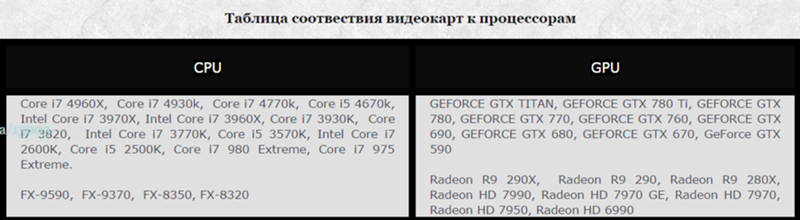
Таблица сбалансированных пар gpu cpu: Таблица совместимости процессор/видеокарты
Содержание
GPU vs CPU, сравнительный анализ. Почему GPU быстрее?
Автор: Серженко Фёдор
I. Введение
За последнее десятилетие технологическое развитие графических процессоров продвинулось настолько далеко, что они могут с успехом конкурировать с традиционными решениями (например, с центральными процессорами) и применяться для широкого спектра задач, в том числе связанных с быстрой обработкой изображений.
В данной статье пойдёт речь о возможностях графического и центрального процессоров выполнять задачи быстрой обработки изображений. Мы проведём сравнение двух типов процессоров и покажем преимущества GPU перед CPU, ответим на вопрос почему обработка изображений на GPU может быть более эффективной по сравнению с аналогичными решениями на CPU.
Кроме того, мы рассмотрим часто встречающиеся заблуждения пользователей и разработчиков, которые мешают им использовать GPU для быстрой обработки изображений.
II. Особенности алгоритмов быстрой обработки изображений
Для целей нашей статьи из всего многообразия алгоритмов быстрой обработки изображений мы возьмём только те, которые обладают такими характеристиками, как локальность, возможность распараллеливания и их относительная простота. Поясним более подробно, что мы имеем в виду:
Поясним более подробно, что мы имеем в виду:
- Локальность. Каждый пиксел вычисляется на основе ограниченного количества соседей.
- Высокая способность к распараллеливанию. Каждый пиксел не зависит по данным от других обработанных пикселей, что позволяет распараллелить процесс обработки.
- 16/32-битная точность арифметики. Как правило, при обработке изображений достаточно 32-битной вещественной (floating point) арифметики для обработки и 16-битного целочисленного типа данных для хранения.
Критерии, которые важны для быстрой обработки изображений
Ключевыми критериями, важными для быстрой обработки изображений, являются:
1. Производительность
Как показывает практика, максимальной производительности можно добиться двумя способами — либо через увеличение аппаратных ресурсов, то есть с помощью наращивания количества процессоров, либо через оптимизацию программного кода. При сравнении возможностей графического процессора и центрального, в этом классе задач GPU выигрывает у CPU в соотношении цена/производительность, а реализация всего потенциала GPU возможна лишь при распараллеливании и тщательной многоуровневой оптимизации используемых алгоритмов.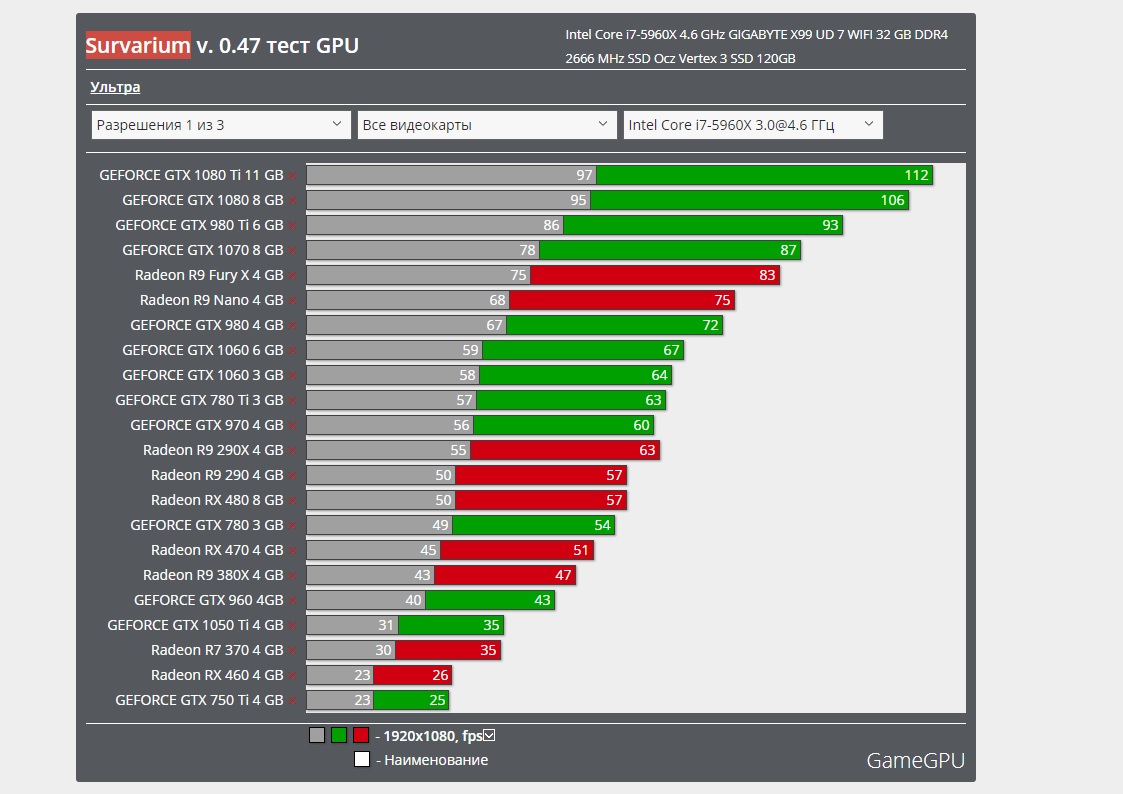
2. Качество обработки изображений
Еще одним важным критерием является качество обработки изображений. Для одной и той же операции обработки изображений может существовать несколько алгоритмов, отличающихся ресурсоёмкостью и качеством получаемого результата. И тут важно понимать, что обычно ресурсоёмкие алгоритмы дают более качественный результат. Таким образом, многоуровневая оптимизация наиболее востребована для ресурсоёмких алгоритмов. После её выполнения сложные алгоритмы могут выдавать результат за приемлемое время, сравнимое со временем работы изначально быстрого, но более грубого алгоритма.
3. Латентность
Как уже говорилось выше, GPU имеет такую архитектуру, которая позволяет осуществлять параллельную обработку пикселов изображения, что приводит к сокращению латентности, или времени обработки одного изображения. Центральные процессоры обладают довольно скромными показателями латентности, поскольку в CPU параллелизм реализуется на уровне отдельных кадров, тайлов или строк изображений.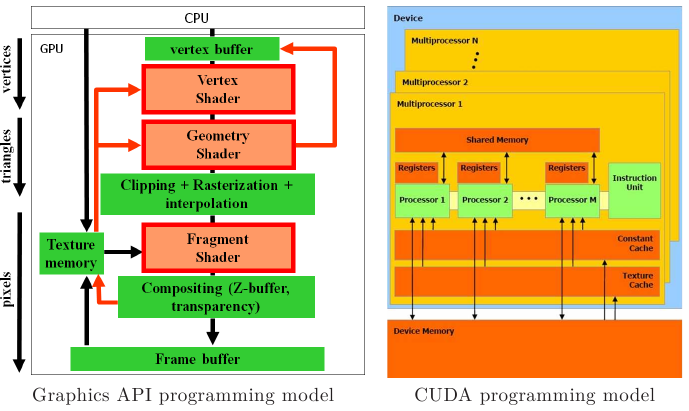
III. Ключевые отличия между GPU и CPU
1. Количество потоков на CPU и GPU
Архитектура центральных процессоров предполагает, что каждое физическое ядро на CPU может выполнять 2 потока вычислений при наличии 2 виртуальных ядер. В этом случае каждый поток выполняет инструкции независимо. В то же время количество потоков GPU в сотни раз больше, так как в этих процессорах используется программная модель SIMT (Single instruction, multiple threads). В этом случае группа потоков (обычно их 32) выполняет одну и ту же инструкцию. Таким образом, именно такую группу можно рассматривать в качестве эквивалента CPU потока, поэтому эту группу назвают истинным GPU потоком.
