Система legacy: Когда код становится legacy и как с ним жить / Хабр
Содержание
Автоматизация легаси-систем с помощью RPA
Введение
Легаси-системы (унаследованные системы, Legacy Systems) – это устаревшие методы, технологии, вычислительные системы или приложения, которые используются до сих пор. Часто слово «унаследованный» подразумевает, что система задала стандарты для всех последующих.
В теории внедрение новых и удаление устаревших технологий – идеальное решение, но на практике это не так просто. Большинство системных интеграторов и IT-отделов все еще используют устаревшие системы. Они могут корректно работать и приносить прибыль компаниям.
Но такие системы вызывают много проблем из-за сложностей с совместимостью и отсутствия поддержки безопасности, что повышает риски взлома.
К особенностям работы с такими системами также можно отнести:
- Сложности в обслуживании и настройке
- Отсутствие необходимой поддержки и безопасности.
- Проблематичность интеграции с новыми технологиями.
- Слабый UX
Реальность такова, что многие важные бизнес-процессы по-прежнему работают на устаревших системах по всему миру. Если легаси-системы невозможно заменить, то можно попробовать их улучшить. Чаще всего это подразумевает добавление к ним новых систем или повышение продуктивности и безопасности .
Если легаси-системы невозможно заменить, то можно попробовать их улучшить. Чаще всего это подразумевает добавление к ним новых систем или повышение продуктивности и безопасности .
Важность обновления легаси-систем
Устаревшие IT-системы не соответствуют современным требованиям бизнеса. Сейчас важно иметь быстрые приложения, удобную интеграцию и качественный интерфейс, которых как раз часто не хватает легаси-системам. Обновление таких систем может улучшить весь рабочий процесс.
Одна из важнейших причин, по которой системные интеграторы и IT-службы нуждаются в обновлении – это безопасность.
Когда программное обеспечение устаревает, оно становится очень уязвимым для вирусов и злоумышленников из-за того, что предыдущие версии больше не поддерживаются. По данным TechRepublic, 52% организаций по-прежнему используют Windows XP, хотя поддержка прекратилась в 2014 году.
Важность обновления легаси-систем заключается не только в том, чтобы система работала без сбоев. Инструменты и технологии кибербезопасности развиваются и становятся более сложными. Следовательно, отказ от обновления упрощает взлом устаревших систем.
Инструменты и технологии кибербезопасности развиваются и становятся более сложными. Следовательно, отказ от обновления упрощает взлом устаревших систем.
Системные интеграторы имеют дело с большими объемами данных, которые необходимо защитить, поэтому обновление имеет решающее значение.
Использование централизованной платформы, такой как ElectroNeek, для замены и обновления IT-систем даёт множество преимуществ:
- Ускорение подключения новых клиентов, партнёров и приложений.
- Получение доступа к быстрому просмотру транзакций данных.
- Обеспечение непрерывного процесса с соблюдением правил и норм.
- Получение уведомлений в режиме реального времени при возникновении ошибок.
Совмещение RPA-решений с легаси-системами
Одним из наиболее перспективных решений для обновления
легаси-систем являются технологии RPA. Потребности клиентов, конкуренция и рынок постоянно развиваются, и единственный способ не отставать от этого ритма – использовать современные технологии.
С помощью RPA можно постепенно преобразовывать легаси-системы. Основная функция состоит в автоматизации ручных и повторяющихся задач, выполняемых по алгоритму.
Кроме того, роботизированная автоматизация – более гибкий, быстрый и дешевый инструмент, чем многие другие. Глобальный опрос Deloitte показал, что RPA оправдала или превзошла ожидания 85% респондентов.
RPA-решения уже широко распространены и становятся только более эффективными, что делает их очень надежным способом обновления легаси-систем.
Три основных преимущества использования RPA для легаси-систем:
1. Быстрое внедрение: с RPA нет необходимости в кодировании или использовании другого сложного программного обеспечения; это позволяет интеграторам внедрять RPA-решения эффективнее и быстрее, обеспечивая высокий уровень производительности.
2. Низкие затраты на внедрение: использование инструментов RPA не требует значительных материальных или человеческих ресурсов, что выгодно отличает технологию от аналогичных инструментов на рынке. Низкие издержки позволяют системным интеграторам быстрее масштабироваться и быть гибкими при планировании бюджетов.
Низкие издержки позволяют системным интеграторам быстрее масштабироваться и быть гибкими при планировании бюджетов.
3. Отсутствие проблем с безопасностью: RPA обеспечивает максимальную безопасность для системных интеграторов и IT-отделов, позволяя им контролировать авторизацию доступа и управление конфиденциальными данными.
RPA для легаси-систем: примеры использования
Дальше мы рассмотрим несколько примеров использования RPA. Это поможет лучше понять роль технологии в обновлении легаси-систем:
Пример использования #1
Обеспечение продуктивности за счет распознавания задач, готовых к автоматизации в легаси-системах:
Лучше всего автоматизируются рутинные задачи, выполняемые по определённым стандартам и инструкциям. Программные роботы могут выполнять такие задачи быстрее и с минимальным количеством ошибок. ElectroNeek – отличный пример создания и внедрения таких роботов, приносящих результаты без необходимости оплаты лицензии за каждого из них.
Пример использования #2 Интеграция рабочих процессов в легаси-системах:
Чтобы обновить статус клиента во всех системах компании, сотруднику понадобится несколько утомительных часов. И возможно, он допустит ошибки. Благодаря автоматизации это выполняется быстрее и без ошибок, что позволяет сотрудникам сосредоточиться на стратегически важных задачах.
Пример использования #3 Упрощение объединения новых платформ с легаси-системами
Использование традиционных инструментов RPA с машинным обучением позволяет поэтапно обновлять легаси-системы. Такое использование автоматизации снижает издержки и повышает эффективность. Кроме того, использование RPA может помочь легко обнаружить мошенничество, обеспечить более высокий уровень обслуживания клиентов, тем самым увеличив прибыль.
