Где хранить данные c: c++ — Способы хранения данных в С++
Содержание
python — В каком формате хранить данные?
Вопрос задан
Изменён
2 года 1 месяц назад
Просмотрен
1k раз
Xочу провести небольшое исследование на тему трудности/легкости произношения последовательности из трех согласных. Для этого, я сделал скрипт, который генерирует случайный набор из 5 букв, спрашивает пользователя, насколько сложно ему было произнести слово, а затем печатает небольшую таблицу с данными следующего вида:
В каком формате и в какой форме будет лучше всего сохранить эти данные так, чтобы потом было легко и удобно все это дело извлекать и смотреть на возможные корреляции?
- python
- анализ-данных
- хранение-данных
- обработка-данных
3
Обрабатывать табличные данные удобнее всего в Pandas.
Pandas умеет работать со многими форматами хранения данных, но выбор лучшего формата зависит от многих параметров.
Например если вы часто работаете с типами данных данных, которые Pandas не умеет парсить неявно, например с date, datetime, interval, bool, etc. то такие данные лучше хранить в бинарных форматах (смотрите ниже) или в БД, чтобы избежать повторного парсинга указанных выше типов данных.
Вот осоновные форматы хранения данных, которые поддерживаются в Pandas и их плюсы и минусы:
Python Pickle- плюсы:
- быстрое чтение & запись
- данные хранятся с нужными типами данных — не нужно их повторно парсить
- минусы:
- может быть несовместимо с новыми версиями Python/Pandas
- работать с этим форматом данных можно только в Python
- плюсы:
CSV,TSV,fixed-width format- плюсы:
- совместимость — можно работать с любым ЯП / БД
- легкость работы и обработки (можно использовать утилиты командной строки и текстовые редакторы)
- минусы:
- необходимость каждый раз парсить данные, чтобы распознать числа и строки.
 Столбцы с датами нужно явно указывать при парсинге.
Столбцы с датами нужно явно указывать при парсинге. - медленное чтение и запись
- нет поддержки быстрых кодеков сжатия (поддерживаются: ‘gzip’, ‘bz2’, ‘zip’, ‘xz’)
- необходимость каждый раз парсить данные, чтобы распознать числа и строки.
- плюсы:
Excel- плюсы:
- удобно вручную проверять / редактировать данные в Excel
- совместимость: многие сторонние ЯП и БД поддерживают работу с Excel файлами
- можно красиво оформить данные — заморозить имена столбцов, добавить автофильтры и т.д.
- минусы:
- часто даты и время парсятся неправильно
- максимальное число строк: 1,048,576 — для серъезных проектов этого слишком мало
- очень медленная запись, не очень быстрое чтение
- невозможно эффективно читать/писать данные по частям/кускам
- плюсы:
HDF5- плюсы:
- хранение данных в бинарном виде. Ттип данных при этом запоминается и не нужно повторно парсить такие данные
- очень быстрое чтение и запись
- данные хранятся с нужными типами данных — не нужно их повторно парсить
- поддержка быстрого кодека сжатия
BLOSC - поддержка индексирования многих столбцов
- возможность поиска по индексам — т. е. можно фильтровать данные, не читая весь датасет в память
- совместимость: (C, C++, Java, Python, C# and Fortran)
- минусы:
- мне неизвестны
- плюсы:
Parquet- плюсы:
- самый быстрый из перечисленных форматов
- основан на Apache Arrow — быстро и активно развивается
- данные хранятся с нужными типами данных — не нужно их повторно парсить
- поддержка одного из самых быстрых кодеков сжатия —
snappy - совместимость: (C++, Java, Python, PHP)
- поддержка партиционирования данных
- минусы:
- невозможность дописывать данные в существующий Parquet файл из Pandas — единственный серъезный минус данного формата. Надеюсь его скоро устранят.
