоне вместе с Intel Core i5 6600K будут GeForce GTX 1050 Ti, Radeon RX 570.
7. Вторым критерием будет цена. Сравнивайте их перед окончательным выбором.
Мониторинг процессора и видеокарты с помощью простой таблицы с цифрами показал несовместимость выбранных изначально комплектующих и помог подобрать более правильные пары, чем избавил от ботлнекинга.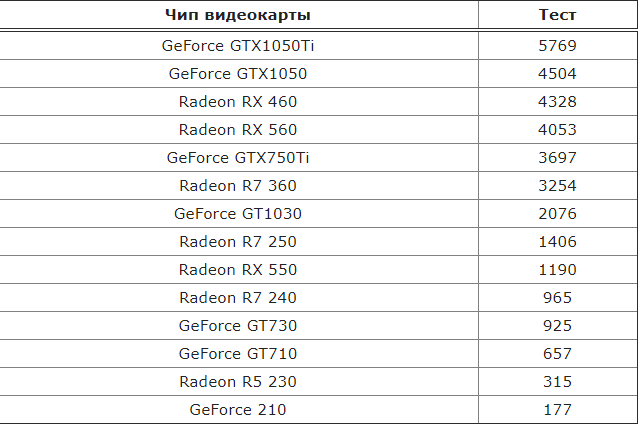
Но правильно ли опираться на голые числа? Не совсем, если у тебя появляется кой какой опыт зависимости одних показателей от других. При этом, в играх или требовательных к ресурсам программах на плечи процессора могут ложится совсем незначительные задачи геометрии, а вот видеокарте приходится тяжко, чтобы нарисовать картинку, которая воспринимается зрительно очень и очень красочно.
При таких обстоятельствах лучше провести тестинг собственноручно.
Совместимость процессора и видеокарты — тестирование своими руками
Если у вас есть один элемент системы (например, ЦП), а вам нужно подобрать правильный второй компонент (например, GPU), следует запустить одну из требовательных игр ААА класса.
Проследить, на что способен процессор можно, снизив настройки в игре все, за которые отвечает видеокарта. Этим вы снимаете нагрузку с графического ядра, чтобы она не была загружена на 100%. После этого вы увидите, какое количество кадров готов отрисовать ваш процессор в той или иной игре. В каждой игре отрисовка будет своя. По большому счету это зависит от движка игры и тех технологий, что используются для нее.
В каждой игре отрисовка будет своя. По большому счету это зависит от движка игры и тех технологий, что используются для нее.
После определения FPS при минимальных настройках графики нужно подбирать под нее видеокарту, которая также сможет обеспечить такой же уровень FPS в игре. Например, если в Ведьмак 3 ЦП покажет 30 FPS, то и видеокарту нужно подбирать 30 FPS. Если же GPU может разогнаться до 60 кадров, процессор просто не сможет успевать за ним и проявится ботлнекинг.
На примере двух игр опытным путем выясните соответствует ли процессор и видеокарта в играх одинаковому фреймрейту.
Для Battlefield One:
1. Зайдите в Настройки графики и снизьте их. За графику отвечает – разрешение экрана, качество графики, трава, постообработка, эффекты. За физику и геометрию в ЦП – ландшафт и сетка.
2. Практически убрав всю графику, был поднят до неплохих показателей кадров 115-150 FPS.
3. Поэтому для процессора Intel Core i5 6600K в данной игре вполне неплохо зайдет Geforce GTX.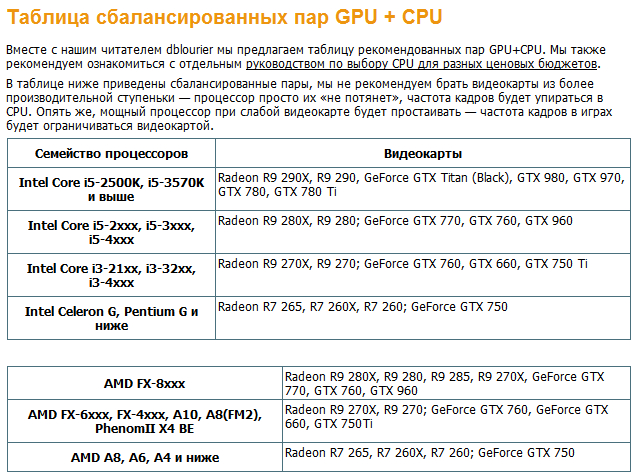
Для Ведьмака 3:
1. Зайдите в настройки графики и выставите низкие показатели графики (HD разрешение и постобработка).