Пример использования #4 Оптимизация работы с данными
Если нужна полная замена легаси-системы, то перенос данных будет затруднен из-за ошибок. RPA-решения предлагают системным интеграторам полный контроль, доступ к данным, когда это необходимо, с безошибочной передачей данных в новую систему.
Программные роботы обеспечивают полную автоматизацию переноса данных из легаси-систем. Каждая единица информации идет туда, куда должна, что делает интеграцию системы беспроблемной. Кроме того, сам процесс происходит очень быстро.
Автоматизация легаси-систем с ElectroNeek
ElectroNeek – это надёжная платформа, предлагающая RPA-решения для обновления легаси-систем. Благодаря уникальной модели ценообразования и качественным роботам, компания является одним из самых востребованных RPA-вендоров.
Компания внедряет программных роботов для автоматизации во всех возможных устаревших средах, включая почтовые сервисы, CRM-системы, финансовые системы и многие другие.
Кроме того, роботы могут переносить данные из легаси-систем во внешние или локальные источники, например, в облачное хранилище или таблицу. Роботы ElectroNeek могут обновлять данные, хранящиеся в легаси-системе, создавать отчеты на основе выполненных задач и сообщать об ошибках при работе с данными в легаси-системах.
Выводы
В статье мы рассмотрели преимущества использования RPA-решений для работы с легаси-системами.
Применение RPA может стать решением, необходимым для вас как для системного интегратора. Чтобы партнёры получили заметное конкурентное преимущество, ElectroNeek предоставляет оптимальные решения для автоматизации. Если вы хотите узнать больше, свяжитесь со специалистами компании.
Как работать с legacy-системами | DOU
На самом деле, по-хорошему статью следовало бы назвать так: «Как работать с legacy-системами и сохранять психическое здоровье». Любой, кто имеет с ними дело, меня поймет. Эта статья — попытка обобщения многолетнего опыта знакомства с legacy-системами в виде набора подходов и практических советов. Примеры буду приводить из собственного опыта — в частности, работы с унаследованной Java-системой.
Кстати, материалов о работе с legacy в структурированном виде почти нет — оба источника, посвященных именно ей, приведены в конце материала. И это при том, что на legacy приходится чуть ли не половина всего аутсорсинга.
И это при том, что на legacy приходится чуть ли не половина всего аутсорсинга.
Особенности legacy
Legacy — в переводе с английского «наследство», и наследственность эта тяжелая. Почти всем доводилось, придя в проект, получить код десятилетней давности, написанный кем-то другим. Это и есть унаследованный код — то есть код исто(е)рический, который часто бывает ужасен настолько, что оказывается вообще непонятно, как с ним работать. И если нам достается legacy-система, то мы, кроме старого кода, также имеем:
— устаревшие технологии;
— неоднородную архитектуру;
— недостаток или даже полное отсутствие документации.
Со всем этим нам нужно разбираться и как-то жить дальше. И тут без хорошего чувства юмора, пожалуй, не обойтись — те, кто воспринимают жизнь слишком серьезно, обычно сбегают сразу же, как только увидят настоящее legacy.
На самом деле, legacy-система — это не так уж страшно, и вот почему: если система жила все эти десять лет и до сих пор работает, значит, какой-то толк от нее есть. Может быть, она приносит хорошие деньги (в отличие от вашего последнего стартапа на новейших технологиях). Кроме того, код такой системы относительно надежен, если он смог так долго выживать в продакшне. Поэтому вносить в него изменения нужно с осторожностью.
Может быть, она приносит хорошие деньги (в отличие от вашего последнего стартапа на новейших технологиях). Кроме того, код такой системы относительно надежен, если он смог так долго выживать в продакшне. Поэтому вносить в него изменения нужно с осторожностью.
Прежде всего, нужно понять две вещи:
1. Мы не можем неуважительно относиться к системе, которая зарабатывает миллионы, или к которой обращаются тысячи людей в день. Как бы плохо она ни была написана, этот отвратительный код дожил до продакшна и работает в режиме 24/7.
2. Раз эта система приносит реальные деньги, работа с ней сопряжена с большой ответственностью. С самого начала ясно, что это не стартап в стол, а то, с чем пользователи будут работать уже завтра. Это подразумевает и очень высокую цену ошибки, причем дело здесь не в претензиях клиента, а в реальном положении вещей.
Какие задачи нам придется решать, работая с такой системой? Во-первых, мы, очевидно, будем разрабатывать новую функциональность, раз система жива, а значит развивается. Во-вторых, мы будем исправлять ошибки, и это тоже очевидно. И наконец, хотя многие предпочитают про это забыть, мы будем заниматься оптимизацией и стабилизацией системы, даже если напрямую такой задачи перед нами в начале проекта никто не ставил.
Во-вторых, мы будем исправлять ошибки, и это тоже очевидно. И наконец, хотя многие предпочитают про это забыть, мы будем заниматься оптимизацией и стабилизацией системы, даже если напрямую такой задачи перед нами в начале проекта никто не ставил.
Обратный инжиниринг
Для успешной работы с унаследованными системами нам придется много пользоваться приемами reverse engineering.
