Форматирование c: Как форматировать диск C
Содержание
Как форматировать диск C
- Привет всем! Срочно понадобилось на одном компьютере форматировать диск C: с установленной Windows 10, как это сделать самым быстрым способом?
- Здравствуйте, скажите, как удалить диск C:? Хочу продать ноутбук, новый хозяин пожелал, чтобы он был чистый, то есть без операционной системы. Сейчас установлена Windows 8.1. Никаких установочных дисков Windows или флешек у меня нет.
Привет друзья! Если на вашем ноутбуке установлена Windows 8.1 или Windows 10, то форматировать или удалить диск C: очень просто, но имейте ввиду, что удаление и форматирование, это разные вещи.
Если вы просто удалите диск C: с установленной операционной системой, то восстановить его (и очень быстро) со всеми вашими файлами сможет любой пользователь по этой нашей статье. Восстановление произойдёт таким образом, что ваша Windows 8.1 будет загружаться и к чужим людям попадут все ваши файлы, пароли и так далее.
Другое дело форматировать диск C:, в этом случае восстановить мало что удастся.
- Примечание: Если вы продаёте ноутбук, то можете откатить его к заводским настройкам, или произвести восстановление Windows 8.1 к исходному состоянию без сохранения личных файлов.
Если же вы твёрдо решили форматировать или удалить диск C:, то читаем дальше.
Для примера, давайте возьмём мой ноутбук с установленной Windows 8.1.
Нажимаем клавишу «Shift» и не отпуская её производим перезагрузку ноутбука.
Загружается среда восстановления, выбираем «Диагностика»
«Дополнительные параметры»
«Командная строка»
В командной строке вводим команды:
diskpart
lis vol (выводим список всех разделов и видим, что Uolume 1 (Том 1), это и есть диск C: с установленной Windows 8.1. Ориентируйтесь названию или объёму, чаще всего диск C: идёт в этом списке первым или вторым, если хотите, можете прямо в командной строке войти на диск C: и увидеть все системные папки: Windows, Program Files).
sel vol 1 (выбираем Том 1)
format quick fs=NTFS (форматируем диск C: в файловую систему NTFS, можете применить параметр quick-быстрое форматирование)
Форматирование успешно завершено.
После данной операции форматирования на вашем ноутбуке будет очень трудно что-то восстановить.
Как удалить диск C: без форматирования
Если вам нужно удалить диск (C:) с возможностью последующего восстановления данных, то сделать это можно так:
Точно также, как и в предыдущем способе загружаемся в командную строку среды восстановления и вводим команды
diskpart
lis vol (выводим список всех разделов и видим, что Том 1, это и есть диск C: с установленной Windows 8.1)
sel vol 1 (выбираем Том 1)
del vol override (данной командой мы удаляем диск C:)
Удаление успешно завершено.
После данной операции удаления диска C: его можно будет восстановить вместе со всеми файлами.
форматирование диска для работы с Windows..
Команда FORMAT позволяет выполнить форматирование диска /дискеты в командной строке Windows.
Формат командной строки:
FORMAT том [/FS:файловая_система] [/V:метка] [/Q] [/A:размер] [/C] [/X] [/P:проходы] [/S:состояние]
FORMAT том [/V:метка] [/Q] [/F:размер] [/P:проходы]
FORMAT том [/V:метка] [/Q] [/T:дорожки /N:секторы] [/P:проходы]
FORMAT том [/V:метка] [/Q] [/P:проходы]
FORMAT том [/Q]
Параметры командной строки:
том — Определяет букву диска (с последующим двоеточием), точку подключения или имя тома.
/FS:файловая_система — Указывает тип файловой системы (FAT, FAT32, NTFS, или UDF).
/V:метка — Метка тома.
/Q — Быстрое форматирование. Перекрывает параметр /P.
/C — Только для NTFS: Установка режима сжатия по умолчанию для всех файлов, создаваемых на новом томе.
/X — Инициирует отключение тома, в качестве первого действия, если это необходимо. Все открытые дескрипторы тома будут неверны.
/R:редакция — только для UDF: Форматирование в указанной версии UDF (1.00, 1.02, 1.50, 2.00, 2.01, 2.50). По умолчанию используется редакция 2.01.
/D — Только UDF 2.50: Метаданные будут продублированы.
/A:размер — Заменяет размер кластера по умолчанию. В общих случаях рекомендуется использовать размеры кластера по умолчанию.
NTFS поддерживает размеры 512, 1024, 2048, 4096, 8192, 16 КБ, 32 КБ, 64K.
FAT поддерживает размеры 512, 1024, 2048, 4096, 8192, 16 КБ, 32 КБ, 64 КБ, (128 КБ, 256 КБ для размера сектора > 512 байт).