- формат достаточно молодой, поэтому иногда не хватает некоторых фич или некоторые
фичи быстро устаревают (deprecated)
- плюсы:
SQL DB(используяSQLAlchemyв качестве прослойки)- плюсы:
- все те плюсы, которые дает нам используемая СУБД
- читать данные можно используя SQL — т. е. мы можем легко фильтровать данные, обхединять данные из многих таблиц и т.д.
- данные хранятся с нужными типами данных — не нужно их повторно парсить
- минусы:
- для некоторых БД при сохранении столбцов со строками, Pandas сохранят их с типом CLOB, что обычно очень медленно работает. Решается при помощи параметра
df.to_sql(..., dtypes={...})
- для некоторых БД при сохранении столбцов со строками, Pandas сохранят их с типом CLOB, что обычно очень медленно работает. Решается при помощи параметра
- плюсы:
Google BigQuery- плюсы:
- все плюсы, которые дает нам
Google BigQuery - To Be Done…
- все плюсы, которые дает нам
- минусы:
- To Be Done…
- плюсы:
Amazon S3- плюсы:
- все плюсы, которые дает нам
Amazon S3 - To Be Done…
- все плюсы, которые дает нам
- минусы:
- To Be Done…
- плюсы:
ORC- плюсы:
- To Be Done…
- минусы:
- To Be Done…
- плюсы:
Stata- плюсы:
- To Be Done. ..
- To Be Done.
- минусы:
- To Be Done…
- плюсы:
 Столбцы с датами нужно явно указывать при парсинге.
Столбцы с датами нужно явно указывать при парсинге. е. можно фильтровать данные, не читая весь датасет в память
е. можно фильтровать данные, не читая весь датасет в память е. мы можем легко фильтровать данные, обхединять данные из многих таблиц и т.д.
е. мы можем легко фильтровать данные, обхединять данные из многих таблиц и т.д. ..
..
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Хранение данных.
 Или что такое NAS, SAN и прочие умные сокращения простыми словами / Хабр
Или что такое NAS, SAN и прочие умные сокращения простыми словами / Хабр
TL;DR: Вводная статья с описанием разных вариантов хранения данных. Будут рассмотрены принципы, описаны преимущества и недостатки, а также предпочтительные варианты использования.
Зачем это все?
Хранение данных — одно из важнейших направлений развития компьютеров, возникшее после появления энергонезависимых запоминающих устройств. Системы хранения данных разных масштабов применяются повсеместно: в банках, магазинах, предприятиях. По мере роста требований к хранимым данным растет сложность хранилищ данных.
Надежно хранить данные в больших объемах, а также выдерживать отказы физических носителей — весьма интересная и сложная инженерная задача.
Хранение данных
Под хранением обычно понимают запись данных на некоторые накопители данных, с целью их (данных) дальнейшего использования. Опустим исторические варианты организации хранения, рассмотрим подробнее классификацию систем хранения по разным критериям.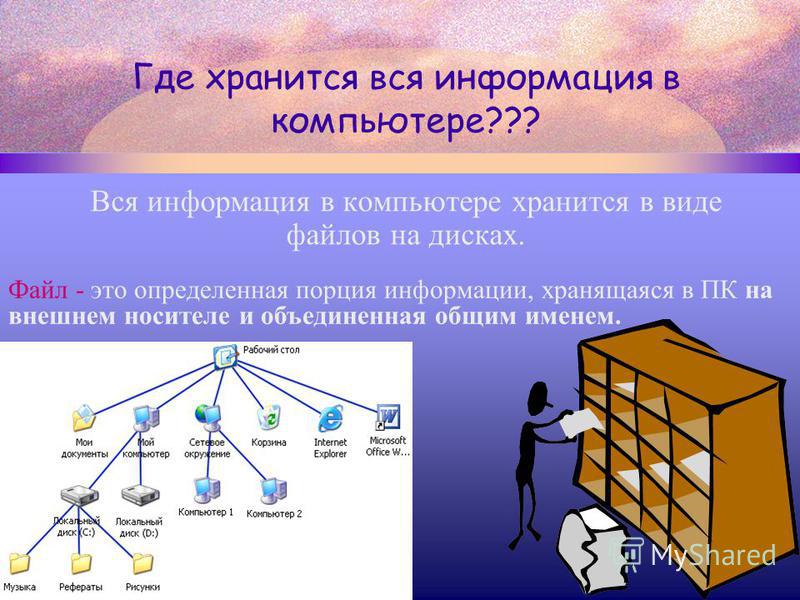 Я выбрал следующие критерии для классификации: по способу подключения, по типу используемых носителей, по форме хранения данных, по реализации.