Прежде всего, нужно внимательно читать код, чтобы точно понимать, как именно он работает. Это обязательно — ведь достаточной документации у нас, скорее всего, не будет. Если мы не поймем хода мыслей автора, то будем делать изменения, последствия которых окажутся не вполне предсказуемыми. Чтобы обезопасить себя от этого, нужно вникать еще и в смежный код. И при этом двигаться не только вширь, но и вглубь, докапываясь до самого нутра. Откуда вызывается метод с ошибкой? Откуда вызывается вызывающий его код? В legacy-проекте «call hierarchy» и «type hierarchy» используется чаще, чем что бы то ни было другое.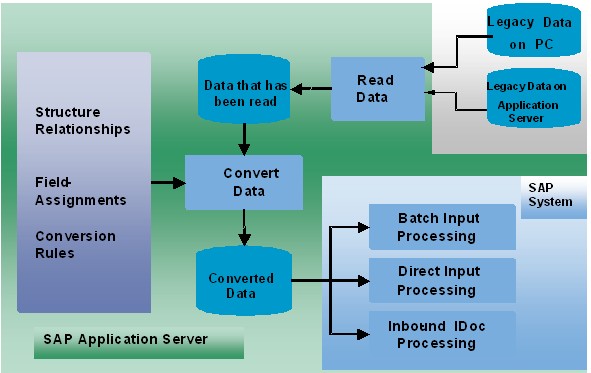
Конечно, придется проводить много времени с отладчиком — во-первых, чтобы находить ошибки, и во-вторых, чтобы понять, как все работает — потому что логика обязательно будет такой, что по-человечески прочитать ее мы не сможем. Собственно говоря, дебажить нужно будет вообще все, в том числе и open source-библиотеки. Даже если проблема где-то в Spring, значит, придется отлаживать и, возможно, пересобирать Spring, если возможности его обновить не окажется. Именно так нам неоднократно приходилось делать, причем не только со Spring.
Что касается документации, не лишним будет прибегнуть к тому, что я бы назвал промышленной археологией. Очень полезно бывает откопать где-нибудь старую документацию и поговорить с теми, кто помнит, как писался доставшийся вам код. Возможно, где-то есть старый Confluence, возможно, хотя бы дамп его базы, где вы что-то, может быть, и найдете. Иногда это бывает проще, чем сидеть с дебаггером. Но нередко там окажутся только документы, не имеющие прямого отношения к коду, например, руководства по настройке серверов, которые все в принципе боятся трогать.
Используя эти приемы, рано или поздно вы начнете более или менее понимать код. Но чтобы ваши усилия не пошли прахом, вы должны обязательно сразу же документировать результаты своих изысканий — для этого я советую рисовать блок-схемы или диаграммы последовательности (sequence diagrams). Конечно, вам будет лень, но делать это точно нужно — через полгода без документации вы сами в этом коде будете копаться как в первый раз. А если через полгода с кодом будете работать уже не вы, ваши последователи будут очень благодарны вам за имеющуюся документацию.
Кстати, зачастую для себя и для бизнеса документацию нужно готовить разную: в вашей, рассчитанной на инженеров, представители бизнеса ничего не поймут. Им потребуется что-то понятное, описывающее функционирование системы на верхнем уровне. И наконец, нужно не забывать самим пользоваться этой документацией и читать ее. Однажды, решив проблему после двух дней героической борьбы, мы обнаружили собственный документ, подробно описывающий точно такой же случай.
Процесс разработки
Итак, что нужно и что не нужно делать:
— Не переписывать. Самое важное здесь — вовремя бить себя по рукам и не пытаться переписать весь код заново. Прикиньте, сколько человеко-лет для этого потребуется — вряд ли заказчик захочет потратить столько денег на переделывание того, что уже и так работает. Это касается не только системы в целом, но и любой ее части. Вам, конечно, могут дать неделю на то, чтобы во всем разобраться, и еще неделю на то, чтобы что-то исправить. Но вряд ли дадут два месяца на написание части системы заново.
Вместо этого реализуйте новый функционал в том же стиле, в каком написан остальной код. Другими словами, если код старый, не стоит поддаваться соблазну использовать новые красивые технологии — такой код потом будет очень тяжело читать. Например, вы можете столкнуться с ситуацией, которая была у нас — часть системы написана на Spring MVC, а часть — на голых сервлетах. И если в части, написанной на сервлетах, нужно дописать еще что-то, то дописываем мы это так же — на сервлетах.
— Соблюдать бизнес-интересы. Нужно всегда помнить, что любые задачи обусловлены прежде всего ценностью для бизнеса. Если вы не докажете заказчику необходимость тех или иных изменений с точки зрения бизнеса, этих изменений не будет. А для того, чтобы убедить заказчика, вы должны попробовать встать на его место и понять его интересы. В частности, если вам хочется провести рефакторинг только потому, что код плохо читается, вам не дадут этого сделать, и с этим нужно смириться. Если совсем уж невмоготу, реорганизовывать код можно по-тихому и понемногу, размазывая работу по бизнес-тикетам. Либо убедить заказчика в том, что это, например, сократит время, необходимое для поиска ошибок, а значит, в конечном итоге сократит расходы.
— Тестировать. Понятно, что тестирование необходимо в любом проекте. Но при работе с legacy-системами тестированию нужно уделять особое внимание еще и потому, что влияние вносимых изменений не всегда предсказуемо. Тестировщиков потребуется не меньше, чем разработчиков, в противном случае у вас должно быть все просто невероятно хорошо с автоматизацией.
В нашем проекте тестирование состояло из следующих фаз:
1. Верификация, когда реализованный функционал фичи проверяется в отдельной ветке.
2. Стабилизация, когда проверяется ветка релиза, в которой все фичи слиты вместе.
3. Сертификация, когда все то же самое прогоняется еще раз на немного других тест-кейсах в сертификационном окружении, максимально приближенном к продакшну по характеристикам железа и конфигурации.
И только после прохождения всех этих трех фаз мы можем делать релиз. Кто-то наверняка считает, что сертификация — лишняя фаза, так как на стадии стабилизации все уже выяснено, но наш опыт говорит о том, что это не так — иногда во время регрессионного теста, который прогоняется по второму кругу на другой машине, что-нибудь да вылезет.
— Формализовать DevOps и релиз. При работе с legacy-системой важно наладить все, что касается DevOps и прочих практик, напрямую не связанных с разработкой. В частности, очень хорошо совместно с девопсами на стороне заказчика прописать определенную процедуру релиза, каждый шаг которой будет строго документирован. Только тогда процесс становится предсказуемым и ясным для каждого из участников.