FAT32 поддерживает размеры 512, 1024, 2048, 4096, 8192, 16 КБ, 32 КБ, 64 КБ, (128 КБ, 256 КБ для размера сектора > 512 байт).
exFAT поддерживает размеры 512, 1024, 2048, 4096, 8192, 16 КБ, 32 КБ, 64 КБ, 128 КБ, 256 КБ, 512 КБ, 1 МБ, 2 МБ, 4 МБ, 8 МБ, 16 МБ, 32 МБ.
Файловые системы FAT и FAT32 налагают следующие ограничения
на число кластеров тома:
FAT: число кластеров
FAT32: 65 526
Выполнение команды FORMAT будет немедленно прервано, если
будет обнаружено нарушение указанных выше ограничений,
используя указанный размер кластеров.
Сжатие NTFS не поддерживается для кластеров размером
более 4096.
/F:размер — Указывает размер форматируемых гибких дисков (1,44)
/T:дорожки — Число дорожек на каждой стороне диска.
/N:секторы — Число секторов на каждой дорожке.
/P:раз — Обнуляет каждый сектор тома указанное число раз. Этот параметр не действует с параметром /Q
/S:состояние — Где «состояние» может принимать значения «enable» или «disable». Короткие имена по умолчанию включены
Примеры использования команды FORMAT:
format /? — отобразить справку по использованию команды
format /? | more — отобразить справку по использованию команды с постраничным режимом вывода на экран.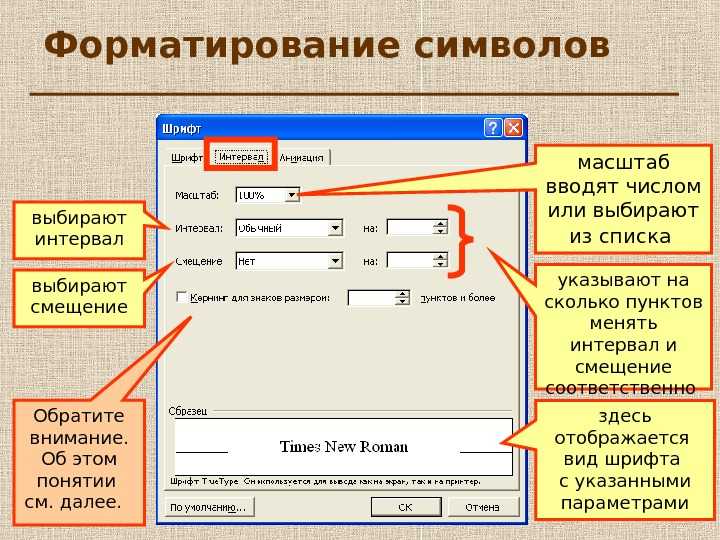
format /? > C:\formathelp.txt — отобразить справку по использованию команды с выводом в текстовый файл C:\formathelp.txt
format A: — форматировать гибкий диск в дисководе A: с параметрами по умолчанию.
В процессе выполнения команды format отображается сообщения:
Вставьте новый диск в дисковод A:
и нажмите клавишу ENTER…
Тип файловой системы: FAT.
Проверка: 1,44 МБ
Дискета будет отформатирована с использованием типа файловой системы FAT и
объемом 1.44 МБ
Если на форматируемом диске имеются открытые файлы, то команда format выдаст предупреждение:
Невозможно запустить команду Format, т.к. том используется другим процессом.
Можно запустить Format, если вначале отключить этот том.
ВCE ОТКРЫТЫЕ ДЕСКРИПТОРЫ ТОМА БУДУТ ДАЛЕЕ НЕВЕРНЫ.
Подтверждаете отключение тома? [Y(да)/N(нет)]
Пользователь имеет возможность отменить форматирование или продолжить его, введя
Y. После подтверждения запроса будет выполнено принудительное закрытие всех файлов и отключение тома. Данная операция не может быть выполнена для системного диска.
После подтверждения запроса будет выполнено принудительное закрытие всех файлов и отключение тома. Данная операция не может быть выполнена для системного диска.
Том отключен. ВCE ОТКРЫТЫЕ ДЕСКРИПТОРЫ ТОМА СТАЛИ НЕВЕРНЫ.
После начала форматирования, отображается информация о его ходе, запрос метки тома и результаты:
Инициализируется File Allocation Table (FAT)…
Метка тома (11 символов, ENTER — метка не нужна):
Форматирование окончено.
1 457 664 байт всего на диске.
1 457 664 байт доступно на диске.
512 байт в каждом кластере.
2 847 кластеров на диске.
12 бит в каждой записи FAT.