2. Способ реализации потоков на CPU и GPU
Ещё одним отличием GPU и CPU является то, как они скрывают латентность инструкций. CPU для этих целей использует внеочередное исполнение, а GPU использует ротацию истинных потоков, каждый раз запуская инструкции из разных потоков. Способ, используемый на GPU, является более эффективным при аппаратной реализации, но при этом необходимо, чтобы алгоритм был параллельным и нагрузка была высокой.
Из всего этого можно сделать вывод, что многие алгоритмы обработки изображений идеально подходят для реализации на GPU.
IV. Преимущества GPU над CPU
- Наши лабораторные исследования показали, что при сравнении идеально оптимизированного софта для GPU и для CPU (с применением AVX2), преимущество GPU имеет глобальный характер: пиковые производительности CPU и GPU аналогичного года производства отличаются обычно на порядок для 32- и 16-битных типов данных. Также на порядок отличается и пропускная способность подсистемы памяти. В следующих пунктах мы рассмотрим эту ситуацию подробнее.
- Если же использовать для сравнения софт для CPU без использования инструкций AVX2, то разница в производительности может достигать 50-100 раз в пользу GPU.
- Все современные GPU оснащены разделяемой памятью, которая одновременно доступна всем «вычислителям» одного мультипроцессора, что, по сути, является программно-управляемым кэшем.
 Он идеально подходит для алгоритмов с высокой степенью локальности. Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU.
Он идеально подходит для алгоритмов с высокой степенью локальности. Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU. - Ещё одной важной особенностью GPU по сравнению с CPU является то, что количество доступных регистров можно менять динамически (от 64 до 256 на один поток), тем самым позволяя снижать нагрузку на подсистему памяти. Для сравнения, в архитектурах x86 и х64 используется 16 универсальных регистров и 16 AVX регистров на один поток.
- Наличие нескольких специализированных аппаратных модулей на GPU для одновременной работы над совершенно разными задачами: аппаратная обработка изображений (ISP) на Jetson, асинхронное копирование в GPU и обратно, вычисления на GPU, аппаратное кодирование и декодирование видео (NVENC, NVDEC), тензорные ядра для нейросетей, OpenGL, DirectX, Vulkan для визуализации.
 Он идеально подходит для алгоритмов с высокой степенью локальности. Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU.
Он идеально подходит для алгоритмов с высокой степенью локальности. Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU.Но, как результат всех перечисленных выше преимуществ GPU перед CPU, за всё это приходится платить высокими требованиями к параллельности алгоритмов. Если для максимальной загрузки CPU достаточно десятков потоков, то для полной загрузки GPU нужны десятки тысяч потоков.
Если для максимальной загрузки CPU достаточно десятков потоков, то для полной загрузки GPU нужны десятки тысяч потоков.
Встраиваемые (embedded) приложения
Следует помнить и о таком типе задач, как встраиваемые решения. Здесь GPU уже конкурируют со специализированными устройствами, такими как FPGA (программируемая пользователем вентильная матрица) и ASIC (интегральная схема специального назначения). Основным преимуществом GPU перед прочими решениями является их существенно большая гибкость. Для отдельных встраиваемых решений GPU может быть серьёзной альтернативой, так как мощные многоядерные процессоры не проходят по допустимым требованиям к размеру и энергопотреблению.
V. Заблуждения пользователей и разработчиков
1. У пользователей нет опыта работы с GPU, поэтому они пытаются многое сделать на CPU
Одно из ключевых заблуждений пользователей и разработчиков связано с тем, что ещё не так давно графические процессоры считались мало подходящими для высокопроизводительных вычислительных задач. Но технологии развиваются стремительно. И несмотря на то, что обработка изображений на GPU хорошо интегрируется с CPU обработкой, наилучшие результаты достигаются в тех случаях, когда быстрая обработка изображений осуществляется на GPU. На сегодняшний день есть огромное количество таких приложений.
Но технологии развиваются стремительно. И несмотря на то, что обработка изображений на GPU хорошо интегрируется с CPU обработкой, наилучшие результаты достигаются в тех случаях, когда быстрая обработка изображений осуществляется на GPU. На сегодняшний день есть огромное количество таких приложений.
2. Многократное копирование данных на GPU и обратно «убивает» производительность
Среди пользователей и разработчиков существует и такое предубеждение относительно обработки изображений на GPU. И здесь, как оказалось, это тоже всего лишь неверная интерпретация, поскольку надёжным решением в этом случае является реализация всей схемы обработки на GPU в рамках одной задачи. Исходные данные могут быть скопированы на GPU, а обратно на CPU отдаются только результаты расчётов. Таким образом, все промежуточные данные остаются на GPU. Кроме того, копирования могут выполняться асинхронно, в одно и то же время с вычислениями над предыдущим кадром.
3. Размер разделяемой памяти составляет 96 кБайт на каждый мультипроцессор, что очень мало
Несмотря на малый размер разделяемой памяти GPU в 96 кБайт, при экономичном подходе к управлению разделяемой памятью, этого объёма может хватить в полной мере. Именно в этом и состоит суть оптимизации ПО для CUDA/OpenCL. То есть нельзя просто перенести код с CPU на GPU, не принимая во внимание все особенности архитектуры GPU.
Именно в этом и состоит суть оптимизации ПО для CUDA/OpenCL. То есть нельзя просто перенести код с CPU на GPU, не принимая во внимание все особенности архитектуры GPU.
4. Недостаточный размер глобальной памяти GPU для решения сложных задач
Это существенный момент, который, с одной стороны, решают производители, выпуская новые видеокарты с увеличенным размером памяти. С другой стороны, возможны программные решения по управлению памятью для её повторного использования.
5. Библиотеки по обработке на CPU тоже используют параллельные вычисления
Действительно, у CPU есть возможности по параллельной работе в рамках векторных операций типа AVX и многопоточности (например, через OpenMP). Но в большинстве случаев распараллеливание происходит самым простым способом: каждый кадр обрабатывается в отдельном потоке, а сам код обработки одного кадра остаётся последовательным. Использование векторных инструкций сталкивается со сложностью написания и поддержки кода для разных архитектур, моделей процессоров и систем. Оптимизация кода в библиотеках конкретных вендоров, например, Intel IPP, находится на высоком уровне. Проблемы возникают тогда, когда нужный функционал отсутствует в библиотеках и приходится использовать сторонние открытые или проприетарные библиотеки, где оптимизация может отсутствовать.
Оптимизация кода в библиотеках конкретных вендоров, например, Intel IPP, находится на высоком уровне. Проблемы возникают тогда, когда нужный функционал отсутствует в библиотеках и приходится использовать сторонние открытые или проприетарные библиотеки, где оптимизация может отсутствовать.
Еще одним аспектом, который плохо сказывается на производительности массовых библиотек, является широкое распространение облачных вычислений. В большинстве случаев для разработчика значительно дешевле докупить мощности в облаке по запросу, чем заниматься развитием оптимизированных библиотек. Заказчики требуют ускорить выход готового продукта на рынок, потому разработчики вынуждены использовать относительно простые и не самые эффективные решения.