Релизная процедура может быть, например, следующей. Когда заканчивается разработка и пройдены две или три фазы тестирования, мы пишем письмо DevOps-команде за 36 часов до предполагаемого времени релиза. После этого созваниваемся с девопсами и обсуждаем все изменения окружений (мы сообщаем им обо всех изменениях в БД и конфигурации). На каждое изменение у нас есть документ (тикет в Jira). Затем во время релиза все причастные к этому собираются вместе, и каждый говорит, что он сейчас делает: «Мы залили базу», «Мы перезапустили такие-то серверы», «Мы пошли прогонять регрессионные тесты в рабочем окружении». Если же что-то идет не так, запускается процедура отката релиза, точно описанная в изначальном документе на релиз — без такого документа мы обязательно что-нибудь забудем или напутаем (вспомните, в какое время суток обычно происходят релизы).
— Выстроить branching strategy. Основные модели бренчинга давно описаны на сайте того же Atlassian, их можно адаптировать под ваши нужды. Главное — ни в коем случае не коммитить изменения сразу в транк: должны быть stable trunk и feature branches. Я советую делать релизы из релизных веток, а не из транка. То есть у вас есть транк, от которого отходят ветки на конкретные фичи, соответствующие тикетам в Jira. Когда вы закончили разработку в спринте, вы собираете отдельную релизную ветку из готовых фич и ее сертифицируете. Если же что-то пойдет не так, из такой ветки можно будет легко устранить то, что по какой-то причине из релиза в итоге выпадает. Когда же релиз произошел, релизная ветка вливается в stable trunk.
— Контролировать качество кода. И наконец, code review — это, казалось бы, достаточно очевидная практика, к которой прибегают почему-то далеко не во всех проектах. Очень хорошо, если каждая часть кода проверяется более чем одним человеком. Даже в очень сильной команде в процессе code review обязательно обнаруживаются какие-то косяки, а если смотрят несколько человек, количество выявленных косяков возрастает. Иногда самое страшное находит третий или четвертый reviewer. Но во избежание как саботажа, так и излишнего фанатизма, необходимо договориться, сколько review достаточно для того, чтобы считать фичу готовой.
Для проверки можно использовать пул-реквесты (конечно, если у вас Git), далее есть Crucible и FishEye — оба прикручиваются к Jira. И наконец существует очень удобный инструмент Review Board, который работает и с SVN, и с Git. Он позволяет послать запрос на проверку кода, который соберет в себе все изменения в данном feauture branch.
Управление проектом
Подбор команды. Самое первое, что должен помнить Team Lead или PM при наборе людей в проект — далеко не всем разработчикам подходит работа с legacy-системами. Даже если человек пишет замечательный код, не факт, что он сможет целыми днями сидеть с дебаггером или документировать чужой код. Для работы с legacy, кроме технических навыков, требуются еще определенные личностные качества — хорошее чувство юмора, самоирония и, конечно же, терпение. На эти качества нужно обращать внимание при подборе людей в команду, а если кто-то не сошелся с legacy характерами, то не воевать с ним, а заменять. Замена человека в проекте в подобном случае не волчий билет, а облегчение и для него, и для команды.
Глупые вопросы. Тимлид не должен стесняться задавать команде «глупые» вопросы и напоминать обо всех вышеперечисленных приемах работы. «Я накатил свежий код, и теперь ничего не работает!» — «А какую ветку ты взял? А базу обновил? А что в логах? А дебажил?» Несмотря на всю свою простоту, такие диалоги — неотъемлемый элемент нашей работы, и в особенности с legacy-проектами. Нужно удерживать все в голове и не уставать снова и снова напоминать о каких-то очевидных и не очень очевидных вещах. Без этого, поверьте, не обойтись!
Процесс, или «здесь так принято». В силу американской текучки кадров новые менеджеры со стороны заказчика приходят в проект чаще, чем нам хотелось бы. И многие из них, еще не разобравшись в специфике legacy, пытаются внедрять практики и решения из своего предыдущего опыта. Им нужно терпеливо объяснять, почему здесь принято именно так, а не по книжке. Сначала такие вещи донести бывает трудно, но в конечном итоге либо заказчик согласится с вами, либо вы вместе придете к компромиссному решению.
В работе с legacy-системами действительно важен правильно выстроенный, понятный и прозрачный процесс: Jira (или аналог) обязательно должна отражать реальное положение дел в данный момент. Все требования должны быть ясно сформулированы, а процессы четко прописаны. Вся эта Jira-бюрократия точно окупится, сильно снизив степень энтропии в проекте. Так, когда к вам придет заказчик и потребует срочно сделать новую фичу, вы сможете просто показать заполненное расписание. Тогда он легче сможет понять, что чем-то придется пожертвовать.
Что касается эстимэйта (вы же используете Planning Poker, правда?), то оценивать всегда нужно с запасом, чтобы быть готовым к сюрпризам — как мы уже говорили, влияния в незнакомом нам коде зачастую неясны, и порой может вылезать что-то совершенно неожиданное и в неожиданных местах. Так, у нас в проекте был случай, когда изменения в простом CSS сломали часть бизнес-логики: кто-то поставил в JS проверку на цвет элемента интерфейса.
Бизнес, tech debt и SWAT. При работе с legacy-системами нужно стараться противостоять потоку бизнес-требований, которые заказчик будет вам непрерывно поставлять. Заказчик не всегда осознает риски, связанные со стабильностью системы, поэтому вам придется постоянно о них напоминать. Бороться с этими рисками можно двумя способами: балансированием бизнес и стабилизационных задач в каждом спринте или отдельными стабилизационными проектами. Оптимальным кажется баланс 70 на 30, когда 30% времени каждого спринта вы занимаетесь стабилизацией. Впрочем, заказчик скорее всего не даст вам сделать все, что вы хотите — поэтому записывайте технический долг по мере обнаружения. Из этого tech debt вы будете брать задачи на вышеупомянутые 30%. А может, заказчик согласится на стабилизационный проект, особенно если вы покажете ему tech debt в ответ на вопрос, почему все в очередной раз упало.