Я выбрал следующие критерии для классификации: по способу подключения, по типу используемых носителей, по форме хранения данных, по реализации.
По способу подключения есть следующие варианты:
- Внутреннее. Сюда относятся классическое подключение дисков в компьютерах, накопители данных устанавливаются непосредственно в том же корпусе, где и будут использоваться. Типовые шины для подключения — SATA, SAS, из устаревших — IDE, SCSI.
подключение дисков в сервере
- Внешнее. Подразумевается подключение накопителей с использованием некоторой внешней шины, например FC, SAS, IB, либо с использованием высокоскоростных сетевых карт.
дисковая полка, подключаемая по FC
По типу используемых накопителей возможно выделить:
- Дисковые. Предельно простой и вероятно наиболее распространенный вариант до сих пор, в качестве накопителей используются жесткие диски
- Ленточные. В качестве накопителей используются запоминающие устройства с носителем на магнитной ленте. Наиболее частое применение — организация резервного копирования.
- Flash. В качестве накопителей применяются твердотельные диски, они же SSD. Наиболее перспективный и быстрый способ организации хранилищ, по емкости SSD уже фактически сравнялись с жесткими дисками (местами и более емкие). Однако по стоимости хранения они все еще дороже.
- Гибридные. Совмещающие в одной системе как жесткие диски, так и SSD. Являются промежуточным вариантом, совмещающим достоинства и недостатки дисковых и flash хранилищ.
 Наиболее частое применение — организация резервного копирования.
Наиболее частое применение — организация резервного копирования.
Если рассматривать форму хранения данных, то явно выделяются следующие:
- Файлы (именованные области данных). Наиболее популярный тип хранения данных — структура подразумевает хранение данных, одинаковое для пользователя и для накопителя.
- Блоки. Одинаковые по размеру области, при этом структура данных задается пользователем. Характерной особенностью является оптимизация скорости доступа за счет отсутствия слоя преобразования блоки-файлы, присутствующего в предыдущем способе.
- Объекты. Данные хранятся в плоской файловой структуре в виде объектов с метаданными.

По реализации достаточно сложно провести четкие границы, однако можно отметить:
- аппаратные, например RAID и HBA контроллеры, специализированные СХД.
RAID контроллер от компании Fujitsu
- Программные. Например реализации RAID, включая файловые системы (например, BtrFS), специализированные сетевые файловые системы (NFS) и протоколы (iSCSI), а также SDS
пример организации LVM с шифрованием и избыточностью в виртуальной машине Linux в облаке Azure
Давайте рассмотрим более детально некоторые технологии, их достоинства и недостатки.