Тем не менее, современные промышленные камеры генерируют видеопотоки очень высокой интенсивности, которые часто исключают возможность передачи данных для обработки по сети в облако, поэтому для обработки видеопотока с таких камер обычно используются локальные ПК. Компьютер, используемый для вычислений, должен обладать требуемой производительностью для обработки, и, что важно по сравнению с облачным подходом, его необходимо приобрести на начальных этапах реализации решения. Производительность решения зависит как от аппаратного, так и от программного обеспечения. При планировании решения следует учитывать и то, какое аппаратное обеспечение используется. Если удаётся обойтись широко распространёнными аппаратными средствами, проблем не возникает, и можно использовать любое программное обеспечение. Как только возникает необходимость использования более дорогого оборудования, цена единицы производительности начинает быстро увеличиваться и это создает предпосылки для использования оптимизированного ПО.
Компьютер, используемый для вычислений, должен обладать требуемой производительностью для обработки, и, что важно по сравнению с облачным подходом, его необходимо приобрести на начальных этапах реализации решения. Производительность решения зависит как от аппаратного, так и от программного обеспечения. При планировании решения следует учитывать и то, какое аппаратное обеспечение используется. Если удаётся обойтись широко распространёнными аппаратными средствами, проблем не возникает, и можно использовать любое программное обеспечение. Как только возникает необходимость использования более дорогого оборудования, цена единицы производительности начинает быстро увеличиваться и это создает предпосылки для использования оптимизированного ПО.
Задача обработки данных с промышленных видеокамер характеризуется постоянной нагрузкой. Уровень нагрузки определяется набором применяемых алгоритмов и количеством данных в единицу времени. Система обработки изображений должна быть рассчитана на начальных этапах проекта, чтобы с гарантированным запасом справляться с данной нагрузкой, иначе обработка без потери данных будет невозможна. Это является ключевым отличием от web-систем, где нагрузка неравномерна.
Это является ключевым отличием от web-систем, где нагрузка неравномерна.
VI. Заключение
Итак, подводя итоги всего вышесказанного, мы приходим к следующим выводам.
1. GPU является прекрасной альтернативой CPU для решения сложных задач по быстрой обработке изображений.
2. Производительность оптимизированных решений для обработки изображений на GPU намного выше, чем на CPU. В качестве подтверждения мысли, мы предлагаем вам обратиться к другой статье из блога Fastvideo, в которой описаны бенчмарки на разных GPU для часто используемых алгоритмов обработки и сжатия изображений.
3. GPU обладает архитектурой, благодаря которой осуществляется параллельная обработка пикселов изображения, что, в свою очередь, приводит к сокращению времени обработки одного изображения (латентности).
4. Стоимость владения системами обработки изображений на основе GPU, оказывается ниже чем у систем, использующих только CPU. Высокая производительность GPU позволяет уменьшить количество единиц оборудования в таких системах, а высокая энергоэффективность снизить потребление электричества.
5. GPU обладает необходимой гибкостью, высокой производительностью, низким энергопотреблением для того, чтобы конкурировать с узкоспециализированными решениями типа FPGA/ASIC для использования в мобильных и встраиваемых решениях.
6. Объединение возможностей CUDA/OpenCL и аппаратных тензорных ядер позволяет значительно увеличить производительность для задач с применением нейросетей.
Приложение №1
Сравнение пиковой производительности CPU и GPU на примере NVIDIA
Сравнение выполним на типе float (32-битный вещественный тип). Этот тип отлично подходит для обработки изображений. Оценивать производительность будем для одного ядра. В случае с CPU всё просто, речь идет о производительности одного физического ядра. Для GPU всё несколько сложнее. То, что принято называть у GPU ядром – это по сути своей АЛУ, или, в терминологии NVIDIA – SP (Streaming Processor). Реальными аналогом CPU ядра является стриминговый мультипроцессор (в терминологии NVIDIA, Streaming Multiprocessor, SM). Количество стриминговых процессоров в одном мультипроцессоре зависит от семейства GPU. Например, видеокарты NVIDIA Turing содержат 64 SP в одном SM, а у NVIDIA Ampere их 128. За каждый такт один SP может выполнять одну инструкцию FMA (Fused Multiply–Add). Инструкция FMA выбрана здесь для сравнения, так как она используется для реализации свёртки в фильтрах. Её целочисленный аналог называется MAD. Инструкция (один из вариантов) выполняет следующее действие: B=AX+B, где B – аккумулятор, накапливающий значения свёртки, A – коэффициент фильтра, X – значение пиксела. Сама по себе такая инструкция выполняет два операции: умножение и суммирование. Это даёт нам производительность за такт для SM: Turing — 2*64 =128 FLOP, Ampere — 2*128 = 256 FLOP
Количество стриминговых процессоров в одном мультипроцессоре зависит от семейства GPU. Например, видеокарты NVIDIA Turing содержат 64 SP в одном SM, а у NVIDIA Ampere их 128. За каждый такт один SP может выполнять одну инструкцию FMA (Fused Multiply–Add). Инструкция FMA выбрана здесь для сравнения, так как она используется для реализации свёртки в фильтрах. Её целочисленный аналог называется MAD. Инструкция (один из вариантов) выполняет следующее действие: B=AX+B, где B – аккумулятор, накапливающий значения свёртки, A – коэффициент фильтра, X – значение пиксела. Сама по себе такая инструкция выполняет два операции: умножение и суммирование. Это даёт нам производительность за такт для SM: Turing — 2*64 =128 FLOP, Ampere — 2*128 = 256 FLOP
Современные CPU обладают возможностью за каждый такт выполнять 2 инструкции FMA из набора AVX2. Каждая такая инструкция содержит 8 float операндов и соответственно 16 операций (FLOP). Итого, одно CPU ядро выполняет 2*16=32 FLOP за такт.
Чтобы перейти к производительности в единицу времени, нужно умножить количество инструкций за такт на частоту устройства. В среднем, частота GPU находится в диапазоне 1.5–1.9 ГГц, а CPU при нагрузке на все ядра имеет частоту 3.5–4.5 ГГц. Инструкция FMA из набора AVX2 является сложной для CPU. При её исполнении участвует большое количество устройств и сильно возрастает тепловыделение. Это приводит к тому, что CPU вынужден снижать частоту, чтобы избежать перегрева. Для разных семейств CPU величина снижения частоты разная. Например, по этой статье можно оценить снижение до уровня 0.7 от полной. Далее будем брать коэффициент 0.8, он соответствует более новым поколениям CPU.
В среднем, частота GPU находится в диапазоне 1.5–1.9 ГГц, а CPU при нагрузке на все ядра имеет частоту 3.5–4.5 ГГц. Инструкция FMA из набора AVX2 является сложной для CPU. При её исполнении участвует большое количество устройств и сильно возрастает тепловыделение. Это приводит к тому, что CPU вынужден снижать частоту, чтобы избежать перегрева. Для разных семейств CPU величина снижения частоты разная. Например, по этой статье можно оценить снижение до уровня 0.7 от полной. Далее будем брать коэффициент 0.8, он соответствует более новым поколениям CPU.
Условно можно считать, что CPU по частоте в 2.5 раза быстрее GPU. С учётом коэффициента снижения частоты при работе с AVX2 инструкциями получим 2.5*0.8 = 2. Итого, относительная производительность в FLOP для инструкции FMA при сравнении с CPU ядром получим: Turing SM = 128 / (2.0*32) = 2 раза, а для Ampere SM это 256 / (2.0*32) = 4 раза, т.е. один SM лучше, чем одно ядро CPU.
Оценим производительность L1 для CPU ядра. Современные СPU могут выполнять загрузку двух 256-битных регистров из кэша L1 параллельно или 64 байта за такт. GPU обладает унифицированным блоком разделаяемой памяти/L1. Производительность блока одинакова для двух архитектур и составляет 32 float за такт, или 128 байт за такт. Воспользовавшись соотношением частот, получим отношение производительностей 128 (байт за такт) / (2 (частота CPU больше GPU) * 64 (байт за такт)) = 1.