Серийный номер тома: 3281-2839
FORMAT A: /T:80 /N:9 — форматировать гибкий диск в файловую систему FAT, с использованием геометрии 80 дорожек и 9 секторов на дорожку ( дискета емкостью 720кб).
FORMAT F: /FS:NTFS — форматировать съемный диск ( флэшку ) в файловую систему NTFS. Необходимо учитывать, что файловая система NTFS не поддерживается на устройствах, оптимизированных для быстрого удаления. Поэтому для того, чтобы отформатировать обычную флешку в NTFS, необходимо изменить метод оптимизации, для чего в диспетчере устройств Windows открыть свойства съемного диска и перейти на вкладку
Необходимо учитывать, что файловая система NTFS не поддерживается на устройствах, оптимизированных для быстрого удаления. Поэтому для того, чтобы отформатировать обычную флешку в NTFS, необходимо изменить метод оптимизации, для чего в диспетчере устройств Windows открыть свойства съемного диска и перейти на вкладку
«Политика»
После установки политики Оптимизировать для выполнения форматирование раздела флешки в файловую систему NTFS станет возможным:
Вставьте новый диск в дисковод F:
и нажмите клавишу ENTER…
Тип файловой системы: FAT32.
Новая файловая система: NTFS.
format L: /fs:UDF /V:UDFTOM /Q — форматировать оптический диск в файловую систему UDF ( Universal Disk Format, универсальный дисковый формат ) . Метка форматируемого тома — UDFTOM. Используется быстрое форматирование ( /Q ), т.е создание оглавления без проверки блоков. Если перезаписываемый оптический диск содержит данные, то программа запросит метку существующего тома:
Введите метку тома для диска L: Disk19 — метка существующего тома.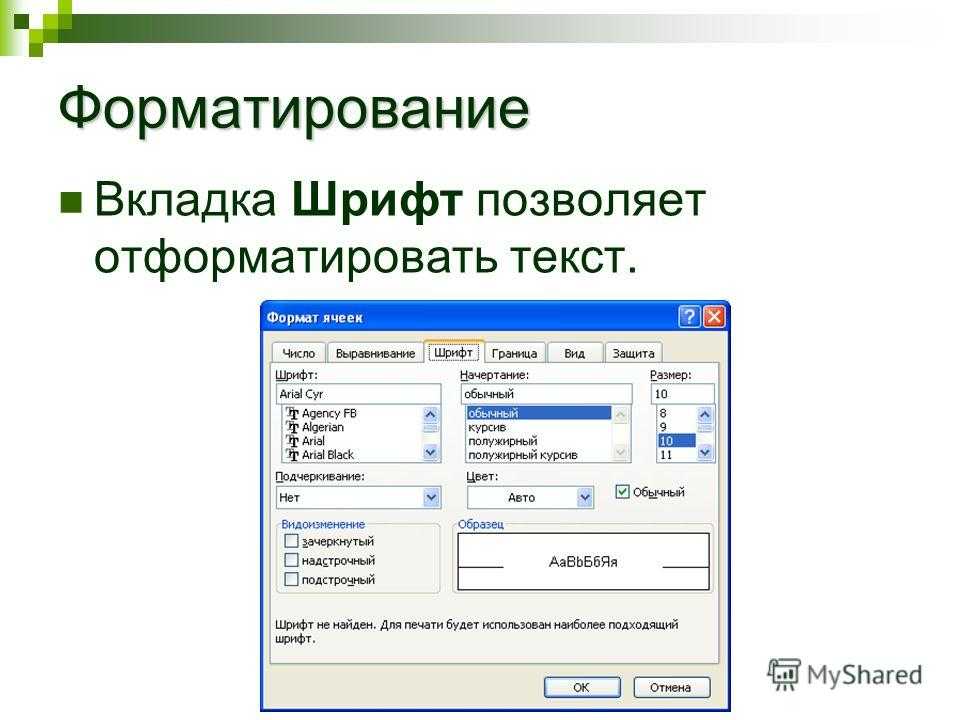
Если диск не пустой и текущий формат тома не позволяет выполнить быстрое форматирование, то утилита format выдаст сообщение:
Недопустимый текущий формат.
Быстрое форматирование диска невозможно.
Приступить к безусловному форматированию [Y(да)/N(нет)]?
После ответа Y форматирование будет продолжено:
Выполнение форматирования на нижнем уровне…
Создание структур файловой системы.
Форматирование окончено.
4,38 ГБ всего на диске.
Доступно: 4,38 ГБ.
После завершения форматирования, перезаписываемый оптический диск с файловой системой UDF можно использовать как в проводнике, так и в
командной строке Windows для создания, изменения и удаления файлов и каталогов, так же, как например дискету большой емкости или флешку.
Коды формата C printf-Style
Коды формата в стиле C printf
Коды формата в стиле C printf указывают, как данные должны передаваться с использованием формата, аналогичного формату функции C printf.