DAS
Direct Attached Storage — это исторически первый вариант подключения носителей, применяемый до сих пор. Накопитель, с точки зрения компьютера, в котором он установлен, используется монопольно, обращение с накопителем происходит поблочно, обеспечивая максимальную скорость обмена данными с накопителем с минимальными задержками. Также это наиболее дешевый вариант организации системы хранения данных, однако не лишенный своих недостатков. К примеру если нужно организовать хранение данных предприятия на нескольких серверах, то такой способ организации не позволяет совместное использование дисков разных серверов между собой, так что система хранения данных будет не оптимальной: некоторые сервера будут испытывать недостаток дискового пространства, другие же — не будут полностью его утилизировать:
Также это наиболее дешевый вариант организации системы хранения данных, однако не лишенный своих недостатков. К примеру если нужно организовать хранение данных предприятия на нескольких серверах, то такой способ организации не позволяет совместное использование дисков разных серверов между собой, так что система хранения данных будет не оптимальной: некоторые сервера будут испытывать недостаток дискового пространства, другие же — не будут полностью его утилизировать:
Конфигурации систем с единственным накопителем применяются чаще всего для нетребовательных нагрузок, обычно для домашнего применения. Для профессиональных целей, а также промышленного применения чаще всего используется несколько накопителей, объединенных в RAID-массив программно, либо с помощью аппаратной карты RAID для достижения отказоустойчивости и\или более высокой скорости работы, чем единичный накопитель. Также есть возможность организации кэширования наиболее часто используемых данных на более быстром, но менее емком твердотельном накопителе для достижения и большой емкости и большой скорости работы дисковой подсистемы компьютера.
SAN
Storage area network, она же сеть хранения данных, является технологией организации системы хранения данных с использованием выделенной сети, позволяя таким образом подключать диски к серверам с использованием специализированного оборудования. Так решается вопрос с утилизацией дискового пространства серверами, а также устраняются точки отказа, неизбежно присутствующие в системах хранения данных на основе DAS. Сеть хранения данных чаще всего использует технологию Fibre Channel, однако явной привязки к технологии передачи данных — нет. Накопители используются в блочном режиме, для общения с накопителями используются протоколы SCSI и NVMe, инкапсулируемые в кадры FC, либо в стандартные пакеты TCP, например в случае использования SAN на основе iSCSI.
Давайте разберем более детально устройство SAN, для этого логически разделим ее на две важных части, сервера с HBA и дисковые полки, как оконечные устройства, а также коммутаторы (в больших системах — маршрутизаторы) и кабели, как средства построения сети. HBA — специализированный контроллер, размещаемый в сервере, подключаемом к SAN. Через этот контроллер сервер будет «видеть» диски, размещаемые в дисковых полках. Сервера и дисковые полки не обязательно должны размещаться рядом, хотя для достижения высокой производительности и малых задержек это рекомендуется. Сервера и полки подключаются к коммутатору, который организует общую среду передачи данных. Коммутаторы могут также соединяться с собой с помощью межкоммутаторных соединений, совокупность всех коммутаторов и их соединений называется фабрикой. Есть разные варианты реализации фабрики, я не буду тут останавливаться подробно. Для отказоустойчивости рекомендуется подключать минимум две фабрики к каждому HBA в сервере (иногда ставят несколько HBA) и к каждой дисковой полке, чтобы коммутаторы не стали точкой отказа SAN.
HBA — специализированный контроллер, размещаемый в сервере, подключаемом к SAN. Через этот контроллер сервер будет «видеть» диски, размещаемые в дисковых полках. Сервера и дисковые полки не обязательно должны размещаться рядом, хотя для достижения высокой производительности и малых задержек это рекомендуется. Сервера и полки подключаются к коммутатору, который организует общую среду передачи данных. Коммутаторы могут также соединяться с собой с помощью межкоммутаторных соединений, совокупность всех коммутаторов и их соединений называется фабрикой. Есть разные варианты реализации фабрики, я не буду тут останавливаться подробно. Для отказоустойчивости рекомендуется подключать минимум две фабрики к каждому HBA в сервере (иногда ставят несколько HBA) и к каждой дисковой полке, чтобы коммутаторы не стали точкой отказа SAN.