GPU обладает унифицированным блоком разделаяемой памяти/L1. Производительность блока одинакова для двух архитектур и составляет 32 float за такт, или 128 байт за такт. Воспользовавшись соотношением частот, получим отношение производительностей 128 (байт за такт) / (2 (частота CPU больше GPU) * 64 (байт за такт)) = 1.
Также сравним размеры L1 и разделяемой памяти для CPU и GPU. Для CPU стандартным размером кэша данных L1 является 32 кБайт. Turing SM имеет 96 кБайт, а у Ampere SM имеется 128 кБайт разделяемой памяти.
Для оценки общий производительности определимся с количеством ядер на SP. Для настольных CPU рассмотрим вариант из 16 ядер (AMD Ryzen, Intel i9), у GPU (NVIDIA Quadro RTX 6000) имеется 72 SP. Итого отношение по количеству ядер 72/16 = 4.5. Таким образом, для этой пары CPU/GPU пропускная способность L1 и разделяемой памяти отличается в 1 * 4.5 = 4.5 раза.
На основе этого рассчитаем общую производительность по float. Для топовых видеокарт Turing получаем: 4. 5 (отношение по количеству ядер GPU/CPU) * 2 (отношение производительности SM к производительности одного ядра CPU) = 9 раз.
5 (отношение по количеству ядер GPU/CPU) * 2 (отношение производительности SM к производительности одного ядра CPU) = 9 раз.
Для видеокарт Ampere (NVIDIA Quadro RTX A6000, у которой 84 SP) получаем: 4.5 (отношение по количеству ядер GPU/CPU) * 4 (отношение производительности SM к производительности одного ядра CPU) *84/72 = 21 раз.
Мы получили численную оценку, которая отражает существенное преимущество GPU над CPU как по производительности, так и по скорости доступа к быстрой памяти в расчётах, связанных с обработкой изображений.
Тут очень важно напомнить, что указанные соотношения получаются для CPU только при использовании AVX2 инструкций. В случае использовании скалярных инструкций, производительность CPU ядра снижается в 8 раз, как по арифметическим операциям, так и по скорости обращения к памяти. Поэтому для современных CPU особую важность приобретает оптимизация программного кода.
Скажем пару слов и о новым наборе AVX-512 для CPU. Это следующее поколение SIMD инструкций с увеличенной до 512 бит длиной вектора. Ожидается удвоение производительности в будущем по сравнению с AVX2. Современные версии CPU обеспечивают реальное преимущество до 1.6 раз, так как требуют ещё большего снижения частоты, чем инструкции из набора AVX2. Набор AVX-512 пока не получил широкого распространения в массовом сегменте, но это скорее всего произойдёт в будущем. Минусами этого подхода станут необходимость адаптации алгоритмов на новую длину вектора и перекомпиляция кода для поддержки.
Это следующее поколение SIMD инструкций с увеличенной до 512 бит длиной вектора. Ожидается удвоение производительности в будущем по сравнению с AVX2. Современные версии CPU обеспечивают реальное преимущество до 1.6 раз, так как требуют ещё большего снижения частоты, чем инструкции из набора AVX2. Набор AVX-512 пока не получил широкого распространения в массовом сегменте, но это скорее всего произойдёт в будущем. Минусами этого подхода станут необходимость адаптации алгоритмов на новую длину вектора и перекомпиляция кода для поддержки.
Попробуем сравнить пропускную способность системной памяти. Тут тоже можно увидеть значительный разброс значений. Для CPU начальные цифры – это 50 ГБайт/с (2-канальный контроллер DDR4 3200) для массовых CPU. В сегменте для рабочих станций доминирует CPU с четырёхканальными контроллерами – это 100 ГБайт/с. Для серверов можно встретить CPU с 6-8 канальными контроллерами и производительностью более 150 ГБайт/с.
У GPU значение пропускной способности глобальной памяти тоже находится в широком диапазоне. Начиная от 450 ГБайт/с у модели Quadro RTX 5000, и заканчивая 1550 ГБайт/с у старшей модели A100. В итоге можно сказать, что пропускная способность в сопоставимых сегментах отличается значительно, вплоть до разницы на порядок.
Начиная от 450 ГБайт/с у модели Quadro RTX 5000, и заканчивая 1550 ГБайт/с у старшей модели A100. В итоге можно сказать, что пропускная способность в сопоставимых сегментах отличается значительно, вплоть до разницы на порядок.
Из всего вышесказанного можно сделать вывод, что GPU существенно (иногда практически на порядок) превосходит CPU, который выполняет оптимизированный код. В случае неоптимизированного для CPU кода, разница по производительности может быть ещё больше, до 50–100 раз. Все это создаёт серьёзные предпосылки для увеличения производительности в реальных задачах.
Приложение №2 — алгоритмы memory-bound и compute bound
Когда мы говорим об этих типах алгоритмов, необходимо понимать, что речь идёт о конкретной реализации алгоритма на конкретной архитектуре. У каждого процессора есть некоторая пиковая арифметическая производительность. Если реализация алгоритма может на целевом участке достигнуть пиковой производительности процессора по вычислительным инструкциям, то тогда она compute-bound, в противном случае основным ограничением станет память и реализация memory-bound.
Подсистема памяти у всех процессоров является иерархической, состоящий из нескольких уровней. Чем уровень ближе к процессору, тем он меньше по объёму и тем он быстрее. На первом уровне находится кэш данных первого уровня, а на последнем уровне оперативная память.
Алгоритм может быть изначально compute-bound на первом уровне иерархии, а затем стать memory-bound на более высоких уровнях иерархии.
Рассмотрим несколько примеров. Допустим, мы хотим сложить два массива и записать результат в третий. Можно записать это как X = Y + Z, где X, Y, Z – массивы. Допустим, мы воспользуемся инструкциями AVX для реализации на процессоре. Тогда на один элемент нам потребуется два чтения, одно суммирование и одна запись. Современный CPU может выполнить два чтения и одну запись одновременно в кэш L1. Но вместе с тем, он может выполнить и две арифметические инструкции, а мы можем воспользоваться только одной. Это значит, что алгоритм суммирования массивов является memory-bound уже на первом уровне иерархии памяти.
Рассмотрим второй алгоритм. Фильтрация изображения в окне 3×3. Фильтрация изображения основана на операции свёртки окрестности пиксела с коэффициентами фильтра. Для вычисления свёртки используется инструкция MAD (или FMA в зависимости от архитектуры). Для окна 3×3 потребуется 9 таких инструкций. Операция инструкции B = AX + B, где B – аккумулятор, накапливающий значения свёртки, A – коэффициент фильтра, X – значение пиксела. Значения A и B находятся в регистрах, а значения пиксела загружаются из памяти. В этом случае на одну инструкцию FMA требуется одна загрузка. Здесь CPU сможет за счёт двух загрузок снабжать данными два порта FMA и полностью загрузит процессор. Алгоритм можно считать compute-bound.
Давайте рассмотрим этот же алгоритм на уровне доступа к оперативной памяти. Возьмём самую экономную по памяти реализацию, когда одно чтение пиксела обновляет все окна в которые он входит. В этом случае на одну операцию чтения будет приходиться 9 инструкций FMA. Таким образом, одно ядро CPU при обработке float данных на частоте 4 ГГц потребует 2 (инструкции за такт) × 8 (float в AVX регистре) × 4 (Байта в float) × 4 (ГГц) / 9 = 28.5 ГБайт/с. Двухканальный контролер с DDR4-3200 имеет пиковую пропускную способность в 50 ГБайт/с и по расчётам он способен быть источником данных только для двух CPU ядер в этой задаче. Поэтому такой алгоритм, запущенный на 8–16 ядерном процессоре является memory-bound. Несмотря на то, что на нижнем уровне он сбалансирован.