Пример
Используйте стиль C printf для вывода шести чисел, заключенных в фигурные скобки:
PRINT, INDGEN(3), FORMAT = 'Значения: {%d} {%d} {%d} ' Печать IDL:
Значения: {0} {1} {2} Синтаксис
Синтаксис кода формата в стиле C printf:
%[-][0][width]C
Где:
| % | отмечает начало кода формата. |
| – | необязательно, указывает выравнивание по левому краю выходного аргумента. |
| 0 | необязательно, добавляет нулевой отступ слева, чтобы соответствовать ширине. |
ширина | дополнительная спецификация ширины. |
С | — это код формата. Смотри ниже. |
 Спецификации ширины и значения по умолчанию зависят от кода формата и описаны ниже с помощью кодов формата.
Спецификации ширины и значения по умолчанию зависят от кода формата и описаны ниже с помощью кодов формата.Поддерживаемые коды «%»
В следующей таблице перечислены коды формата %, разрешенные в коде формата строки в кавычках в стиле printf, а также их соответствие стандартным кодам формата, которые делают то же самое. В дополнение к кодам формата, описанным в таблице, специальная последовательность %% приводит к тому, что на выходе записывается один символ %. Этот % рассматривается как обычный символ, а не как спецификатор кода формата. Наконец, флаги и параметры заполнения ширины, описанные в Синтаксисе, также доступны при использовании кодов формата в стиле printf.
Стиль Printf | Описание |
%% | Вставьте один символ %. |
%б, %В % с б, % с В % в.м. б, % в.м. В | Передача данных в двоичной системе счисления, w — общая ширина, m — минимальное количество непустых цифр. Нет никакой разницы между строчными и прописными формами. |
%д, %д % w d, % w D % в.м. d, % в.м. D %i, %I % w i, % w I % мас.м i, % в.м. I | Передача целочисленных данных, w — общая ширина, m — минимальное количество непустых цифр. |
%е, %Е % w e, % w E % в.д. e, % в.д. E | Передача данных в экспоненциальной записи, w — общая ширина, d — количество знаков после запятой. В зависимости от кода будет использоваться буква «e» в нижнем или верхнем регистре. |
%ф, %ф % w ж, % w F % в.д. f, % в.д. F | Передача данных в формате с плавающей запятой, w общая ширина, d — это количество цифр после запятой. |
%г, %Г % вес г, % вес г % в.д. г, % в.д. G | Передача данных в формате с плавающей запятой или в экспоненциальном представлении, w — общая ширина, d — общее количество значащих цифр. Используйте %e или %E, если показатель степени меньше –4 или больше или равен точности, в противном случае используйте %f. |
%о, %О % w о, % w O % в.м. o, % в.м. O | Передача данных в восьмеричном представлении, w общая ширина, m минимальное количество непустых цифр. |
%с, %С % w с, % w S | Передача символьных данных до тех пор, пока не будет достигнут либо нулевой байт (\0), либо общая ширина w . |
%х, %Х % w x, % w X % вес.м х, % вес.м X %z, %Z % w z, % w Z % вес.м. z, % вес.м. Z | Передача данных в шестнадцатеричной системе счисления, w — общая ширина, m — минимальное количество непустых цифр. |

 Нет никакой разницы между строчными и прописными формами. Формы %d идентичны формам %i и предназначены для программистов, знакомых с printf языка C.
Нет никакой разницы между строчными и прописными формами. Формы %d идентичны формам %i и предназначены для программистов, знакомых с printf языка C. Нет никакой разницы между строчными и прописными формами.
Нет никакой разницы между строчными и прописными формами. Нет никакой разницы между строчными и прописными формами.
Нет никакой разницы между строчными и прописными формами. %x или %z в нижнем регистре дадут шестнадцатеричные цифры нижнего регистра, а %X или %Z в верхнем регистре дадут прописные.
%x или %z в нижнем регистре дадут шестнадцатеричные цифры нижнего регистра, а %X или %Z в верхнем регистре дадут прописные.Экранирование символов обратной косой черты
IDL поддерживает следующие «экранированные последовательности» в строке формата:
Последовательность выхода | Код ASCII |
\а, \А | БЕЛ (7Б) |
\б, \б | Возврат (8B) |
\ф, \ф | Подача бумаги (12B) |
\n, \N | Перевод строки (10B) |
\р, \р | Возврат каретки (13B) |
\т, \т | Горизонтальная вкладка (9Б) |
мкВ, мкВ | Вертикальный выступ (11B) |
\ооо | Восьмеричное значение ооо (восьмеричное значение 1-3 цифры) |
\xhh | Шестнадцатеричное значение hh (шестнадцатеричное значение 1-2 цифры) |
Примечание: Если символу, не указанному в этой таблице, предшествует обратная косая черта, обратная косая черта удаляется, а символ вставляется без какой-либо специальной интерпретации. Например, вы можете использовать \% для вставки символа процента или \» для вставки символа двойной кавычки.