Недостатками такой системы являются большая стоимость и сложность, поскольку для обеспечения отказоустойчивости требуется обеспечить несколько путей доступа (multipath) серверов к дисковым полкам, а значит, как минимум, задублировать фабрики. Также в силу физических ограничений (скорость света в общем и емкость передачи данных в информационной матрице коммутаторов в частности) хоть и существует возможность неограниченного подключения устройств между собой, на практике чаще всего есть ограничения по числу соединений (в том числе и между коммутаторами), числу дисковых полок и тому подобное.
Также в силу физических ограничений (скорость света в общем и емкость передачи данных в информационной матрице коммутаторов в частности) хоть и существует возможность неограниченного подключения устройств между собой, на практике чаще всего есть ограничения по числу соединений (в том числе и между коммутаторами), числу дисковых полок и тому подобное.
NAS
Network attached storage, или сетевое файловое хранилище, представляет дисковые ресурсы в виде файлов (или объектов) с использованием сетевых протоколов, например NFS, SMB и прочих. Принципиально базируется на DAS, но ключевым отличием является предоставление общего файлового доступа. Так как работа ведется по сети — сама система хранения может быть сколько угодно далеко от потребителей (в разумных пределах разумеется), но это же является и недостатком в случае организации на предприятиях или в датацентрах, поскольку для работы утилизируется полоса пропускания основной сети — что, однако, может быть нивелировано с использованием выделенных сетевых карт для доступа к NAS. Также по сравнению с SAN упрощается работа клиентов, поскольку сервер NAS берет на себя все вопросы по общему доступу и т.п.
Также по сравнению с SAN упрощается работа клиентов, поскольку сервер NAS берет на себя все вопросы по общему доступу и т.п.
Unified storage
Универсальные системы, позволяющие совмещать в себе как функции NAS так и SAN. Чаще всего по реализации это SAN, в которой есть возможность активировать файловый доступ к дисковому пространству. Для этого устанавливаются дополнительные сетевые карты (или используются уже существующие, если SAN построена на их основе), после чего создается файловая система на некотором блочном устройстве — и уже она раздается по сети клиентам через некоторый файловый протокол, например NFS.
SDS
Software-defined storage — программно определяемое хранилище данных, основанное на DAS, при котором дисковые подсистемы нескольких серверов логически объединяются между собой в кластер, который дает своим клиентам доступ к общему дисковому пространству.
Наиболее яркими представителями являются GlusterFS и Ceph, но также подобные вещи можно сделать и традиционными средствами (например на основе LVM2, программной реализации iSCSI и NFS).
N.B. редактора: У вас есть возможность изучить технологию сетевого хранилища Ceph, чтобы использовать в своих проектах для повышения отказоустойчивости, на нашем практическим курсе по Ceph. В начале курса вы получите системные знания по базовым понятиям и терминам, а по окончании научитесь полноценно устанавливать, настраивать и управлять Ceph. Детали и полная программа курса здесь.
Пример SDS на основе GlusterFS
Из преимуществ SDS — можно построить отказоустойчивую производительную реплицируемую систему хранения данных с использованием обычного, возможно даже устаревшего оборудования. Если убрать зависимость от основной сети, то есть добавить выделенные сетевые карты для работы SDS, то получается решение с преимуществами больших SAN\NAS, но без присущих им недостатков. Я считаю, что за подобными системами — будущее, особенно с учетом того, что быстрая сетевая инфраструктура более универсальная (ее можно использовать и для других целей), а также дешевеет гораздо быстрее, чем специализированное оборудование для построения SAN. Недостатком можно назвать увеличение сложности по сравнению с обычным NAS, а также излишней перегруженностью (нужно больше оборудования) в условиях малых систем хранения данных.
Недостатком можно назвать увеличение сложности по сравнению с обычным NAS, а также излишней перегруженностью (нужно больше оборудования) в условиях малых систем хранения данных.