2. За число персонажей на экране и качество рельефа отвечает процессор, поэтому данные показатели оставляйте на максимуме.
3. В Новиграде при множестве NPC тоже показывает довольно большой фреймрейт.
4. При таком показателе тоже можно сделать вывод, что ЦП будет отлично смотреться в паре с GeForce GTX.
Количество выдаваемых FPS тех или иных видеокарт можно посмотреть в бенчмарках по популярных играх. Например, в зарубежном сервисе gpucheck.com.
Совместимость процессора и видеокарты — дополнительная информация
Важно помнить, что CPU и GPU под нагрузкой – это горячие печи, которые нужно должным образом охлаждать. Если это не выполняется, будет падать фреймрейт и должным образом не удастся выявить совместимость процессора и видеокарты.
Температуру CPU и GPU можно узнать с помощью программы AIDA64.
Во время простоя:
- температура ЦП должна быть в пределах 40 градусов;
- температура видеокарты 30-50 градусов.
Под нагрузкой показатель температуры:
- для ЦП равен 70-85 градусов;
- видеокарта 72-84 градуса.
Желательно придерживаться этих пределов, потому как превышение данного температурного режима приводит:
- к тротлингу;
- к лагам и фризам;
- к износу и преждевременному выводу из строя железа.
Определить совместимость процессора и видеокарты можно на уровне совместимости по железу, холодному расчету с помощью бенчмарков или собственной практики в точечно направленной игре или ресурсозависимой программе. Также, при проведении тестов не следует забывать об охлаждении и стараться всегда поддерживать оптимальную температуру в системном блоке ПК.
Выбор количества узлов, процессорных ядер и графических процессоров
ОБЗОР
- Введение
- Время решения
- Серийные коды
- Многопоточные коды
- Многоузловые или параллельные коды MPI
- Гибридный многопоточный многоузловой код
- Коды GPU
- Получение помощи
Прежде чем приступить к выполнению производственных циклов с параллельным кодом на кластерах высокопроизводительных вычислений, вам сначала необходимо найти оптимальное количество узлов, задач, ядер ЦП на задачу и, в некоторых случаях, количество графических процессоров. На этой странице показано, как провести скейлинговый анализ для нахождения оптимальных значений этих параметров для разных типов параллельных кодов.
На этой странице показано, как провести скейлинговый анализ для нахождения оптимальных значений этих параметров для разных типов параллельных кодов.
Когда задание отправляется планировщику Slurm, оно сначала ожидает в очереди, прежде чем будет выполнено на вычислительных узлах. Время, проведенное в очереди, называется временем ожидания. Время, необходимое для выполнения задания на вычислительных узлах, называется временем выполнения.
На рисунке ниже показано, что время ожидания увеличивается с увеличением ресурсов (например, ядер ЦП), а время выполнения уменьшается с увеличением ресурсов. Нужно попытаться найти оптимальный набор ресурсов, который минимизирует «время решения», которое представляет собой сумму времени ожидания и выполнения. Простое правило – выбирать наименьший набор ресурсов, обеспечивающий разумное ускорение по сравнению с базовым случаем.
Обратите внимание, что информация на этой странице относится только к параллельным кодам. Если ваш код не распараллелен, использование большего количества ресурсов не улучшит его производительность. Вместо этого это приведет к пустой трате ресурсов и снизит приоритет вашей следующей работы.
Если ваш код не распараллелен, использование большего количества ресурсов не улучшит его производительность. Вместо этого это приведет к пустой трате ресурсов и снизит приоритет вашей следующей работы.
Не следует пытаться явно вычислить время решения. Это связано с тем, что время ожидания для данной работы сильно различается в зависимости от вашего учебного отдела, вашей справедливой доли, качества обслуживания работы, времени года и т. д. Вместо того, чтобы пытаться оценить время ожидания, просто имейте в виду, что, как правило, чем больше ресурсов вы запрашиваете, тем больше времени ваше задание будет находиться в очереди перед запуском. Время выполнения легко измерить, и оно указывается как «Время работы настенных часов» в отчете по электронной почте Slurm о завершенной работе.