Таким образом, одно ядро CPU при обработке float данных на частоте 4 ГГц потребует 2 (инструкции за такт) × 8 (float в AVX регистре) × 4 (Байта в float) × 4 (ГГц) / 9 = 28.5 ГБайт/с. Двухканальный контролер с DDR4-3200 имеет пиковую пропускную способность в 50 ГБайт/с и по расчётам он способен быть источником данных только для двух CPU ядер в этой задаче. Поэтому такой алгоритм, запущенный на 8–16 ядерном процессоре является memory-bound. Несмотря на то, что на нижнем уровне он сбалансирован.
Теперь рассмотрим этот же алгоритм при реализации на GPU. Сразу видно, что GPU имеет на уровне SM менее сбалансированную архитектуру с уклоном в вычисления. Для архитектуры Turing отношение скорости арифметических операций (во float) к скорости загрузки из Shared Memory – 2:1, для Ampere 4:1. За счёт большего количества регистров на GPU можно реализовать указанную выше оптимизацию для CPU напрямую на регистрах GPU. Это позволяет сбалансировать алгоритм даже для Ampere. И на уровне Shared Memory реализация остается compute-bound. С точки зрения памяти верхнего уровня (глобальной) расчёт для Quadro RTX 5000 (Turing) даёт следующие результаты: 64 (операций за такт) × 4 (Байт в float) × 1.7 (ГГц) / 9 = 48.3 ГБайт/с на один SM. Отношение общей пропускной способности к пропускной способности SM составит 450 / 48.3 = 9.3 раза. Общее количество SM в Quadro RTX 5000 равно 48. Т.е. и для GPU алгоритм фильтрации на высоком уровне является memory-bound.
С точки зрения памяти верхнего уровня (глобальной) расчёт для Quadro RTX 5000 (Turing) даёт следующие результаты: 64 (операций за такт) × 4 (Байт в float) × 1.7 (ГГц) / 9 = 48.3 ГБайт/с на один SM. Отношение общей пропускной способности к пропускной способности SM составит 450 / 48.3 = 9.3 раза. Общее количество SM в Quadro RTX 5000 равно 48. Т.е. и для GPU алгоритм фильтрации на высоком уровне является memory-bound.
По мере роста размера окна алгоритм становится всё более сложным и соответственно смещается в сторону compute-bound. Большинство алгоритмов обработки изображений являются memory-bound на уровне глобальной памяти. И так как пропускная способность памяти GPU во многих случаях на порядок больше чем у CPU, то это обеспечивает сопоставимый прирост производительности.
Приложение №3
Программные модели SIMD и SIMT, или почему у GPU так много потоков
Для повышения производительности CPU используются SIMD (single instruction, multiple data) инструкции.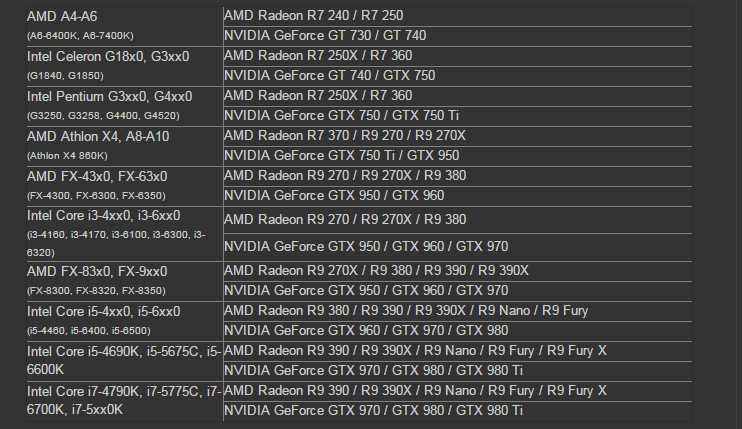 Одна такая инструкция позволяет выполнить несколько однотипных операций над вектором данных. Плюсом этого подхода является рост производительности без существенной модификации instruction pipeline. Все современные CPU, как x86, так и ARM, имеют SIMD инструкции. Минусом данного подхода является сложность программирования. Основной подход к SIMD программированию — это использование intrinsic. Intrinsic – это встроенные функции компилятора, которые содержат одну или несколько SIMD-инструкций, плюс инструкции для подготовки параметров. Intrinsic формируют низкоуровневый язык, очень близкий к ассемблеру, который крайне трудоёмок в использовании. Кроме того, для каждого набора инструкций у каждого компилятора есть свой набор Intrinsic. Выходит новый набор инструкций – нужно всё переписывать, переходим на новую платформу (с x86 на ARM) нужно переписывать, переходим на другой компилятор — опять нужно всё переписывать.
Одна такая инструкция позволяет выполнить несколько однотипных операций над вектором данных. Плюсом этого подхода является рост производительности без существенной модификации instruction pipeline. Все современные CPU, как x86, так и ARM, имеют SIMD инструкции. Минусом данного подхода является сложность программирования. Основной подход к SIMD программированию — это использование intrinsic. Intrinsic – это встроенные функции компилятора, которые содержат одну или несколько SIMD-инструкций, плюс инструкции для подготовки параметров. Intrinsic формируют низкоуровневый язык, очень близкий к ассемблеру, который крайне трудоёмок в использовании. Кроме того, для каждого набора инструкций у каждого компилятора есть свой набор Intrinsic. Выходит новый набор инструкций – нужно всё переписывать, переходим на новую платформу (с x86 на ARM) нужно переписывать, переходим на другой компилятор — опять нужно всё переписывать.
Программная модель для GPU называется SIMT (Single instruction, multiple threads). Одна инструкция синхронно исполняется в нескольких потоках. Этот подход можно считать развитием SIMD. Скалярная программная модель скрывает векторную суть машины, автоматизируя и упрощая многие операции. Именно поэтому для большинства программистов писать привычный скалярный код на SIMT проще, чем векторный на чистом SIMD.
Одна инструкция синхронно исполняется в нескольких потоках. Этот подход можно считать развитием SIMD. Скалярная программная модель скрывает векторную суть машины, автоматизируя и упрощая многие операции. Именно поэтому для большинства программистов писать привычный скалярный код на SIMT проще, чем векторный на чистом SIMD.
CPU и GPU по-разному решают вопрос латентности инструкций при исполнении их на конвейере. Латентность инструкции – это через сколько тактов следующая инструкция может воспользоваться её результатами. Например, если латентность инструкции равна 3 и CPU может запускать 4 таких инструкции за такт, то за 3 такта процессор запустит 2 зависимых инструкции или 12 независимых. Чтобы избежать такого существенного простоя, все современные процессоры используют внеочередное исполнение инструкций. В этом случае процессор в заданном окне CPU анализирует зависимости инструкций и запускает независимые инструкции вне очереди.
GPU использует другой подход, основанный на многопоточности. У GPU есть pool потоков. Каждый такт выбирается один поток и из него выбирается одна инструкция, которая отправляется на исполнение. На следующем такте выбирается следующий поток и так далее. После того, как из всех потоков в pool была запущена одна инструкция, возвращаемся к первому потоку и т.д. Такой подход позволяет скрыть латентность зависимых инструкций за счёт исполнения инструкций из других потоков.
У GPU есть pool потоков. Каждый такт выбирается один поток и из него выбирается одна инструкция, которая отправляется на исполнение. На следующем такте выбирается следующий поток и так далее. После того, как из всех потоков в pool была запущена одна инструкция, возвращаемся к первому потоку и т.д. Такой подход позволяет скрыть латентность зависимых инструкций за счёт исполнения инструкций из других потоков.
При программировании GPU можно условно выделить два уровня потоков. Первый уровень потоков отвечает за формирование SIMT. Для GPU NVIDIA – это 32 соседних потока, которые называются warp. Известно, что SM для Turing поддерживает 1024 потока. Это количество распадается на 32 настоящих потока, в рамках которых организуется SIMT исполнение. Настоящие потоки могут в один момент времени исполнять разные инструкции, в отличие от SIMT.