Например, вы можете использовать \% для вставки символа процента или \» для вставки символа двойной кавычки.
Различия между C printf и IDL printf
- Процедуры IDL PRINT и PRINTF неявно добавляют символ конца строки в конец строки (если это не подавлено использованием кода формата $). Использование \n в конце строки формата для завершения строки не требуется и не рекомендуется.
- Только перечисленные выше последовательности формата % понимаются IDL. Большинство функций C printf принимают больше кодов, чем эти, но эти коды не поддерживаются или не нужны. Например, функции C printf/scanf требуют использования кода формата %u для указания значения без знака, а также использования модификаторов типа (h, l, ll) для указания размера обрабатываемых данных. IDL использует тип аргументов, подставляемых в формат, для определения этой информации. Поэтому коды u, h, l и ll не требуются в IDL и не принимаются.
- Функция C printf позволяет использовать нотацию % n $d, чтобы указать, что аргументы должны подставляться в строку формата в другом порядке, чем они перечислены.
 IDL не поддерживает это.
IDL не поддерживает это. - Функция C printf позволяет использовать нотацию %*d для указания того, что ширина поля будет предоставлена следующим аргументом, а аргумент, следующий за ним, предоставляет фактическое значение. IDL не поддерживает это.
 IDL не поддерживает это.
IDL не поддерживает это.4 Форматирование в стиле C | Обработка строк с помощью R
R поставляется с функцией sprintf() , которая обеспечивает форматирование строк.
как в языке C . Если быть более точным, эта функция является оберткой
для одноименной функции библиотеки C. Во многих других программах
языков этот тип печати известен как printf , что означает
форматирование печати . Проще говоря,
спринтф() позволяет создавать строки в качестве вывода с использованием форматированных данных.
Функция sprintf() требует использования специального синтаксиса, который может выглядеть
неудобно при первом использовании. Вот один пример:
Вот один пример:
sprintf("Я проснулся в %s:%s%s утра", 8, 0, 5)
#> [1] "Я проснулся в 8:05 утра." Как работает sprintf() ? Первым аргументом этой функции является символ
вектор одного элемента, содержащего форматируемый текст. Обратите внимание, что
внутри текста есть различные символы процентов % с последующей буквой
с . Каждый % называется слотом , который в основном является заполнителем.
для переменной, которая будет отформатирована. Остальные входы перешли к
sprintf() — это значения, которые будут использоваться в каждом из слотов.
Строка в предыдущем примере содержит три слота одного типа, %s ,
а последующие аргументы — числа 8 , 0 и 5 . Каждое число используется
как значение для каждого слота. Буква s указывает, что отформатированная переменная
указывается как строка .
В большинстве случаев вы не будете использовать sprintf() , как в примере выше.
Вместо этого вы будете передавать переменные, содержащие разные значения:
час <- 8
мин1 <- 0
мин2 <- 5
sprintf("Я проснулся в %s:%s%s утра", час, мин1, мин2)
#> [1] "Я проснулся в 8:05 утра." Строковый формат %s — лишь один из большого списка доступных форматов.
опции. В следующей таблице показаны наиболее распространенные спецификации форматирования:
%s | строка |
%д | целое число |
%0xd | целое число, дополненное ведущими нулями размером x |
%f | десятичная запись с шестью десятичными знаками |
%.xf | число с плавающей запятой с x цифрами после запятой |
%е | компактная научная запись, e в показателе степени |
%Е | компактная научная запись, E в показателе степени |
%г | компактное десятичное или экспоненциальное представление (с e ) |
4.
 1.1 Синтаксис слота формата
1.1 Синтаксис слота формата
Полный синтаксис слота формата определяется следующим образом:
%[параметр][флаги][ширина][.точность][длина]тип
Символ процента, % , как мы уже говорили, указывает на местозаполнитель или слот.
Поле параметра является необязательным полем, которое может принимать значение n$ , в котором
n — это номер отображаемой переменной, что позволяет использовать предоставленные переменные.
использоваться несколько раз, используя разные спецификаторы формата или в разных
заказы.
sprintf("Второе число %2$d, первое число %1$d", 2, 1)
#> [1] "Второе число равно 1, первое число равно 2" Поле флагов может состоять из нуля или более (в любом порядке):
-
-(минус) Выровнять вывод этого заполнителя по левому краю. -
+(плюс) Добавляет плюс для положительных числовых типов со знаком. -
' '(пробел) Добавляет пробел для положительных числовых типов со знаком. -
0(ноль) Если указан параметр «ширина», перед числовыми типами добавляются нули. -
#(решетка) Альтернативная форма:- для типов
гиGнули в конце не удаляются. - для типов
f, F, e, E, g, Gвыходные данные всегда содержат десятичную точку. - для типов
o, x, Xтекст0,0x,0Xсоответственно является
перед ненулевыми числами.