Обратите внимание, что при выполнении анализа масштабирования вам не нужно часами запускать свой код, чтобы получить значимые данные. Однако вам нужно запускать его достаточно долго, чтобы можно было игнорировать однократные операции запуска.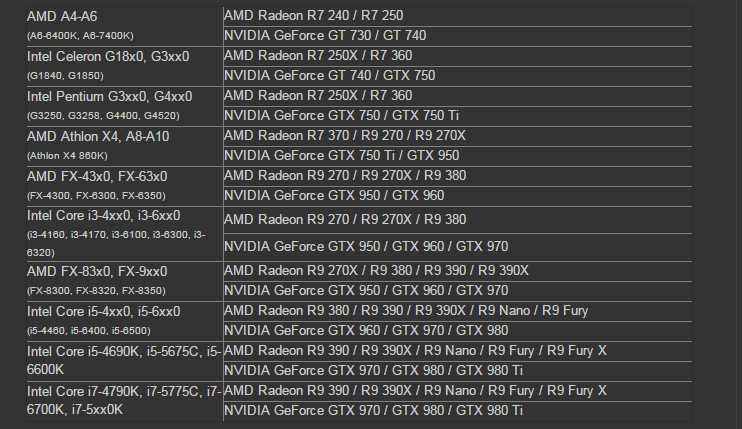 При необходимости добавьте операторы синхронизации в свой код, чтобы измерялись только соответствующие разделы. Обратите внимание, что вы должны работать не менее десятков секунд, чтобы можно было пренебречь неизбежными системными операциями.
При необходимости добавьте операторы синхронизации в свой код, чтобы измерялись только соответствующие разделы. Обратите внимание, что вы должны работать не менее десятков секунд, чтобы можно было пренебречь неизбежными системными операциями.
Ниже мы покажем, как выполнить масштабный анализ для различных типов параллельных кодов. Масштабный анализ позволяет оценить оптимальные значения директив Slurm. Как только что было объяснено, время ожидания в очереди не учитывается при выполнении анализа масштабирования.
Для серийного кода есть только один выбор для директив Slurm:
#SBATCH --nodes=1 #ДОПОЛНИТЕЛЬНО --ntasks=1 #SBATCH --cpus-per-task=1
Использование более одного ядра ЦП для последовательного кода не уменьшит время выполнения, но приведет к пустой трате ресурсов и оставит вас с более низким приоритетом для вашего следующего задания. См. пример сценария Slurm для последовательного задания.
Некоторые программы, такие как процедуры линейной алгебры в NumPy и MATLAB, могут использовать несколько ядер ЦП через библиотеки, которые были написаны с использованием моделей параллельного программирования с общей памятью, таких как OpenMP, Intel Threading Building Blocks (TBB) или pthreads. Для чистых многопоточных кодов можно использовать только один узел и одну задачу (т. е. узлы = 1 и ntasks = 1), и ищется оптимальное значение процессора на задачу:
Для чистых многопоточных кодов можно использовать только один узел и одну задачу (т. е. узлы = 1 и ntasks = 1), и ищется оптимальное значение процессора на задачу:
#ДПАТЧ --nodes=1 #ДОПОЛНИТЕЛЬНО --ntasks=1 #SBATCH --cpus-per-task=
См. пример сценария Slurm для многопоточного задания. Чтобы найти оптимальное значение
| ntasks | процессоров на задачу | время выполнения | Коэффициент ускорения | параллельная эффективность |
|---|---|---|---|---|
| 1 | 1 | 42,0 | 1,0 | 100% |
| 1 | 2 | 22,0 | 1,9 | 95% |
| 1 | 4 | 16,0 | 2,6 | 66% |
| 1 | 8 | 7,8 | 5,4 | 67% |
| 1 | 16 | 6,5 | 6,5 | 40% |
| 1 | 32 | 7,1 | 5,9 | 18% |
В приведенной выше таблице время выполнения – это время, которое потребовалось для выполнения задания (например, настенные часы), а коэффициент ускорения .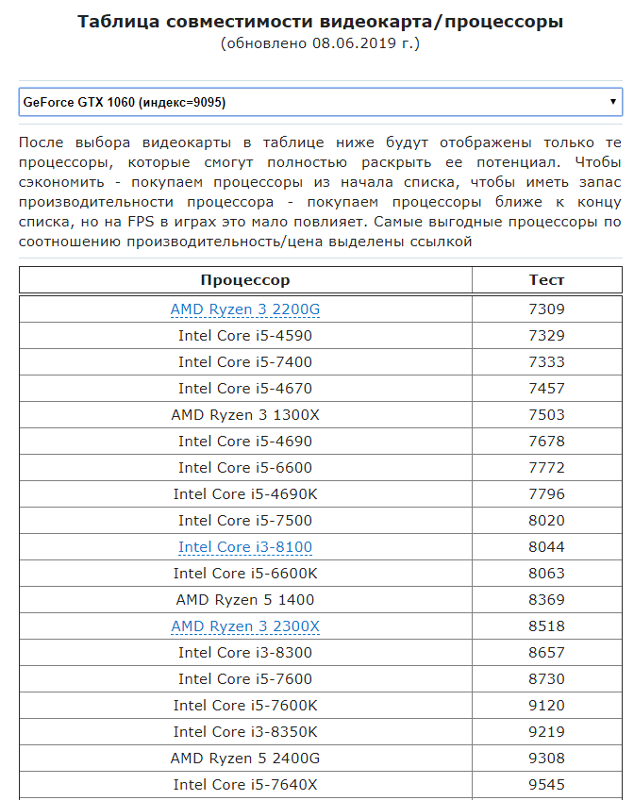 – это время последовательного выполнения (процессор-на-задачу=1), деленное по времени выполнения. Параллельная эффективность измеряется относительно последовательного случая. То есть для cpus-per-task=2 имеем 42,0 / (22,0 × 2) = 0,95. Параллельная эффективность примерно равна «CPU Efficiency» в почтовых отчетах Slurm.
