C где хранить данные: c++ — Способы хранения данных в С++
Содержание
ipad — Хранение данных в OBJECTIVE-C
Задать вопрос
Вопрос задан
Изменён
9 лет 2 месяца назад
Просмотрен
1k раз
Всегда хранил в NSUserDefaults пользовательские настройки нестрогой секретности.
Недавно случайно (а все в жизни неслучайно)))) пролистал статью о том — что данные к которым пользователь ни за что не должен получить доступ (например игровой счет в игре — количество игровых баллов) не стоит хранить в NSUserDefaults. Потому что к нему можно легко получить доступ и перебить данные
Статью пролистал поверхностно — а сейчас столкнулся с вопросом защиты переменных в приложении от возможного доступа пользователя. Так где же хранить? создавать синглтон? продолжать пользоваться NSUserDefaults? Или еще что-то?
Так где же хранить? создавать синглтон? продолжать пользоваться NSUserDefaults? Или еще что-то?
- ipad
- objective-c
- ios
- iphone
3
К NSUserDefaults пользователь скорее всего не получит доступ, если только Вы не выводите значения явно в Настройки через preferences или если к пользователю в руки не попал .ipa-пакет Вашего приложения и у него есть хорошее желание его разобрать. В таком случае его можно разархивировать и попробовать менять данные через .plist’ы которые располагаются внутри пакета в нескомпилированном виде. Начиная с iOS7 после компиляции в бинарник помимо прочего точно собираются изображения, возможно и .plist’ы(это еще нужно будет проверить). Если так то никто никогда не доберется до Ваших настроек.
5
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
в ДНК записали в два раза больше данных
07 марта 2022
15:38
Ольга Мурая
ДНК — макромолекула, хранящая биологическую информацию в виде генетического кода.
Фото Pixabay.
Учёные США добавили целых семь нуклеотидов в привычную цепочку ДНК. Полученное хранилище данных теперь может вместить в два раза больше информации, чем раньше.
Дезоксирибонуклеиновая кислота (ДНК) представляет собой природную систему хранения информации. И, как и прочие творения природы, эта система по эффективности превосходит всё, что ранее пытался создать человек. Однако недавно кое-что поменялось.
ДНК состоит из комбинаций четырёх азотистых оснований: аденина, гуанина, цитозина и тимина. Обозначенные буквами A, G, C и T, эти основания группируются в определённой последовательности, создавая «чертежи» для каждого живого организма.
И эта система хранения информации обладает невероятной по современным меркам плотностью: один грамм ДНК способен сохранить в себе до 215 петабайт (215 миллионов гигабайтов) данных. Получается, всё содержимое Интернета может поместиться в обувной коробке, если бы её доверху заполнили нитями ДНК.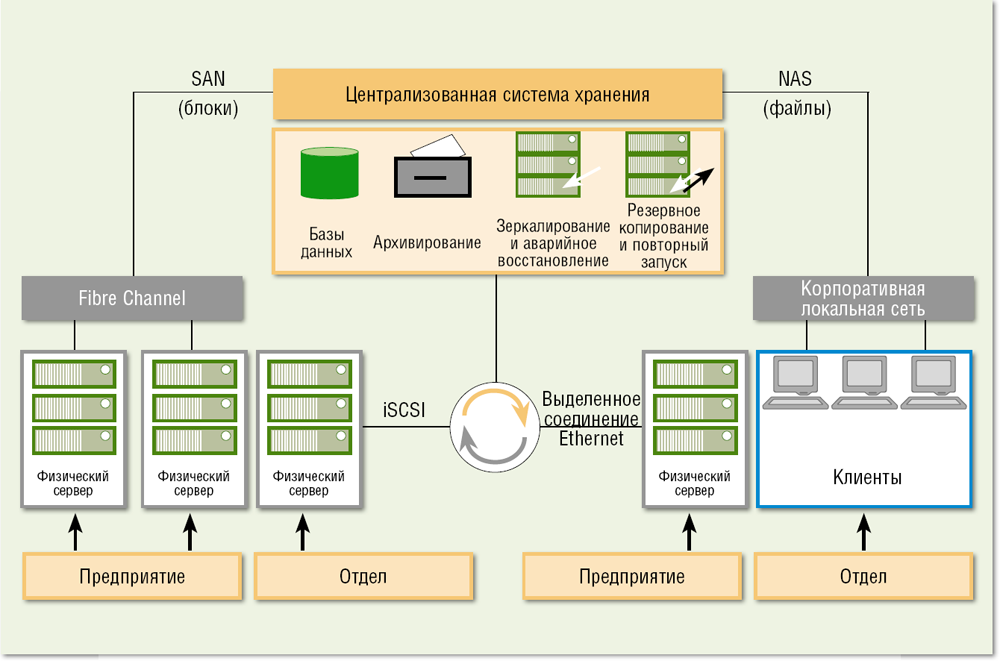
Недавно учёные продемонстрировали способ сделать это хранилище ещё более плотным.