Для экстренных случаев я советую иметь SWAT — «группы специального назначения», которые смогут быстро решать непредвиденные проблемы в любое время суток. Ведь если система вдруг завалится, заказчик тут же начнет вам звонить и в 2 часа ночи, и в 4 утра — это мы проверили на своем опыте. Поэтому хорошо бывает договориться, кто в какое время дежурит на случай таких происшествий. Это должны быть быстро соображающие люди, которые могут сидеть допоздна, соответственно, чаще всего, не семейные. Но основная их задача — это все-таки, брейнсторминг днем. В этом есть особый инженерный кайф — в стрессовой ситуации оперативно находить ошибки в чужом коде, понимая, что спасаешь мир в рамках отдельно взятой системы.
Примеры оптимизации
А теперь вкратце расскажу о способах оптимизации, которыми мы пользовались в разное время.
Во-первых, нужно уйти от традиции ежедневных перезапусков, если так было принято в проекте. Однако делать это нужно, конечно, с осторожностью — продолжать проверять логи и следить за всем, что может привести к падению системы, и бороться с этим. У нас была система, которые перезапускалась каждую ночь, так как не могла прожить и двух суток из-за memory и других leaks — теперь же она совершенно стабильно работает от релиза до релиза две-три недели (за редкими исключениями, о которых мы обычно узнаем в 4 утра).
А вот хороший пример того, как делать не нужно. У нас была система, несколько компонентов которой периодически отваливались. Тогда со стороны заказчика пришел девопс и написал скрипты, которые по логам анализируют активность этих компонентов, и если в логе три минуты нет записей, то эти службы перезапускаются. Это, конечно, сработало, но такие вещи должны однажды плохо кончиться.
Очень важный момент — проход по всем логам и составление отдельного эпика. Бывают, конечно, заказчики, которые долго не дают доступа к продакшн-логу. У нас, например, так продолжалось полгода, после чего случился переломный момент, когда нас самих попросили посмотреть логи продакшна. Просмотр затянулся на всю ночь. В системе, работавшей, как считалось, штатно и стабильно, нормальные логи попадались лишь иногда — в основном же записи были со сдвигом вправо и начинались с «at». Это были сплошные стектрейсы, и их набиралось на десятки мегабайт в сутки. Конечно, мы завели эпик в Jira и создали тикеты на отдельные exceptions. Затем нам пришлось несколько месяцев выбивать время на стабилизационный проект. В итоге мы исправили множество ошибок, о которых никто не догадывался, и сделали логи информативными. Теперь любой стектрейс в них — действительно признак нештатной ситуации.
Еще советую обращать внимание на третьесторонние зависимости как на front-end (Google Tag Manager, Adobe Tag Manager и т. п.), так и на back-end. Например, если у нас на странице есть JavaScript со сторонних ресурсов, нужно посмотреть, завернуты ли эти скрипты в try..catch блоки. У нас были случаи, когда сайт падал из-за того, что ломался какой-то скрипт на стороне. Также важно предусматривать возможность недоступности любых внешних ресурсов.
Ну и последнее: следите за всем, за чем только можно, и грамотно агрегируйте логи. Ведь у вас может быть 12 продакшн-серверов, и вас могут попросить их логи посмотреть, что точно нужно делать не через tail. Мы использовали ELK — связку Elastic search — Logstash — Kibana. Очень полезен мониторинг: мы навесили Java Melody на все серверы и получили огромное количество новой информации, на основании которой многое исправили, осчастливив заказчика.
P.S. Полезные ссылки:
— Виктор Полищук: «Legacy Projects. How To Win The Race» — доклад на русском о работе с унаследованными системами, основанный на конкретных примерах из опыта докладчика.
— Michael Feathers: «Working Effectively with Legacy Code» — книга по теме, которую я, честно говоря, не читал. В основном она про рефакторинг. В открытом доступе есть обширная презентация автора с тем же названием, по которой вы сможете понять, стоит ли вам покупать эту книгу.
Все про українське ІТ в Телеграмі — підписуйтеся на канал редакції DOU
Теми:
legacy, аутсорсинг, розробка
Что такое устаревшая система? Проблемы и миграция
Унаследованная система — это старая или устаревшая система, технология или программное приложение, которое продолжает использоваться организацией, поскольку оно по-прежнему выполняет функции, для которых изначально предназначалось. Как правило, устаревшие системы больше не имеют поддержки и обслуживания, и их возможности роста ограничены. Однако их нельзя легко заменить.
Поскольку предприятия постоянно развиваются в связи с изменениями в экономике, новыми законами, рыночной конъюнктурой, управлением, реорганизациями и т. д., 9Системы 0003 со временем устаревают . Чтобы адаптироваться ко всем этим изменениям, ИТ-системы также постоянно развиваются. Это затрудняет для ИТ-менеджеров полное представление о системе, потому что адаптации и обновления часто выполняются разными людьми с течением времени.
Устаревшие системы часто необходимы в организации. Это, несомненно, одна из основных причин, почему устаревшие системы по-прежнему широко используются в компаниях. Таким образом, ИТ-менеджеры должны проанализировать, какие системы компании являются унаследованными и в какой степени их стоит поддерживать . Как правило, устаревшие системы имеют решающее значение для повседневной работы, поэтому их миграция и замена должны быть тщательно оценены и спланированы, чтобы свести к минимуму потенциальные риски.