- для типов
Поле ширина является необязательным полем, которое используется для указания минимального числа
символов для вывода и обычно используется для заполнения полей фиксированной ширины в
табличный вывод, где в противном случае поля были бы меньше, хотя это
не вызывает усечение слишком больших полей.
спринтф("%*д", 5, 10)
#> [1] " 10" Поле точности обычно указывает максимальный предел вывода,
в зависимости от конкретного типа форматирования.
sprintf("%.*s", 3, "abcdef")
#> [1] "abc" Поле length также является необязательным и может быть любым из:
Наиболее важным полем является поле типа .
-
%: Печатает буквальный символ%(этот тип не принимает никаких флагов,
поля ширины, точности, длины). -
d, i: целочисленное значение в виде десятичного числа со знаком. -
f: двойное значение в обычном представлении с фиксированной точкой. -
e, E: двойное значение в стандартной форме. -
g, G: двойное значение в нормальном или экспоненциальном представлении. -
x, X: целое число без знака в виде шестнадцатеричного числа.xиспользует нижний регистр, а
Xиспользует верхний регистр. -
o: беззнаковое целое число в восьмеричной системе счисления. -
s: строка с завершающим нулем. -
a, A: двойное значение в шестнадцатеричном представлении

4.1.2 Пример: basic
sprintf()
Давайте начнем с минимального примера, чтобы изучить различные параметры форматирования.
из sprintf() . Рассмотрим реальную дробь, например 1/6 ; в R вывод по умолчанию
этой дроби будет:
1 / 6 #> [1] 0.167
Обратите внимание, что 1/6 печатается с семью десятичными цифрами. Число 1/6 есть
на самом деле иррациональное число, поэтому компьютер должен округлить его до некоторого
количество десятичных цифр. Вы можете изменить формат печати по умолчанию в нескольких
способы. Один из вариантов — отображать только шесть десятичных цифр с опцией %f :
# печатать 6 десятичных знаков
спринтф('%f', 1/6)
#> [1] "0.166667" Но вы также можете указать другое количество десятичных цифр, скажем, 3. Это может
может быть достигнуто заданием опции %. : 3f
3f
# вывести 3 десятичных знака
спринтф('%.3f', 1/6)
#> [1] "0,167" В таблице ниже показаны шесть различных выходов для 1/6
%s | 0,166666666666667 |
%f | 0,166667 |
%.3f | 0,167 |
%е | 1.666667e-01 |
%Е | 1.666667E-01 |
%г | 0,166667 |
Когда бы вы использовали sprintf() ? Каждый раз, когда вы производите вывод текста. Немного
случаи включают:
- экспорт вывода в некоторый файл.
- на консоль.
- формирование новых строк.
Вывод

4.1.3 Пример: Имена файлов
При работе над проектами анализа данных обычно
файлы с похожими именами (например, для создания изображений, файлов данных или
документы). Представьте, что вам нужно сгенерировать имена 3 файлов данных
(с расширением .csv). Все файлы имеют одинаковое имя префикса, но каждый из них
имеет другое число: data01.csv , data02.csv и data03.csv .
Одно наивное решение для создания вектора символов с этими именами в R было бы
можно написать что-то вроде этого:
имена_файлов <- c('data01.csv', 'data02.csv', 'data03.csv') Вместо записи каждого имени файла вы можете сгенерировать вектор имен файлов
более эффективным способом, использующим преимущества векторизованной природы
paste0() :
имена_файлов <- paste0('data0', 1:3, '.csv')
имена_файлов
#> [1] "data01.csv" "data02.csv" "data03.csv" Теперь представьте, что вам нужно сгенерировать 100 имен файлов, пронумерованных от 01, 02, 03,
до 100. Вы можете написать вектор со 100 именами файлов, но это займет
Вы можете написать вектор со 100 именами файлов, но это займет
вы некоторое время. Предпочтительным решением является использование paste0() , как в подходе
предыдущего примера. Однако в этом случае вам потребуется создать два
отдельные векторы — один с номерами от 01 до 09, а другой с номерами
от 10 до 100, а затем объединить их в один вектор:
files1 <- paste0('data0', 1:9, .csv)
files2 <- paste0('данные', 10:100, '.csv')
file_names <- c(files1, files2) Вместо использования paste0() для создания двух векторов можно использовать sprintf()
с опцией %0xd , чтобы указать, что целое число должно быть дополнено x
ведущие нули. Например, первые девять имен файлов могут быть сгенерированы как:
sprintf('data%02d.csv', 1:9)
#> [1] "data01.csv" "data02.csv" "data03.csv" "data04.csv" "data05.csv"
#> [6] "data06.csv" "data07.csv" "data08.csv" "data09.csv" Чтобы сгенерировать 100 имен файлов, выполните:
file_names <- sprintf('data%02d. csv', 1:100)  csv', 1:100)
csv', 1:100) Первые девять элементов в file_names будут включать начальный ноль перед
целое; следующие элементы не будут включать начальный нуль.