Исследователи из Иллинойсского университета в Урбане-Шампейне удвоили и без того невероятную ёмкость «памяти» ДНК, добавив дополнительные буквы в её «алфавит». Они также разработали новый способ её «чтения».
Такая система представляется очень привлекательным потенциальным решением для хранения огромных объёмов данных, которые ежедневно производит современное общество.
Наряду с естественными A, G, C и T команда добавила семь дополнительных «букв» в ДНК. Они представляют собой химически модифицированные нуклеотиды. Такой подход позволил создать больше разнообразных комбинаций «букв». Это, в свою очередь, позволило хранить больше информации в том же объёме физического пространства.
«Представьте себе английский алфавит, – объясняет Сейедкасра Табатабаи (Seyedkasra Tabatabaei), соавтор исследования из Института передовых наук и технологий Бекмана. – Если бы у вас было только четыре буквы, вы могли бы составить столько-то слов.
Если бы у вас был полный алфавит, вы могли бы создавать неограниченное количество комбинаций слов. То же самое и с ДНК. Вместо того чтобы преобразовывать нули и единицы в A, G, C и T, мы можем преобразовать нули и единицы в A, G, C, T и семь новых букв в алфавите хранилища».
 Если бы у вас был полный алфавит, вы могли бы создавать неограниченное количество комбинаций слов. То же самое и с ДНК. Вместо того чтобы преобразовывать нули и единицы в A, G, C и T, мы можем преобразовать нули и единицы в A, G, C, T и семь новых букв в алфавите хранилища».
Если бы у вас был полный алфавит, вы могли бы создавать неограниченное количество комбинаций слов. То же самое и с ДНК. Вместо того чтобы преобразовывать нули и единицы в A, G, C и T, мы можем преобразовать нули и единицы в A, G, C, T и семь новых букв в алфавите хранилища».Конечно, добавление дополнительных нуклеотидов означает, что существующие системы обратного считывания данных не распознают их, поэтому исследовательская группа также разработала новую систему считывания.
Для «чтения» нить ДНК провели через нанопоры в специально разработанном белке, который может обнаруживать отдельные единицы независимо от того, являются ли они природными или синтетическими. Затем алгоритмы машинного обучения декодируют считанную таким образом информацию.
Учёные испробовали 77 различных комбинаций одиннадцати нуклеотидов. Разработанная система считывания смогла правильно определить каждую из них. При этом структура глубокого обучения, используемая разработчиками как часть метода идентификации различных нуклеотидов, является универсальной. Это позволит использовать новый подход во многих других приложениях.
Это позволит использовать новый подход во многих других приложениях.
Есть и ещё один плюс. Новый метод повышает не только плотность, но и скорость записи данных. Последняя в случае ДНК происходит довольно медленно. Новая система примерно вдвое сократила время, необходимое для записи информации в нити ДНК.
Отметим, что системы хранения данных в ДНК разрабатывают уже довольно давно, но учёным пока не удаётся получить систему, которая могла бы составить достойную конкуренцию существующим.
Однако эта работа приблизила человечество ещё на один шаг к получению жизнеспособной системы хранения данных на основе ДНК. Впрочем, даже авторы нынешнего исследования признают, что предстоит проделать ещё много работы.
Статья американских химиков была опубликована в журнале Nano Letters 25 февраля 2022 года.
Ранее мы рассказывали о том, как навечно записать в стекло сотни терабайт информации с помощью лазера, разместить бит информации в одном атоме, а также об устройстве хранения данных, сделанном из яичной скорлупы.
Больше интересных новостей из мира науки и технологий вы найдёте в разделе «Наука» на медиаплатформе «Смотрим».
технологии
наука
химия
память
ДНК
хранение данных
информация
общество
новости
Ранее по теме
500 терабайт данных запишут лазером в стекло навечно
Новый рекорд: квантовый симулятор научили управлять 256 кубитами
Исследователи превратили бактерию в молекулярный магнитофон
Из ДНК бактерий создали «жёсткий диск» и записали на него видео
Бит информации разместили в одном атоме
Новая технология позволит сохранить всю информацию человечества в одной комнате при помощи ДНК
int — Как данные хранятся во время программирования на C?
Когда я думаю о хранении переменных в C, в основном я думаю о машинно-независимых блоках. Итак, дано
Итак, дано
int x = 123;
первая мысль, что это выглядит так:
+-----------+ х: | 123 | +-----------+
А поскольку это локальная переменная, я знаю, что эта коробочка находится в стеке. (Подробнее об этом ниже.)