Типы устаревших систем
Компании могут определить, что они используют устаревшую систему или приложение, оценивая различные аспекты. Поскольку системы могут устареть по разным причинам . Например, потому что поставщик системы прекращает выпуск продукта; которая называется EOL или устаревшей системой с истекшим сроком эксплуатации . Продукт больше не существует и, следовательно, не имеет поддержки. Другие причины, по которым системы также могут устареть, заключаются в том, что они больше не обновляются, они сильно исправлены, их невозможно масштабировать или в компании нет квалифицированного персонала , который знает, как это работает.
Почему до сих пор используются устаревшие системы?
ИТ-системы обычно служат годами, но технологии развиваются с огромной скоростью . Вот почему системы часто устаревают до того, как компании готовы их изменить. Таким образом, компании обычно годами поддерживают устаревшие системы в рабочем состоянии. Вот некоторые из причин, по которым организации продолжают их использовать:
- Они по-прежнему удовлетворяют потребности бизнеса или являются критически важными системами .
- Это старая инвестиция в технологию , которая еще не восстановлена. Поскольку развертывание ИТ-систем компании стоит дорого. Следовательно, организациям необходимо использовать их в течение определенного периода времени, чтобы окупить такие инвестиции.
- Замена устаревшей системы требует вложения ресурсов — денег, времени и персонала — компании не всегда могут предположить.
- Компании не хватает ИТ-навыков для миграции на устаревшую систему.
- Организациям часто не хватает технических спецификаций для создания новой системы с теми же функциями, что и у старой системы. Это часто связано с тем, что системы обычно модифицируются многими людьми в течение их жизни, чтобы адаптировать их к конкретным потребностям бизнеса.

- Организация не желает его заменять.
Каковы некоторые из наиболее сложных аспектов замены старой системы на новую?
Замена и миграция устаревших систем занимает первое место в списке критических элементов в организациях. Замена устаревшей системы является сложной, дорогостоящей и трудоемкой задачей . Вот почему важно оценить ключевые аспекты, такие как: каково состояние устаревшей системы, каковы потребности бизнеса или какие риски приемлемы.
Затраты
Хотя обслуживание устаревшей системы в некоторых случаях может быть дорогостоящим, затраты на ее замену также могут быть высокими. Важно должным образом оценить и спланировать проект миграции, чтобы избежать затрат на запуск . Например, тот факт, что некоторые бизнес-процессы обычно должны быть адаптированы к ИТ-системам, чтобы иметь возможность преодолеть недостатки системы, может привести к значительным затратам и непредсказуемым последствиям.
Технические характеристики
Один из основных рисков замены устаревшей системы заключается в том, что новая система не соответствует потребностям бизнеса. Часто это связано с отсутствием технических характеристик устаревшей системы. Это может привести к ошибкам или изменениям в бизнес-правилах, указанных в программном обеспечении, что может привести к потере некоторых важных данных или функций. В общем, сложно создать новую систему с теми же функциями и функциями, что и устаревшая система. Кроме того, если устаревшая система построена с использованием устаревшего языка программирования или технологии, могут возникнуть трудности с поиском квалифицированных специалистов, которые возглавят миграцию.
Защита данных
Защита данных является ключевым; все данные должны быть правильно перенесены, чтобы избежать потери данных. Таким образом, компании должны обеспечить безопасное извлечение всех данных, обеспечить совместимость между старыми и новыми форматами и выделить время для тестирования и проверки данных.
Пользовательский опыт
Другая проблема, которую часто упускают из виду, это пользовательский опыт . При планировании миграции на новую систему все стороны должны чувствовать себя в той или иной степени вовлеченными. Некоторые устаревшие пользователи могут не захотеть вносить изменения, и их отзывы могут помочь вам развернуть решение, с которым они чувствуют себя более комфортно.
Правильная оценка всех этих аспектов поможет компаниям определить, какой вариант лучше всего подходит для их бизнеса: замена устаревшего программного обеспечения или системы на новое, перенос их в облако или перестройка или улучшение части архитектуры системы.
Каковы основные риски и проблемы сохранения устаревшей системы?
Если устаревшие системы имеют решающее значение для организации, важно время от времени проводить проверки безопасности и производительности . Потому что, несмотря на многочисленные причины для поддержки устаревшей системы, существуют также различные потенциальные риски и проблемы, которые необходимо учитывать.
- Совместимость . Поскольку в ней используются устаревшие технологии, устаревшая система может стать несовместимой с новыми системами или технологиями, которые также важны для бизнеса. В результате отделы, использующие устаревшие системы, могут не воспользоваться всеми функциями, предлагаемыми новыми системами.
- Поддержка . Если поставщик больше не продает систему или программное обеспечение, которые использует ваша компания, и не предлагает их поддержку, маловероятно, что он сможет помочь в случае возникновения проблемы.
- Хранилища данных . Устаревшие системы обычно не предназначены для интеграции с более новыми системами; изоляция данных от других систем.
- Безопасность . Отсутствие поддержки, обновлений или обслуживания, а также факт использования старых протоколов и стандартов безопасности приводит к созданию исправлений, которые могут привести к нарушениям безопасности. Это также может затруднить соблюдение нормативных требований.
- Производительность и производительность . Устаревшие системы со временем становятся все медленнее и медленнее, а это означает, что производительность, эффективность и производительность также могут снижаться.
- Затраты на техническое обслуживание и конкурентоспособность . Поддержание устаревшей системы означает вложение денег в ИТ-ресурс, который рано или поздно необходимо будет заменить.
Миграция устаревших систем в облако
Миграция устаревших систем и приложений в облако стала проще благодаря среде Private Cloud . В отличие от большинства общедоступных облачных решений, частное облако позволяет использовать более конкретные и настраиваемые конфигурации, упрощая миграцию и позволяя при необходимости запускать устаревшие приложения без изменений.