Гиперконвергентные системы
Подавляющее большинство систем хранения данных используется для организации дисков виртуальных машин, при использовании SAN неизбежно происходит удорожание инфраструктуры. Но если объединить дисковые системы серверов с помощью SDS, а процессорные ресурсы и оперативную память с помощью гипервизоров отдавать виртуальным машинам, использующим дисковые ресурсы этой SDS — получится неплохо сэкономить. Такой подход с тесной интеграцией хранилища совместно с другими ресурсами называется гиперконвергентностью. Ключевой особенностью тут является способность почти бесконечного роста при нехватке ресурсов, поскольку если не хватает ресурсов, достаточно добавить еще один сервер с дисками к общей системе, чтобы нарастить ее. На практике обычно есть ограничения, но в целом наращивать получается гораздо проще, чем чистую SAN. Недостатком является обычно достаточно высокая стоимость подобных решений, но в целом совокупная стоимость владения обычно снижается.
Недостатком является обычно достаточно высокая стоимость подобных решений, но в целом совокупная стоимость владения обычно снижается.
Облака и эфемерные хранилища
Логическим продолжением перехода на виртуализацию является запуск сервисов в облаках. В предельном случае сервисы разбиваются на функции, запускаемые по требованию (бессерверные вычисления, serverless). Важной особенностью тут является отсутствие состояния, то есть сервисы запускаются по требованию и потенциально могут быть запущены столько экземпляров приложения, сколько требуется для текущей нагрузки. Большинство поставщиков (GCP, Azure, Amazon и прочие) облачных решений предлагают также и доступ к хранилищам, включая файловые и блочные, а также объектные. Некоторые предлагают дополнительно облачные базы, так что приложение, рассчитанное на запуск в таком облаке, легко может работать с подобными системами хранения данных. Для того, чтобы все работало, достаточно оплатить вовремя эти услуги, для небольших приложений поставщики вообще предлагают бесплатное использование ресурсов в течение некоторого срока, либо вообще навсегда.
Из недостатков: могут заблокировать аккаунт, на котором все работает, что может привести к простоям в работе. Также могут быть проблемы со связностью и\или доступностью таких сервисов по сети, поскольку такие хранилища полностью зависят от корректной и правильной работы глобальной сети.
Заключение
Надеюсь, статья была полезной не только новичкам. Предлагаю обсудить в комментариях дополнительные возможности систем хранения данных, написать о своем опыте построения систем хранения данных.
Как я могу хранить данные в C в табличном формате?
спросил
Изменено
12 лет, 6 месяцев назад
Просмотрено
3к раз
Я хочу хранить данные в C в табличном формате. Мне трудно рассказать следующее. Кто-нибудь может помочь?
Кто-нибудь может помочь?
Например:
Я хочу сохранить следующие записи, тогда каким должен быть идеальный способ хранения в C?
IP-адрес Имя домена 1.) 10.1.1.2 www.yahoo.com 2.) 20.1.1.3 www.google.com
Должен ли я использовать структуры? Скажем, например?
таблица структур
{
беззнаковый символьный IP-адрес;
char имя_домена[20];
};
Если нет, уточните?
- c
- структуры данных
Вероятно, вы смешиваете два разных вопроса:
- Как организовать данные в вашей программе (в памяти) — это часть об использовании структур.
- Как сериализовать данные, то есть сохранить их во внешнем хранилище, например. в файле. Это часть о «табличном» формате, который подразумевает текст с полями, разделенными табуляцией.
Если IP и домен часто встречаются в вашей программе, то разумно использовать для этого структуру или класс (в C++). Что касается вашего примера, я не знаю ограничений на длину доменного имени, но «20» было бы определенно недостаточно. Я бы предложил использовать здесь динамически выделяемые строки. Для хранения IP-адреса (v4) вы можете использовать 32-битное целое число без знака — char недостаточно. Планируете ли вы также поддерживать IP v6? тогда вам нужно 128 бит для адреса.
Я бы предложил использовать здесь динамически выделяемые строки. Для хранения IP-адреса (v4) вы можете использовать 32-битное целое число без знака — char недостаточно. Планируете ли вы также поддерживать IP v6? тогда вам нужно 128 бит для адреса.