Таким образом, стриминговый мультипроцессор Turing – это векторная машина с размером вектора 32 и 32-мя независимыми потоками. Ядро CPU с AVX – это векторная машина с размером вектора 8 и двумя независимыми потоками.
Дополнительные материалы по теме
- Использование CUDA MPS в линуксе для скоростного перекодирования джипегов (сравнение латентностей CPU и GPU для конкретной задачи)
- Функционал Fastvideo SDK для обработки и сжатия изображений на NVIDIA GPU
- Бенчмарки по обработке и сжатию изображений для разных моделей платформы NVIDIA Jetson
Подбор видеокарты под процессор — TopExp
От совместимости видеокарты и процессора зависит производительность в играх. Поэтому важно знать, как собрать сбалансированную систему, избежав просадок FPS и микрофризов.
Содержание [ показать ]
- Что учесть при подборе видеокарты под процессор
- Мощный процессор и слабая видеокарта
- Мощная видеокарта и слабый процессор
- Нет видеокарты, есть графическое ядро
- Как подобрать видеокарту под процессор
- Bottleneck Calculator
- PassMark
- Таблица обратной совместимости
- Коротко о важном
- Подведем итоги
Что учесть при подборе видеокарты под процессор
Начнем с предназначения комплектующих на примере игр:
- Процессор отвечает за обработку мира игры. Сюда входит геометрия неподвижных/динамических объектов, их повреждения/деформация, физика персонажей, работа искусственного интеллекта, воспроизведение аудио.
- Видеокарта занимается обработкой и выводом на экран изображения: наложением текстур, просчетом/отрисовкой теней, освещением. Дополнительную нагрузку обеспечивает разрешение экрана, включение сглаживания и прочих эффектов.
 Сюда входит геометрия неподвижных/динамических объектов, их повреждения/деформация, физика персонажей, работа искусственного интеллекта, воспроизведение аудио.
Сюда входит геометрия неподвижных/динамических объектов, их повреждения/деформация, физика персонажей, работа искусственного интеллекта, воспроизведение аудио.Обязанности CPU и GPU могут отличаться в зависимости от конкретного проекта. Кроме того, на процессор ложится поддержание работы ОС и фоновых программ.
Теперь рассмотрим, что будет, если один из компонентов окажется мощнее.
Мощный процессор и слабая видеокарта
Информацию, собранную об игровом мире, процессор умещает в 1 кадр и передает его для отрисовки видеокарте. Чем мощнее ЦП, тем быстрее и больше кадров он способен обработать и подготовить.
На полученный от процессора кадр видеокарта накладывает картинку с вышеупомянутыми текстурами, освещением, эффектами. Если GPU не успевает за CPU, происходит просадка кадров (FPS). В таком случае придется снижать настройки графики и уменьшать разрешение.
В таком случае придется снижать настройки графики и уменьшать разрешение.
Мощностей процессора должно хватать для одновременного запуска игры и работы операционной системы.
Мощная видеокарта и слабый процессор
В противоположной ситуации мощная видеокарта будет выводить на экран столько кадров, сколько ей успеет подготовить слабый процессор. При этом из-за чрезмерной нагрузки на ЦП могут появиться микрофризы. Незначительно увеличить производительность поможет прекращение работы фоновых программ.
Со слабым ЦП мощная видеокарта работает на 30-70% от своей максимальной мощности.
Нет видеокарты, есть графическое ядро
Графические ядра интегрируют прямиком в процессор. Проблем с совместимостью в этом случае не будет, поскольку за подбор видеоядра отвечают разработчики чипа (Intel, AMD). Преимущество такого решения в прямой передаче кадров с процессора на графическое ядро без посредника в виде материнской платы.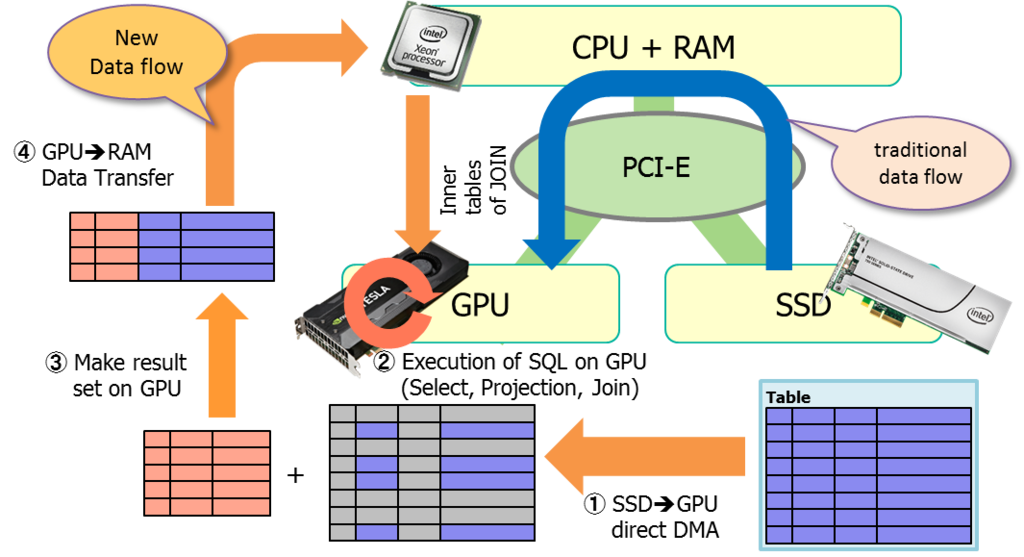 Из-за особенностей производства интегрированные решения значительно уступают десктопным аналогам.
Из-за особенностей производства интегрированные решения значительно уступают десктопным аналогам.
Все однокристальные системы, установленные в смартфоны и планшеты, используют интегрированную графику.
Как подобрать видеокарту под процессор
Универсального способа подобрать комплектующие не существует. До бума майнинга криптовалюты и дефицита полупроводников существовало мнение, что видеокарта должна быть в 1,5-2 раза дороже процессора. В 2023 году такой подход не работает, поэтому в сети есть несколько сервисов для подбора оптимальных комплектующих.
Bottleneck Calculator
Простой в освоении калькулятор для подбора видеокарты к процессору или наоборот. Оказавшись на официальном сайте, укажите:
- производителя, серию и модель процессора;
- производителя, серию и модель видеокарты;
- количество ядер GPU;
- объем оперативной памяти.
В Advance settings вы можете изменить номинальную частоту CPU или GPU. После нажмите Calculate.
После нажмите Calculate.
После анализа появятся результаты обратной совместимости, которые зависят от использования выбранных комплектующих с разным разрешением экрана:
- 1080p;
- 1440p;
- 2160p/4K.
Насколько процессор и видеокарта не подходят друг другу, можно понять по результату в строке Avarage bottleneck percentage – чем меньше указанный процент, тем лучше. Также об отлично подобранном сочетании уведомит надпись: Graphic card and processor will work great together on this resolution.
На этом интересные фишки не заканчиваются. Под полученным результатом снизу есть две вкладки:
- Upgrade Solutions – показывают комплектующие, которые обеспечат прирост производительности.
- Downgrade Solutions – список из комплектующих на замену без особой потери в производительности.
Справа от результатов находится блок Similar CPUs – набор из аналогичных процессоров и информации, насколько они быстрее или медленнее текущего варианта.
Геймерам рекомендуется пролистать страницу ниже, где приведены примерные показатели FPS при текущей сборке и ультравысоких настройках графики. В подборку включены самые популярные тайтлы, в основном для сетевой игры.
Конечный результат производительности зависит от объема/типа оперативной памяти, материнской платы, накопителя SSD/HDD.
PassMark
Это бенчмарк, который собирает результаты тестов:
- процессоров;
- видеокарт;
- твердотельных накопителей и жестких дисков;
- оперативной памяти.