Путем переноса устаревших приложений из локального центра обработки данных в частное облако компании получат выгоду от масштабируемости облачных сред при сохранении пользовательских конфигураций. Кроме того, они смогут оптимизировать расходы. Обычно можно развернуть виртуализированную среду, которая по большей части имитирует исходную среду. Можно даже иметь очень старые операционные системы (Windows XP, Windows 2000) и перейти на приложение Private Cloud, для которого требуются аппаратные ключи — метод, который часто использовался для проверки лицензий приложений.
Миграция данных
Миграция данных необходима при обновлении и миграции устаревшей системы. Чтобы обеспечить успешную миграцию данных, важно:
- Убедитесь, что все существующие данные можно безопасно извлечь.
- Преобразование данных для соответствия новым форматам.
- Очистка данных во избежание потенциальных проблем с качеством (неполные, дублированные или неправильно отформатированные данные).
- Перед загрузкой всех данных в новую систему импортируйте набор данных для проверки на наличие ошибок и гарантии того, что миграция пройдет по плану.
Устаревшие приложения часто являются критически важными для компаний. Таким образом, миграция устаревших систем в облако должна быть должным образом оценена и спланирована. Если вы ищете решение для облачного хостинга для своих устаревших приложений, наши специалисты помогут вам его найти. Не стесняйтесь обращаться к нам за индивидуальным предложением.
Что такое устаревшая система и устаревшее программное обеспечение?
В преддверии третьего квартала 2021 года цифровая трансформация важна как никогда. В настоящее время 70% предприятий имеют стратегию цифровой трансформации, а 55% стартапов уже приняли ее. В разгар пандемии COVID-19 наиболее продвинутые в цифровом отношении организации успешно заполняли технические вакансии (75%). Итак, какими бы удобными ни казались ваши устаревшие системы, пришло время заново изобрести или модернизировать вашу устаревшую систему.
Тем не менее, как вы должны это сделать?
На протяжении веков люди использовали термин «наследство» для обозначения ценных вещей, передаваемых из поколения в поколение. Однако в мире ИТ этот термин имеет негативный оттенок, вызывая в воображении образы устаревших, неэффективных систем, которые изо всех сил пытаются сохранить свою актуальность на цифровом рынке. В эту эпоху ускоренного роста организации обнаруживают, что их когда-то эффективные системы теперь не могут соответствовать их бизнес-целям.
Что такое устаревшая система?
Устаревшие системы определяются как те, которые основаны на старых или устаревших технологиях. Сюда входит не только устаревшее компьютерное оборудование, но и языки программирования и программные приложения, которые больше не могут поддерживать технологические потребности организации. Приведенные ниже критерии служат контрольным списком для определения того, что такое устаревшая система.
- Система, не способная удовлетворить потребности организации в программном обеспечении
- Потребность в персонале с устаревшими технологическими навыками
- Чрезмерные затраты, связанные с обслуживанием
- Значительное снижение производительности системы
- Запретительная модернизация
- Невозможность одновременного обслуживания необходимого количества пользователей
Устаревшее оборудование
операционных систем из-за их ограниченной памяти и вычислительной мощности. Примеры этих компонентов включают следующее:
- Мэйнфрейм-компьютеры
Эти массивные, мощные системы в основном используются крупными организациями, такими как банки, страховые компании, компании, выпускающие кредитные карты, университеты и правительственные учреждения. Высокая стоимость миграции и вероятность перебоев в обслуживании — вот почему многие организации продолжают сохранять свою устаревшую инфраструктуру. - Старые персональные компьютеры .
Компьютеры, использующие старые центральные процессоры (ЦП) с 32-разрядной архитектурой, что ограничивает объем используемой ими памяти. Устаревшие системы, использующие порты до USB, такие как параллельные порты или порты PS/2. Устаревшие системы обработки, такие как Pentium II. - Устаревшее сетевое оборудование
Устаревшие сетевые устройства, которые больше не поддерживают такие стандарты, как 802.11b WiFi.
Что такое устаревшее программное обеспечение?
Устаревшие программные системы также являются причиной дорогостоящих задержек и сбоев. Обслуживание устаревшего программного обеспечения может привести к утечке данных в организациях из-за устаревших мер безопасности, проблем с производительностью и несоблюдения стандартов безопасности. Чтобы точно определить, что такое устаревшее программное обеспечение, рассмотрите следующие условия:
- Старое программное обеспечение поддерживается обновлениями функций, но без исправлений безопасности
- Платформа, несовместимая с новыми системами и драйверами
- Программное обеспечение, не соответствующее последним стандартам
- Программное обеспечение, для работы которого требуются новые обновления
Примеры устаревшего программного обеспечения
- Microsoft Windows 7: Windows 7 официально стала устаревшей операционной системой в январе 2020 года после того, как Microsoft прекратила выпуск обновлений безопасности и ее поддержку. Однако более 100 миллионов машин продолжают работать под управлением этой операционной системы.
- COBOL: Common Business-Oriented Language или COBOL все еще используется спустя 55 лет после его разработки. Сообщается, что 48% предприятий и государственных организаций зависят от этого языка больше, чем от других.
- Снятые с производства продукты Oracle: Программное обеспечение баз данных Oracle, такое как E-Business Suite и Peoplesoft.
Устаревшие системы по сравнению с современными ERP-системами
Корпоративные ресурсные системы (ERP) особенно страдают от устаревших программных и аппаратных компонентов. В то время как компании стремятся сохранить свое конкурентное преимущество, их устаревшие ERP-системы мешают им добиваться постоянного роста и прибыльности. Устаревшие ERP-системы не успевают за развивающимися цепочками поставок и быстрым запуском новых продуктов.
Основное различие между устаревшими ERP-системами и модернизированными системами заключается в их развертывании. В устаревших системах используются локальные компьютеры и серверы, принадлежащие компании. Это приводит к ограничению доступа, поскольку пользователи должны находиться на месте, чтобы использовать систему или любые специализированные программные приложения.