– это время последовательного выполнения (процессор-на-задачу=1), деленное по времени выполнения. Параллельная эффективность измеряется относительно последовательного случая. То есть для cpus-per-task=2 имеем 42,0 / (22,0 × 2) = 0,95. Параллельная эффективность примерно равна «CPU Efficiency» в почтовых отчетах Slurm.
Данные в таблице выше показывают два ключевых момента:
- Время выполнения уменьшается с увеличением числа ядер ЦП до тех пор, пока не будет достигнуто число процессоров на задачу=32, когда код действительно работает медленнее, чем при использовании 16 ядер. Это показывает, что цель состоит не в том, чтобы использовать как можно больше ядер ЦП, а в том, чтобы найти оптимальное значение.
- Оптимальное значение числа процессоров на задачу равно 2, 4 или 8. Параллельная эффективность слишком мала, чтобы учитывать 16 или 32 ядра ЦП.
В этом случае ваш сценарий Slurm может использовать следующие директивы:
#SBATCH --nodes=1 #ДОПОЛНИТЕЛЬНО --ntasks=1 #SBATCH --cpus-per-task=2
Например, для многоузлового кода, использующего MPI, вам потребуется изменить количество узлов и ntasks-per-node. Используйте более 1 узла только в том случае, если параллельная эффективность очень высока при использовании одного узла. Чтобы свести к минимуму время завершения, выберите наименьший набор директив Slurm, обеспечивающий разумное ускорение. Для чистого кода MPI, который не использует многопоточность (например, OpenMP), cpus-per-task=1 и цель состоит в том, чтобы найти оптимальные значения узлов и ntasks-per-node:
Используйте более 1 узла только в том случае, если параллельная эффективность очень высока при использовании одного узла. Чтобы свести к минимуму время завершения, выберите наименьший набор директив Slurm, обеспечивающий разумное ускорение. Для чистого кода MPI, который не использует многопоточность (например, OpenMP), cpus-per-task=1 и цель состоит в том, чтобы найти оптимальные значения узлов и ntasks-per-node:
#SBATCH --nodes=#SBATCH --ntasks-per-node= #SBATCH --cpus-per-task=1
См. полный пример сценария Slurm для задания MPI. Ниже приведен пример анализа масштабирования для параллельного кода MPI:
| узлов | задач на узел | CPU-ядер | выполнение время | ускорение коэффициент | параллельно эффективность |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 1200 | 1,0 | 100% |
| 1 | 2 | 2 | 605 | 2,0 | 99% |
| 1 | 4 | 4 | 306 | 3,9 | 98% |
| 1 | 8 | 8 | 157 | 7,6 | 96% |
| 1 | 16 | 16 | 78 | 15 | 96% |
| 1 | 32 | 32 | 40 | 30 | 94% |
| 2 | 32 | 64 | 21 | 57 | 90% |
| 3 | 32 | 96 | 15 | 80 | 83% |
| 4 | 32 | 128 | 14 | 86 | 67% |
Мы видим, что код работает очень хорошо, пока не используются четыре узла или 128 процессорных ядер. Хорошим выбором, вероятно, будет использование двух узлов, где параллельная эффективность все еще составляет 90%. См. пример сценария Slurm для чистого кода MPI.