На основе полученных от пользователей результатов сервис оценивает совместимость между комплектующими и даже позволяет собрать виртуальный макет предполагаемого ПК. Чтобы сделать это, перейдите по ссылке. Затем:
- Pick a CPU – выберите процессор из предложенных в разделе Common или укажите другую модель, переключившись в Custom.
- Повторите вышеописанные действия для Pick a video card. Добавлять Drive и Memory необязательно, но с ними вы получите более подробные данные.
- На графике, отображенном внизу страницы, посмотрите, насколько подходящим окажется подобранное сочетание.
 Добавлять Drive и Memory необязательно, но с ними вы получите более подробные данные.
Добавлять Drive и Memory необязательно, но с ними вы получите более подробные данные.Результаты расшифровываются так:
- если подборка в зеленой зоне, комплектующие совместимы, стремитесь к значению в 5000-7000 единиц рейтинга, которые указаны снизу графика;
- коричневая зона сообщает о проблемах со сборкой – подобранные CPU и GPU находятся в дисбалансе, лучше попробовать альтернативный вариант;
- красная зона говорит о вышеупомянутой слишком мощной видеокарте и слабом процессоре или наоборот.
Альтернативный способ, как с помощью PassMark подобрать видеокарту к процессору:
- В панели сверху откройте раздел Video Card Benchmarks. Введите модель карточки в отведенную строку и нажмите на Find Videocard.
- Обратите внимание на результат бенчмарка, отображенный рядом.
- Вернитесь к верхней панели, откройте CPU Benchmarks и задайте модель процессора.
- Проверьте результаты его тестирования: они должны быть аналогичными или на 3000-5000 единиц меньше, чем у видеокарты.
Второй способ подбора абстрактный. Тесты для процессоров и графических ядер отличаются, поэтому сравнение полученных результатов не раскрывает даже примерную совместимость.
Реальная ситуация всегда отличается от той, что показывают синтетические тесты.
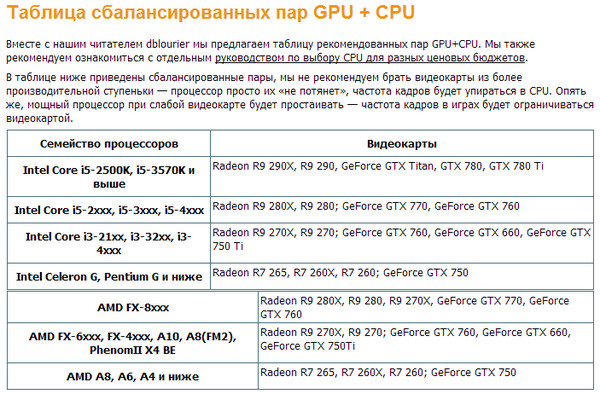
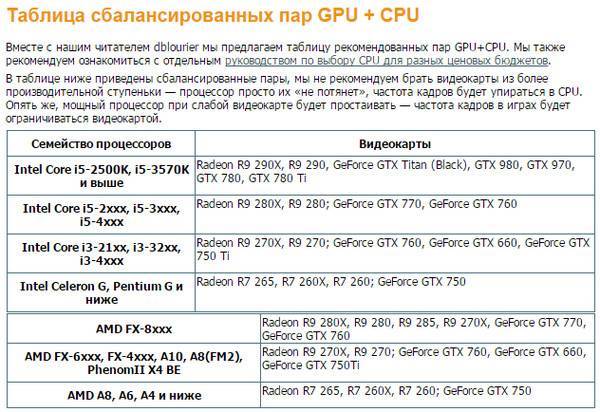
Таблица обратной совместимости
Приведем мини-таблицу совместимых между собой видеокарт и процессоров, актуальную на октябрь 2023 года. В качестве примера будут использованы топовые для своей линейки чипы и подходящие к ним видеокарты.
| Процессоры | Видеокарты |
|---|---|
| Intel Core i3-10100F, AMD Ryzen 3 3100 | GeForce GTX 1050 Ti, AMD Radeon RX 550 |
| Intel Core i5-11400F, AMD Ryzen 5 3600 и их аналоги | GeForce GTX 1650 или карты 2000 серии, AMD Radeon RX 570 |
| Intel Core i7-11700KF, AMD Ryzen 7 5800X | GeForce RTX 3060, Radeon RX 6600 XT |
Подобрать GPU для более старых чипов или наоборот помогут сервисы, упомянутые выше.
Не покупайте топовые б/у видеокарты по низким ценам – их могут распродавать после использования в майнинг-фермах.
Коротко о важном
Кроме совместимости видеокарты и процессора, на производительность влияют и другие факторы:
- Объем оперативной памяти. Большие игры с открытым миром требуют больше ОЗУ, чтобы быстро получать доступ к необходимым файлам. Например, Red Dead Redemption 2 и Cyberpunk 2077 требуют минимум 8 ГБ ОЗУ, но чтобы выжать максимум, используют 16 ГБ.
- Система охлаждения. Во время игры комплектующие начинают нагреваться. Если базовое охлаждение не справляется со своей работой, ядра начинают сбрасывать частоты (троттлить). Избегают подобного заменой системы охлаждения и выбором хорошо продуваемого корпуса. Поможет и подставка с охлаждением.
- Оптимизация в играх. В этом случае все зависит от разработчиков и выбранного ими движка. Некоторые игры не используют многопоточность, другие забывают выгружать из оперативной памяти уже ненужные данные, третьи рассчитаны на работу с процессорами Intel, отчего страдают владельцы AMD. Яркими примером плохой оптимизации выступают Rust, ARK или Deadly Premonition 2, выпущенный на Nintendo Switch.
- Драйверы. Это софт, который оптимизирует работу видеокарт. Наиболее актуален для свежих моделей, способных на старте продаж работать хуже предшествующей линейки.
- Неудачная сборка. В магазинах электроники продают уже собранные системные блоки, часть которых не сбалансирована. Поэтому, отдав круглую сумму, покупатель получает не игровой ПК, а среднюю машину со слишком мощным процессором и слабой видеокартой.
 Яркими примером плохой оптимизации выступают Rust, ARK или Deadly Premonition 2, выпущенный на Nintendo Switch.
Яркими примером плохой оптимизации выступают Rust, ARK или Deadly Premonition 2, выпущенный на Nintendo Switch.Покупать комплектующие отдельно дешевле, а заказать сборку компьютера можно в ближайшем сервисном центре.
Подведем итоги
При подборе видеокарты к процессору стоит учитывать производительность компонентов и внешние факторы, способные повилять на производительность. Помогут с выбором специальные сервисы, например, калькулятор Bottleneck Calculator или бенчмарк PassMark.
Почему использование графического процессора выше, чем использование ЦП?
Когда вы играете в игры AAA или используете ресурсоемкие приложения, использование вашего графического процессора и процессора резко возрастает в зависимости от требуемых ресурсов. Однако некоторые люди испытывают значительную разницу между использованием графического процессора и процессора, что может вызывать тревогу, верно?
Однако некоторые люди испытывают значительную разницу между использованием графического процессора и процессора, что может вызывать тревогу, верно?