В C (и C++) нет встроенного средства сериализации, как практически во всех динамических (или «управляемых») языках, таких как C#, Java, Python. Таким образом, определяя структуру, вы не получаете автоматически методы для записи/редактирования ваших данных. Поэтому вы должны использовать некоторую библиотеку для сериализации или написать свою собственную для чтения/записи ваших данных.
Способ хранения хотя бы частично зависит от того, что вы собираетесь делать с информацией. Если это просто прочитать его, а затем снова распечатать, вы можете обрабатывать его строго как текст.
Однако сетевые программы часто используют этот тип данных. См. структуры в системных заголовочных файлах netinet/in.h , arpa/inet. и  h
h sys/socket.h Или см. справочную страницу для inet_aton()
идти. Используйте массивы достаточного размера. Адреса IPV4 занимают 16 символов, а доменные имена — не более 255 символов.
таблица структур
{
char ip_addr[16];
char имя_домена[255];
};
3
К сожалению комментировать не могу. Но что касается ответа Амаргоша, эта проблема была бы идеально решена с использованием массивов фиксированной длины для полей, поскольку оба набора (если домен только верхнего уровня) данных имеют ограниченную длину (15 символов для IP-адреса [при условии IPv4], и существует ограничение в 63 символа ascii на метку для доменных имен.)
2
При представлении табличных данных возникают две проблемы:
1. Представление строки
2. Представление множества строк.
В вашем примере строка может быть представлена:
struct Table_Record
{
беззнаковый символ ip_address[4];
char имя_домена[MAX_DOMAIN_LENGTH];
};
Я решил использовать фиксированную длину поля для имени домена. Это упростит обработку.
Это упростит обработку.
Следующий вопрос — как структурировать строки. Это решение вам придется принять. Самое простое предложение — использовать массив. Однако массив имеет фиксированный размер, и его необходимо перераспределить, если записей больше, чем размер массива:
struct Table_Record table[MAX_ROWS];
Другой структурой данных для таблицы является список (одинарный или двойной, на ваш выбор). К сожалению, язык C не предоставляет структуру данных списка, поэтому вам придется либо написать свою собственную структуру, либо приобрести библиотеку.
Альтернативными полезными структурами данных являются карты (ассоциативные массивы) и деревья (хотя многие карты реализованы с использованием деревьев). Карта позволит вам получить значение для данного ключа. Если ключом является IP-адрес, карта вернет доменное имя.
Если вы собираетесь читать и записывать эти данные с помощью файлов, я предлагаю использовать базу данных, а не писать свою собственную. Многие рекомендуют SQLite.
Многие рекомендуют SQLite.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Добро пожаловать в TileDB Embedded! — Документация по TileDB Embedded
Что такое TileDB Embedded?
TileDB Embedded — это универсальный механизм хранения , который хранит любые данные (помимо таблиц) в мощном унифицированном формате, обеспечивая исключительную совместимость благодаря множеству API и интеграции инструментов.
TileDB Embedded — это мощный механизм, созданный на основе многомерных массивов , который позволяет хранить и получать доступ к:
плотным массивам (например, изображениям, видео и т. д.)
Sparse Arrays (например, LIDAR, Genomics и More)
DataFrames (любые таблицы, как плотные или скудные массивы)
44444444444444444444444444444444444444444444444444444444 годы могут быть модели
44444444444444444444444444444444444444444444.
например, графиков , ключей-значений , моделей машинного обучения и т. д.)
 например, графиков , ключей-значений , моделей машинного обучения и т. д.)