Хорошим выбором, вероятно, будет использование двух узлов, где параллельная эффективность все еще составляет 90%. См. пример сценария Slurm для чистого кода MPI.
Некоторые коды используют параллелизм как с общей, так и с распределенной памятью (например, OpenMP и MPI). В этих случаях вам нужно будет варьировать количество узлов, ntasks-per-node и cpus-per-task. Создайте таблицу, как описано выше, но включите новый столбец для процессора на задачу. Обратите внимание, что при использовании полных узлов произведение ntasks-per-node и cpus-per-task должно равняться общему количеству процессорных ядер на узел. Используйте команду «snodes», чтобы найти общее количество ядер ЦП на узел для данного кластера.
Найдите оптимальные значения для этих директив Slurm:
#SBATCH --nodes=#SBATCH --ntasks-per-node= #SBATCH --cpus-per-task=
См. пример сценария Slurm для многопоточного многоузлового задания.
Прежде чем рассматривать несколько графических процессоров, нужно сначала продемонстрировать высокую загрузку графического процессора при использовании одного графического процессора. Посетите страницу GPU Computing, чтобы узнать об измерении и улучшении использования. Если загрузка графического процессора достаточно высока для случая с одним графическим процессором, вам следует изучить возможность использования нескольких графических процессоров, выполнив анализ масштабирования, как показано в таблице ниже:
Посетите страницу GPU Computing, чтобы узнать об измерении и улучшении использования. Если загрузка графического процессора достаточно высока для случая с одним графическим процессором, вам следует изучить возможность использования нескольких графических процессоров, выполнив анализ масштабирования, как показано в таблице ниже:
| узлы | графических процессоров | время выполнения | Коэффициент ускорения | параллельная эффективность |
|---|---|---|---|---|
| 1 | 1 | 212 | 1,0 | 100% |
| 1 | 2 | 140 | 1,5 | 75% |
| 1 | 3 | 110 | 1,9 | 64% |
| 1 | 4 | 105 | 2,0 | 50% |
| 2 | 8 | 145 | 1,5 | 18% |
Приведенный выше анализ масштабирования показывает, что код плохо работает при использовании нескольких графических процессоров. То есть линейного масштабирования не наблюдается. Например, производительность с двумя GPU не в два раза выше, чем с одним. Принимая во внимание, что время ожидания увеличивается с увеличением ресурсов, может не иметь смысла использовать два GPU для этого конкретного кода.
То есть линейного масштабирования не наблюдается. Например, производительность с двумя GPU не в два раза выше, чем с одним. Принимая во внимание, что время ожидания увеличивается с увеличением ресурсов, может не иметь смысла использовать два GPU для этого конкретного кода.
Обратите внимание, что мы не упомянули количество ядер ЦП, используемых в приведенном выше анализе. Это связано с гораздо большей вычислительной мощностью графического процессора по сравнению с многоядерным процессором. Однако для производительности кода с поддержкой графического процессора часто критически важно, чтобы одно или несколько ядер ЦП были полностью задействованы. Например, для кодов глубокого обучения TensorFlow и PyTorch оптимальная производительность может быть достигнута только тогда, когда несколько ядер ЦП используются для загрузки графического процессора путем подачи на него данных.
Многие научные коды используют OpenMP, MPI и графические процессоры. В этом случае ищутся оптимальные значения для узлов, ntasks-per-node, cpus-per-task и gres.