4.1.4 Пример: градусы Фаренгейта в градусы Цельсия
В этом примере используется функция преобразования градусов Фаренгейта
в градусах Цельсия. Формула преобразования:
\[
Цельсий = (Фаренгейты - 32) \times \frac{5}{9}
\]
Вы можете определить простую функцию to_celsius() , которая принимает один аргумент,
temp , число, представляющее температуру в градусах Фаренгейта.
Эта функция вернет температуру в градусах Цельсия:
to_celsius <- function(temp = 1) {
(темп - 32) * 5/9
} Вы можете использовать to_celsius() как любую другую функцию в R. Допустим, вы хотите
узнать, сколько градусов по Цельсию составляют 95 градусов по Фаренгейту:
to_celsius(95) #> [1] 35
Чтобы было интереснее, давайте создадим еще одну функцию, которая не только
вычисляет преобразование температуры, но также выводит более информативное сообщение, например: 95 градусов по Фаренгейту = 35 градусов по Цельсию .
Назовем эту функцию по Фаренгейту2Цельсия() :
по Фаренгейту2Цельсия <- function(temp = 1) {
Цельсия <- to_celsius(temp)
sprintf('%.2f градусов по Фаренгейту = %.2f градусов по Цельсию', temp, celsius)
} Обратите внимание, что по Фаренгейту2Цельсия() использует to_celsius() для
вычислить градусы Цельсия. И затем sprintf() используется с параметрами
%.2f для отображения температуры с двумя десятичными разрядами. Попробуйте:
по Фаренгейту2Цельсия(95) #> [1] "95,00 градусов по Фаренгейту = 35,00 градусов по Цельсию" по Фаренгейту2Цельсия(50) #> [1] "50,00 градусов Фаренгейта = 10,00 градусов Цельсия"
4.1.5 Пример: Пройденное автомобилем расстояние
Наш третий пример немного сложнее. Идея состоит в том, чтобы построить
объект класса "автомобиль" , который содержит такие характеристики, как имя
автомобиля, его марки, года выпуска и расхода топлива в городе ,
шоссе и вместе взятые .
В качестве примера рассмотрим Mazda 3 . Один из возможных способов определения
объект "car" должен использовать список со следующими элементами:
mazda3 <- list( name = 'mazda3', # название автомобиля make = 'mazda', # марка автомобиля год = 2015, # модель года city = 30, # расход топлива в городе шоссе = 40, # расход топлива на шоссе в смешанном режиме = 33) # расход топлива в смешанном цикле (город-шоссе)
Пока у нас есть объект mazda3 , который по сути является списком. Потому что мы
хотим создать метод print() для объектов класса "автомобиль" мы
необходимо назначить этот класс нашему mazda3 :
class(mazda3) <- "car"
Теперь, когда у нас есть объект "car" , мы можем создать функцию print.car() .
Таким образом, каждый раз, когда мы набираем mazda3 вместо обычного списка
вывод, мы получим настроенный дисплей:
print.