Итак, вы спросили об отдельных байтах и представили себе двухбайтовую int начиная с адреса 2000 . Итак, вот как это будет выглядеть, более подробно. Чтобы подчеркнуть содержимое отдельных байтов, я перейду к шестнадцатеричному формату:
+------+
х: 2000: | 0x7b |
+------+
2001: | 0x00 |
+------+
Вы, наверное, догадались, но это число 0x7b является частью шестнадцатеричного представления 123 . Десятичное число 123 имеет шестнадцатеричное представление 0x007b . Это предполагает двухбайтовое целое число, хотя стоит отметить, что в наши дни большинство машин, которые вы, вероятно, будете использовать, будут использовать четыре байта. Я также показал ситуацию для хранения с прямым порядком байтов, которое сегодня используется большинством машин. Байт с меньшим номером является наименее значащим байтом.
Я также показал ситуацию для хранения с прямым порядком байтов, которое сегодня используется большинством машин. Байт с меньшим номером является наименее значащим байтом.
Поскольку 123 на самом деле просто 7-битное число, оно занимает только один из двух байтов, а другой равен нулю. Чтобы быть действительно уверенными, что мы понимаем, как расположены два байта, предположим, что мы присваиваем x новое значение:
х = 12345;
Шестнадцатеричное представление 12345 равно 0x3039 , поэтому изображение в памяти меняется на это:
+------+
х: 2000: | 0x39 |
+------+
2001: | 0x30 |
+------+
Наконец, для сравнения предположим, что я сказал
long int y = 305419896;
Предположим, что это было на машине с обратным порядком следования байтов. Предположим, что long int составляют четыре байта, и предположим, что компилятор решил поместить y по адресу 3000. Это случайно выглядящее число
Это случайно выглядящее число 305419896 имеет шестнадцатеричное представление 0x12345678 , поэтому ситуация в памяти (опять же, при условии обратного порядка байтов) будет выглядеть так:
+---- --+
г: 3000: | 0x12 |
+------+
3001: | 0x34 |
+------+
3002: | 0x56 |
+------+
3003: | 0x78 |
+------+
При хранении с прямым порядком байтов младший адрес содержит самый старший байт, что означает, что число читается слева направо (здесь сверху вниз) в памяти. Но, как я уже сказал, большинство машин, которые вы, вероятно, будете использовать сегодня, имеют обратный порядок байтов.
Как я уже упоминал, поскольку x в вашем примере является локальной переменной, она обычно хранится в стеке вызовов функций. (Как заметил комментатор, нет никакой гарантии, что в C вообще есть стек, но у большинства он есть, так что давайте исходить из этого предположения.) Чтобы увидеть разницу между локальными и глобальными переменными, а также показать, как парочка других типов данных хранится, давайте посмотрим на немного больший пример и давайте расширим наши возможности, чтобы представить себе всю память. Предположим, я пишу
Предположим, я пишу
целое г = 456;
char s[] = "привет";
интервал основной () {
инт х = 123;
char s2[] = "мир";
символ *р = с;
}
Обычно глобальные переменные хранятся в нижней части памяти, а стек хранится «вверху» и растет вниз. Таким образом, мы можем представить, как выглядит память нашего компьютера. Как вы увидите, я изменил соглашение, которое использовал на предыдущей картинке. На этом рисунке адреса памяти идут от до страницы. (Кроме того, адреса памяти теперь тоже в шестнадцатеричном формате, и я опускаю 0x обозначение. Также я возвращаюсь к прямому порядку байтов, но сохраняю понятие 16-битной машины. Также я собираюсь показать значения символов сами по себе, а не в шестнадцатеричном формате. Также я показываю неизвестные байты как ?? .)
+------+
ффек: | ?? |
+------+
ффеб: | 00 |
+------+
х: ffea: | 7б |
+------+
ffe9: | 00 |
+------+
ffe8: | 'д' |
+------+
ffe7: | 'л' |
+------+
ffe6: | 'р' |
+------+
ffe5: | 'о' |
+------+
s2: ffe4: | 'ш' |
+------+
ffe3: | 02 |
+------+
р: ffe2: | 80 |
+------+
ffe1: | ?? |
+------+
.
.
.
+------+
0282: | ?? |
+------+
0281: | 00 |
+------+
0280: | 'о' |
+------+
0283: | 'л' |
+------+
0282: | 'л' |
+------+
0281: | 'е' |
+------+
с: 0280: | 'ч' |
+------+
0283: | 01 |
+------+
г: 0282: | с8 |
+------+
0281: | ?? |
+------+
 .
.
+------+
0282: | ?? |
+------+
0281: | 00 |
+------+
0280: | 'о' |
+------+
0283: | 'л' |
+------+
0282: | 'л' |
+------+
0281: | 'е' |
+------+
с: 0280: | 'ч' |
+------+
0283: | 01 |
+------+
г: 0282: | с8 |
+------+
0281: | ?? |
+------+
.