См. пример скрипта Slurm для простого задания GPU.
Получение справки
Если у вас возникнут трудности при проведении анализа масштабирования кластеров HPC, отправьте электронное письмо по адресу [email protected] или посетите сеанс помощи.
Обзор архитектуры графического процессора
· Лучшее завтра с компьютерными науками
исследования
куда
Оглавление
Модель графического процессора №
{: .center-image width:600px}
Это объясняет несколько важных конструкций, принятых в последних графических процессорах.
MMIO .
- Процессор обменивается данными с графическим процессором через MMIO.
- Поддерживаются аппаратные механизмы для DMA для передачи больших объемов данных, однако команды следует писать через MMIO.
- Порты ввода-вывода могут использоваться для косвенного доступа к областям MMIO, но используются редко. Драйвер устройства с открытым исходным кодом Nouveau в настоящее время никогда не использует его.
Контекст графического процессора .
- Контекст представляет состояние вычислений GPU.
- Владеет виртуальным адресным пространством в GPU.
- На графическом процессоре может сосуществовать несколько активных контекстов.
Канал графического процессора .
- Любая операция (например, запуск ядра) управляется командами, исходящими от ЦП.
- Поток команд отправляется аппаратному блоку, называемому каналом GPU.
- Каждый контекст графического процессора может иметь один или несколько каналов графического процессора. Каждый контекст графического процессора содержит дескрипторы канала графического процессора (каждый дескриптор создается как объект памяти в памяти графического процессора).
- Каждый дескриптор канала GPU хранит настройки канала, которые включают таблицу страниц 905:00 .
- Каждый канал графического процессора имеет выделенный буфер команд, выделенный в памяти графического процессора, видимый для ЦП через MMIO.
Таблица страниц графического процессора .
- Контекст GPU назначается с помощью таблицы страниц GPU, которая изолирует виртуальное адресное пространство от других.
- Таблица страниц GPU отделена от таблицы страниц CPU.
- Находится в памяти графического процессора, а его физический адрес указан в дескрипторе канала графического процессора.
- Все команды и программы, отправленные через канал, выполняются в соответствующем виртуальном адресном пространстве графического процессора.
- Таблицы страниц графического процессора преобразуют виртуальный адрес графического процессора не только в физический адрес устройства графического процессора, но и в физический адрес хоста. Это позволяет таблице страниц графического процессора объединить память графического процессора и основную память хоста в единое виртуальное адресное пространство графического процессора .
ШИНА PCIe .
- Регистры базовых адресов (BAR) PCIe, которые работают как окна MMIO, настраиваются во время загрузки графического процессора.
- управляющих регистров графического процессора и апертуры памяти графического процессора отображаются на BAR.
- Эти сопоставленные окна MMIO используются драйвером устройства для настройки графического процессора и доступа к памяти графического процессора.
Двигатель PFIFO .
- PFIFO — это специальный механизм, через который передаются команды графического процессора.
- Поддерживать несколько независимых очередей команд, называемых каналами.
- Очередь команд представляет собой кольцевой буфер с указателями put и get.
- Все обращения к области управления каналом перехватываются механизмом PFIFO для выполнения.
- использует дескриптор канала для хранения настроек связанного канала.
- Nouveau говорит, что механизм PFIFO графического процессора считывает команды из раздела памяти и передает их механизму PGRAPH. (Может это для графики?)
Драйвер графического процессора
Бо
- Nouveau и gdev очень часто используют bo .
- Буферный объект (bo). Блок памяти. Он может хранить текстуру, цель рендеринга, код шейдера и т. д.

 Это позволяет таблице страниц графического процессора объединить память графического процессора и основную память хоста в единое виртуальное адресное пространство графического процессора .
Это позволяет таблице страниц графического процессора объединить память графического процессора и основную память хоста в единое виртуальное адресное пространство графического процессора .
Ссылки #
- Yusuke Suzuki et al. GPUvm: виртуализация графического процессора в гипервизоре» . Транзакции IEEE на компьютерах. 2016
- Hong-Cyuan Hsu et al. G-KVM: полная виртуализация графического процессора на KVM ». Международная конференция IEEE по компьютерным и информационным технологиям. 2016 г.
- Новые термины.