По сути, компании несут единоличную ответственность за поддержку устаревших ERP. Однако для обеспечения безопасности и целостности данных требуются ресурсы, которые могут существенно снизить доход. Кроме того, расширение системы по мере роста компании может быть непомерно затратным.
С другой стороны, модернизированные ERP-системы существуют на платформах «программное обеспечение как услуга» (SasS), что означает, что абонентская плата покрывает все права на программное обеспечение. Таким образом, предприятия могут получить доступ к приложениям в любое время, в любом месте и на любом устройстве.
Поставщик облачных услуг предотвращает несанкционированный доступ к данным с помощью надежных средств шифрования. В отличие от устаревших систем, модернизированные облачные системы обеспечивают масштабируемость и гибкость. Кроме того, любые обновления оборудования или программного обеспечения выполняются провайдером.
Почему предприятия продолжают использовать устаревшие системы?
Несмотря на свою неэффективность и высокую стоимость обслуживания, многие государственные системы по всему миру все еще используют устаревшее программное обеспечение. На самом деле, страны, использующие устаревшие системы, признают, что срок службы программного обеспечения уже истек. В последнее время неспособность государственных серверов по безработице удовлетворять потребности приложений выявила трудности с поддержкой устаревших платформ. Проблема усугублялась нехваткой программистов на COBOL для обслуживания устаревшей локальной инфраструктуры.
Кроме того, в отчете Главного управления отчетности США за июнь 2019 года было указано, что десять важных устаревших систем нуждаются в модернизации. Между тем, многие компании розничной торговли, электронной коммерции и производства по-прежнему полагаются на устаревшие системы. Общие причины отказа от модернизации включают:
- Недостаток финансовых ресурсов для поддержки перехода
- Опасение серьезного нарушения работы бизнеса во время модернизации
- Отсутствие возможности переподготовки персонала и предотвращения задержек в обслуживании
- Огромная перспектива модернизации громоздкой системы
Проблемы, связанные с устаревшими системами на современном рынке
Медицинские учреждения, в частности, часто не решаются модернизировать из-за возможности дорогостоящих перерывов, которые могут повлиять на лечение пациентов. Исследование ProPublica, проведенное в 2019 году, показало, что унаследованные системы здравоохранения ставят под угрозу медицинские данные более пяти миллионов пациентов, поскольку их можно легко взломать в Интернете.
Представитель Министерства здравоохранения и социальных служб США признает, что учреждения применяют «лейкопластыри» в попытке предотвратить разрушительные утечки данных.
Недавний взлом колониальной трубопроводной системы, выведший из строя критически важный топливный трубопровод, представляет собой еще один яркий пример проблем, с которыми сталкиваются устаревшие системы. Дорогостоящее нарушение, вызванное взломом программы-вымогателя, привело к тому, что компании пришлось заплатить выкуп в размере 5 миллионов долларов, чтобы перезапустить систему.
Хотя эти компании предпочитают оставаться с устаревшими системами, риски будут по-прежнему влиять на их прибыль, делая модернизацию устаревших систем неизбежным выбором в будущем.
Планирование преобразования устаревшей системы
Исследовательская фирма Gartner подробно описывает, как организациям следует разработать план преобразования в трехэтапном процессе оценки.
- Оцените архитектуру, функциональность, сложность и риски устаревшей системы. Приложения, которые больше не представляют ценности для компании, не могут идти в ногу с потребностями цифрового бизнеса и слишком дороги в обслуживании, являются кандидатами на модернизацию.
- Оценить варианты процесса модернизации. К ним относятся расширение функций приложений в виде API-интерфейсов, повторное размещение в других инфраструктурах, миграция на новые платформы среды выполнения, реструктуризация и оптимизация кода, а также полное переписывание или замена приложений.
- Выберите вариант модернизации, который принесет наибольшую пользу компании с точки зрения архитектуры, функциональности и стоимости.
Что нужно для модернизации устаревшей системы
Предприятиям, решившим модернизировать свои устаревшие системы, следует обращаться к надежным поставщикам, предлагающим услуги по модернизации приложений. В этом процессе используются следующие этапы:
- Оценка текущей устаревшей системы для определения компонентов, которые следует исключить.
- Оценка целей проекта и требований к ресурсам, включая исходный код приложения и этапы преобразования данных.
- Переписывание и реструктуризация приложений, а также переподготовка персонала.
- Внедрение модернизированного приложения с проверкой функциональности, масштабируемости и надежности.
Основные тенденции модернизации устаревших систем
Помимо миграции в облако, важными инструментами для модернизации устаревших систем и повышения операционной эффективности организации являются:
- Автоматизация
Устаревшие системы часто не имеют автоматизации во многих областях. Автоматизируя повторяющиеся задачи, можно исключить человеческие ошибки и эксплуатационные расходы. - DevOps
Консультанты и инженеры DevOps могут помочь в выборе наиболее эффективных услуг для использования. Подход DevOps к программированию приводит к увеличению рентабельности инвестиций и сокращению времени доставки. - Приложения на основе контейнеров
Использование контейнеров в процессе миграции позволяет легко перемещать приложения между инфраструктурами с минимальными изменениями кода. - Архитектура микрослужб
В этом подходе для каждой службы используются отдельные кодовые базы. Это позволяет развертывать службу без затрат на перестройку всего приложения.
Работайте с Entrance Consulting для модернизации вашей устаревшей системы
Устаревшие системы, которые до сих пор используются многими государственными и частными организациями, сопряжены со значительными затратами на обслуживание и представляют повышенный риск для безопасности. Это стало очевидным из-за узких мест, наблюдаемых в государственных системах безработицы, а также из-за остановки колониального топливного трубопровода.
По мере того, как цифровая трансформация продолжает ускоряться во всех отраслях, предприятия должны идти в ногу со временем, чтобы не столкнуться с растущими затратами из-за замедления работы. К счастью, существует несколько подходов к модернизации устаревших систем, которые приведут к большей эффективности и рентабельности.