.
+------+
0282: | ?? |
+------+
0281: | 00 |
+------+
0280: | 'о' |
+------+
0283: | 'л' |
+------+
0282: | 'л' |
+------+
0281: | 'е' |
+------+
с: 0280: | 'ч' |
+------+
0283: | 01 |
+------+
г: 0282: | с8 |
+------+
0281: | ?? |
+------+
Конечно, это сильное упрощение, но оно должно дать вам основную идею, и я по-прежнему считаю полезным думать об этом таким образом, несмотря на все эзотерические возможные сложности, которые обсуждают комментаторы. Следующим шагом может быть демонстрация того, как выглядит память malloc ‘ed, и как обстоят дела, когда у нас есть несколько активных вызовов функций в стеке, но этот ответ становится слишком длинным, поэтому мы отложим его на другой день. .
Как переменные в C++ сохраняют свой тип?
Переменная имеет ряд основных свойств в таком языке, как C:
- Имя
- Тип А
- Прицел
- Целая жизнь
- Местоположение
- Значение
В вашем исходном коде местоположение (5) является концептуальным, и это местоположение упоминается по его имени (1). Таким образом, объявление переменной используется для создания местоположения и места для значения (6), а в других строках исходного кода мы ссылаемся на это местоположение и значение, которое оно содержит, называя переменную в некотором выражении.
Таким образом, объявление переменной используется для создания местоположения и места для значения (6), а в других строках исходного кода мы ссылаемся на это местоположение и значение, которое оно содержит, называя переменную в некотором выражении.
Только несколько упрощая, после того, как ваша программа транслируется компилятором в машинный код, ячейка (5) представляет собой некоторую ячейку памяти или регистра ЦП, и любые выражения исходного кода, которые ссылаются на переменную, преобразуются в последовательности машинного кода, которые ссылаются это место в памяти или регистре ЦП.
Таким образом, когда трансляция завершена и программа работает на процессоре, имена переменных фактически забываются в машинном коде, и инструкции, сгенерированные компилятором, относятся только к назначенным местоположениям переменных (а не к своим именам). Если вы выполняете отладку и запрашиваете отладку, местоположение переменной, связанной с именем, добавляется в метаданные программы, хотя процессор по-прежнему видит инструкции машинного кода с использованием местоположений (а не метаданных). (Это чрезмерное упрощение, так как некоторые имена находятся в метаданных программы для целей компоновки, загрузки и динамического поиска — тем не менее процессор просто выполняет инструкции машинного кода, которые ему даются для программы, и в этом машинном коде имена имеют были преобразованы в локации.)
(Это чрезмерное упрощение, так как некоторые имена находятся в метаданных программы для целей компоновки, загрузки и динамического поиска — тем не менее процессор просто выполняет инструкции машинного кода, которые ему даются для программы, и в этом машинном коде имена имеют были преобразованы в локации.)
То же самое верно для типа, области действия и времени жизни. Инструкции машинного кода, сгенерированные компилятором, знают машинную версию местоположения, в котором хранится значение. Другие свойства, такие как тип, компилируются в переведенный исходный код как конкретные инструкции, которые обращаются к местоположению переменной. Например, если рассматриваемая переменная представляет собой 8-битный байт со знаком, а не 8-битный байт без знака, то выражения в исходном коде, которые ссылаются на переменную, будут преобразованы, скажем, в загрузку байтов со знаком и загрузку байтов без знака. столько, сколько необходимо для удовлетворения правил языка (C). Таким образом, тип переменной кодируется в преобразовании исходного кода в машинные инструкции, которые сообщают ЦП, как интерпретировать расположение памяти или регистра ЦП каждый раз, когда он использует расположение переменной.
Суть в том, что мы должны сказать процессору, что делать, с помощью инструкций (и других инструкций) в наборе инструкций машинного кода процессора. Процессор очень мало помнит о том, что он только что сделал или что ему сказали — он только выполняет данные инструкции, и задачей компилятора или программиста на ассемблере является предоставление ему полного набора последовательностей инструкций для правильного управления переменными.
Процессор напрямую поддерживает некоторые основные типы данных, такие как byte/word/int/long signed/unsigned, float, double и т. д. Процессор, как правило, не будет жаловаться или возражать, если вы попеременно обрабатываете одну и ту же ячейку памяти как подписанную или беззнаковую. , например, хотя обычно это была бы логическая ошибка в программе. Задача программирования состоит в том, чтобы инструктировать процессор при каждом взаимодействии с переменной.
Помимо этих фундаментальных примитивных типов, мы должны кодировать вещи в структурах данных и использовать алгоритмы для манипулирования ими в терминах этих примитивов.