например, графиков , ключей-значений , моделей машинного обучения и т. д.) Вы можете использовать TileDB для хранения данных в различных приложениях, таких как геномика, геопространственные данные, биомедицинские изображения, финансы, машинное обучение , и более. Сила TileDB заключается в том, что любые данные могут быть эффективно смоделированы либо как плотный, либо как разреженный многомерный массив, который является форматом, используемым внутри большинства инструментов обработки данных. Сохраняя свои данные и метаданные в массивах TileDB, вы снимаете все проблемы с хранением и управлением данными, в то же время эффективно получая доступ к данным с помощью вашего любимого языка программирования или инструмента обработки данных с помощью наших многочисленных API и интеграций.
TileDB Embedded — это быстро встраиваемая библиотека C++ со следующими основными функциями:
Open-source under the MIT license
Fast multi-dimensional slicing via tiling (i.e., chunking)
Multiple compression , encryption and checksum filters
Быстрый, без блокировок прием
Параллельный ввод-вывод для чтения и записи
Облачное хранилище (AWS, S3lob Azure, Google Cloud Storage)0005
Ally Многопользовательская реализация
- .
Метаданные хранятся вместе с данными массива
Группы для иерархической организации данных массива
Растущий набор из API (C, C++, C#, Python, Java, R, Go),
Многочисленные интеграции (Spark, Dask, MariaDB, GDAL и др.)
Код и API
Встроенный механизм TileDB построен на C++ и предоставляет API C и C++ :
https://github.
com/TileDB-Inc/TileDB Python: https://github.com/TileDB-Inc/TileDB-Py
R: https://github.com/TileDB-Inc/TileDB-R 9002
. C# : https://github.com/TileDB-Inc/TileDB-CSharp
- Мы поддерживаем растущий набор языковых API, созданных поверх API C и C++:
Интеграции и расширения
Мы расширили TileDB Embedded, чтобы зафиксировать специфичные для предметной области аспекты важных вариантов использования:
Расширение для хранения и доступа к данным геномного варианта (VCF) Geospatial :
Интеграция с PDAL, GDAL, Rasterio и MapServerРаспределенные вычисления :
Интеграция со Spark и Dask SQL :
Интеграция с MariaDB, Presto и Trino.В группе страниц ТУТОРИАЛЫ в левом навигационном меню этих документов имеется постоянно растущий набор руководств.
Если вы хотите глубже изучить внутреннее устройство TileDB Embedded, вы можете проверить ФОН в левом навигационном меню. Вы также всегда можете ознакомиться с руководствами HOW TO и API REFERENCE .
Наконец, подробную информацию о различных интеграциях и расширениях инструментов TileDB Embedded можно найти в группе страниц INTEGRATIONS & EXTENSIONS в левом меню навигации.
Как пользоваться документами
Чтобы было проще понять, где найти то, что вы ищете, документация разбита на следующие разделы:
Учебники
Серия примеров для обучения использованию TileDB в различных случаях использованияИсходная информация
Объяснение основных тем и понятийКак
Краткие практические руководства по всем функциям TileDBСправочник по API
Технический справочник по API
Расширения и интеграции
Подробная документация по расширениям и интеграции TileDB Embedded
История
TileDB начал свою деятельность в MIT и Intel Labs в качестве исследовательского проекта в конце 2014 года, результатом которого стала статья VLDB 2017.
В мае 2017 года он был преобразован в TileDB, Inc. , компанию, которая с тех пор привлекла более 20 миллионов долларов для дальнейшего развития и поддержки проекта (см. Объявление серии A).Компания поддерживает два предложения:
1
.
Хранилище с открытым исходным кодом TileDB Embedded движок, описанный в этой документации.
2
.
 com/TileDB-Inc/TileDB
com/TileDB-Inc/TileDB 
 В мае 2017 года он был преобразован в TileDB, Inc. , компанию, которая с тех пор привлекла более 20 миллионов долларов для дальнейшего развития и поддержки проекта (см. Объявление серии A).
В мае 2017 года он был преобразован в TileDB, Inc. , компанию, которая с тех пор привлекла более 20 миллионов долларов для дальнейшего развития и поддержки проекта (см. Объявление серии A).