 car <- function(x) {
кошка("Машина\n")
кошка(sprintf('имя: %s\n', x$имя))
кошка(sprintf('сделать: %s\n', x$сделать))
кошка(sprintf('год: %s\n', x$год))
невидимый (х)
}
car <- function(x) {
кошка("Машина\n")
кошка(sprintf('имя: %s\n', x$имя))
кошка(sprintf('сделать: %s\n', x$сделать))
кошка(sprintf('год: %s\n', x$год))
невидимый (х)
} В следующий раз, когда вы наберете в консоли mazda3 , R отобразит следующие строки:
mazda3 #> Автомобиль #> имя: mazda3 #> марка: мазда #> year: 2015
Было бы неплохо иметь функцию miles() , позволяющую вычислять
пройденное расстояние на данном количестве бензина (в галлонах) с учетом
тип расхода топлива (например, город, трасса, смешанный):
миль <- функция (автомобиль, топливо = 1, мили на галлон = 'город') {
stopifnot(класс(автомобиль) == 'автомобиль')
переключатель (миль на галлон,
'город' = машина $ город * топливо,
«шоссе» = автомобиль $ шоссе * топливо,
'комбинированный' = автомобиль $ комбинированный * топливо,
машина$город * топливо)
} Функция miles() принимает три параметра: автомобиль является объектом
класс "автомобиль" , топливо количество галлонов и миль на галлон
тип расхода топлива ( 'город', шоссе , совмещенное’ ). «автомобиль» 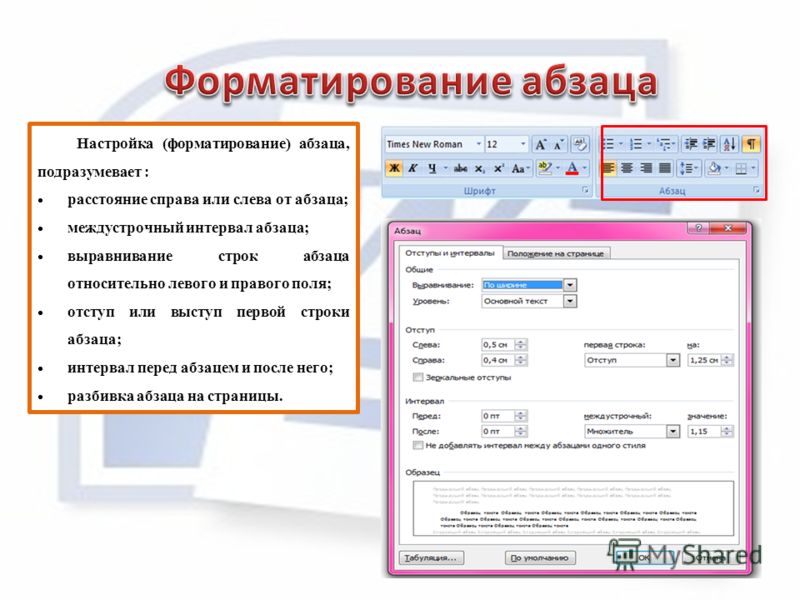 Первая команда проверяет, является ли первый параметр объектом класса
Первая команда проверяет, является ли первый параметр объектом класса . Если это не так, то функция остановит выполнение, вызвав ошибку. Вторая команда включает использование функции switch() для вычисления пройденных миль. Он переключается на соответствующий расход в зависимости от предоставленного значения миль на галлон . Обратите внимание, что самое последнее условие переключения является условием _безопасности_ на тот случай, если пользователь неправильно укажет миль на галлон.
Предположим, вы хотите узнать, сколько миль может проехать mazda3 .
проезд с 4 галлонами газа в зависимости от различных видов потребления:
миль (mazda3, топливо = 4, 'город') #> [1] 120 мили(mazda3, топливо = 4, 'шоссе') #> [1] 160 мили(mazda3, топливо = 4, 'комбинированный') #> [1] 132
Опять же, чтобы сделать все более удобным для пользователя, мы собираемся создать функцию
get_distance() , которая выводит более информативное сообщение о
пройденное расстояние:
get_distance <- функция (автомобиль, топливо = 1, мили на галлон = 'город') {
расстояние <- миль (автомобиль, топливо = топливо, мили на галлон = мили на галлон)
cat(sprintf('%s может проехать %s миль\n',
car$name, расстояние))
cat(sprintf('с %s галлонов газа\n', топливо))
cat(sprintf('с расходом %s', миль на галлон))
} А вот как выглядит вывод при вызове get_distance :
get_distance(mazda3, 4, 'city') #> Mazda3 может проехать 120 миль #> с 4 галлонами газа #> использование городского потребления
4.
 1.6 Пример: Цены на кофе
1.6 Пример: Цены на кофе
Рассмотрим некоторые кофейные напитки и их цены. Мы поместим эту информацию в
такой вектор:
цены <- c( 'американо' = 2, «латте» = 2,75, «мокко» = 3,45, 'капучино' = 3,25)
Какой тип вектора цены ? Это вектор символов? Это числовое
вектор? Или это какой-то вектор с микс-данными? Мы видели, что векторы
представляют собой атомарных структур, а это означает, что все их элементы должны быть
тот же класс. Так цены это точно не вектор с микс-данными.
Из фрагмента кода видно, что каждый элемент вектора формируется
строкой, за которой следует знак = , за которым следует некоторое число.
Такой способ определения вектора не очень распространен в R, но он прекрасно
действительный. Каждая строка представляет имя элемента, а
числа являются фактическими элементами. Поэтому цены на самом деле
числовой вектор. Вы можете убедиться в этом, посмотрев на режим (или тип данных):
режим(цены) #> [1] "numeric"
Допустим, вы хотите перечислить названия сортов кофе и их цены.