Содержание
- Что означает, когда загрузка графического процессора значительно превышает загрузку ЦП
- Несоответствие производительности вызывает узкое место в графическом процессоре
- Программа использует GPU больше, чем настройки CPU
- High Graphics на Games
- Аппаратное ускорение на приложениях
- Фоновые приложения используют ресурсы GPU
- Установленный драйвер графического процессора. Коэффициент использования
- Заключение
Использование графического процессора будет выше, чем использование ЦП, если программа, которую вы запускаете, требует интенсивной обработки графики, например игра. Это также может быть вызвано несоответствием производительности процессора и графического процессора, драйверами, установленными на вашем компьютере, или настройками программ, которые вы используете.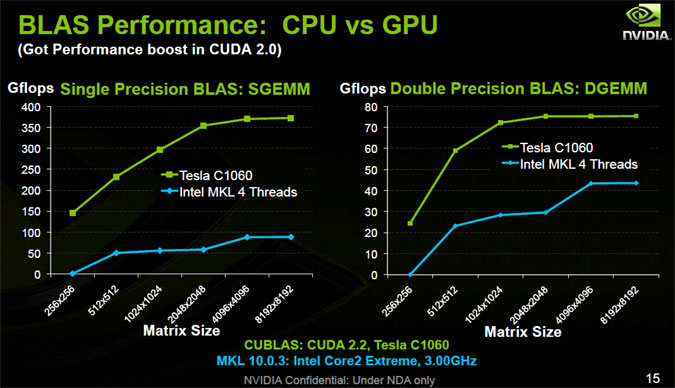
В этой статье мы поговорим о том, что означает всплеск загрузки графического процессора, а также о том, что вы можете сделать, чтобы справиться с этим.
Продолжайте читать, чтобы понять, как работает GPU и почему при использовании некоторых программ нагрузка на него больше, чем на CPU.
Использование графического процессора выше, чем использование ЦП, если вы играете в игру AAA (высокого профиля), это нормально.
На самом деле, вы хотите, чтобы оно было выше, потому что это означает, что GPU работает правильно и может обрабатывать инструкции рендеринга от CPU.
ЦП выполняет множество задач, от простых вычислений до выполнения нескольких сложных программ.
Однако он не может отображать графику, поэтому ему необходимо отправить все инструкции графическому процессору. С другой стороны, GPU может обрабатывать только инструкции, поступающие от CPU.
Эта задача настолько эффективна, что во многих случаях коэффициент использования графического процессора будет выше, чем коэффициент использования ЦП.
Если разница значительна, например, коэффициент использования графического процессора составляет 90 % или более, а загрузка ЦП остается ниже 10 %, то это означает, что вы имеете дело с одной из следующих проблем:
- Несоответствие производительности оборудования.
- Программы с интенсивным использованием графики.
- Слишком много программ работает в фоновом режиме.
- Программы или настройки приложений.
- Устаревшее программное обеспечение или несоответствие.
- Вредоносное ПО на основе графического процессора.
Эти сценарии могут значительно увеличить коэффициент использования вашего графического процессора и вызвать всплеск, даже если вы не используете программу с интенсивным использованием графики.
Хотя вам не следует беспокоиться о большинстве из них, вам все равно нужно быть уверенным, потому что вы хотите, чтобы графический процессор работал только тогда, когда он вам нужен для рендеринга графики.
Давайте поговорим о наиболее распространенных причинах того, что коэффициент использования графического процессора значительно выше, чем использование ЦП.
Несоответствие производительности вызывает узкое место графического процессора
Несоответствие производительности или «узкое место» — наиболее распространенная причина, по которой коэффициент использования графического процессора значительно превышает коэффициент использования ЦП.
Это означает, что вычислительная мощность вашего графического процессора не соответствует производительности центрального процессора, или ваш процессор отправляет слишком много инструкций по рендерингу так быстро, что вашему графическому процессору необходимо использовать все свои ресурсы, чтобы не отставать.
Центральный процессор может многое сделать на вашем компьютере. Тем не менее, он не может отображать графику, если вы не используете APU (ускоренный процессор) или процессор со встроенным графическим процессором.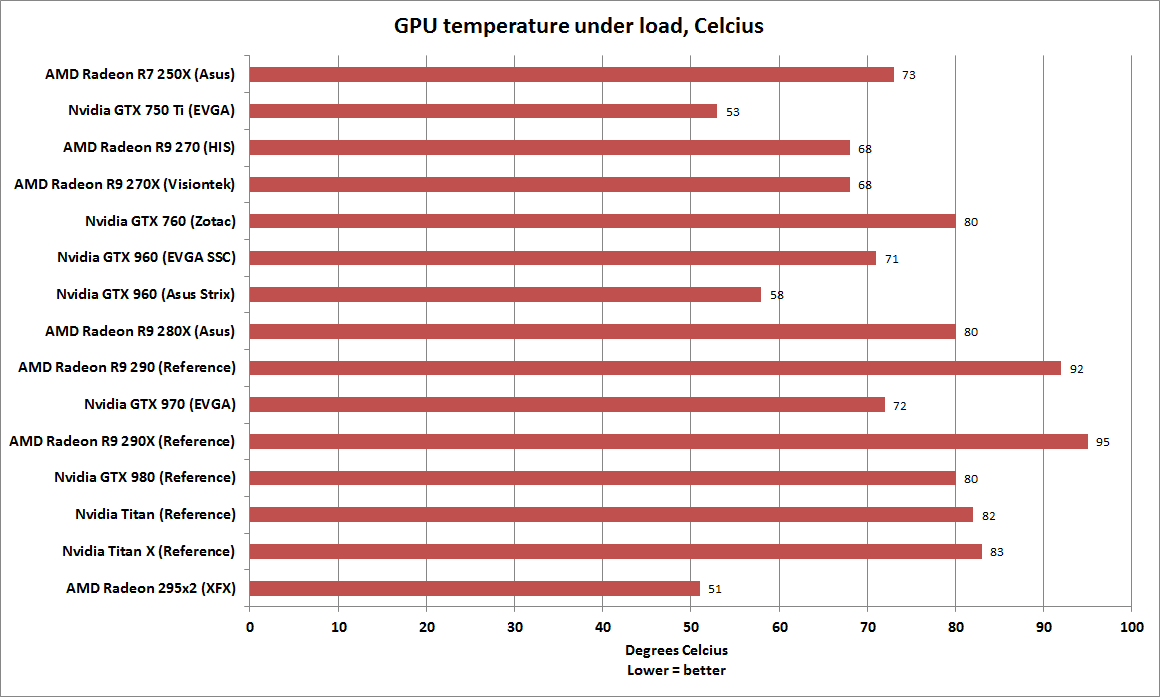
Независимо от вычислительной мощности вашего процессора, компьютер не будет работать без графического процессора, потому что нечего будет отображать графику и отображать ее на мониторе.
Коэффициент использования графического процессора зависит от количества инструкций рендеринга, поступающих от ЦП.
Если у вас есть аппаратное несоответствие, графический процессор не сможет справиться с вычислительной мощностью вашего процессора, что заставит его работать усерднее, что приведет к значительной разнице в коэффициенте использования.
Если вы используете устаревшую видеокарту, выпущенную несколько лет назад, с последним процессором, у вас возникнет проблема с узким местом.
Он может быть в разных формах, но когда у вас есть узкое место в вашем компьютере, его производительность будет ограничена тем, на что способен самый медленный компонент, и в данном случае это видеокарта.
Узкое место в графическом процессоре обычно возникает при обновлении ЦП или использовании более старого графического процессора для новой сборки.
Помните, лучшая сборка компьютера — это та, которая имеет правильный баланс между производительностью всех компонентов.
Вы всегда должны учитывать все детали, которые у вас есть, независимо от того, собираете ли вы новый компьютер или модернизируете его часть.
Программа использует GPU больше, чем CPU
Если у вас хорошо сбалансированная сборка, значительно более высокая загрузка GPU также может означать, что вы используете программу, которая требует большей обработки графики.
Вы столкнетесь с этим несоответствием, если используете программу, имеющую один из следующих параметров:
- Одновременно отображается слишком много объектов.
- Слишком много всего происходит одновременно.
- Игры, которые позволяют вам видеть более дальние расстояния.
- Вы используете программу, для которой требуется HD-графика.
- Редактирование или визуализация файлов с высоким разрешением.
Для выполнения этих задач требуется небольшая вычислительная мощность, но они создают большие нагрузки для обработки графическим процессором.
Таким образом, вы почувствуете значительную разницу между коэффициентом использования ЦП и ГП.
Вам не следует беспокоиться о коэффициенте использования вашего графического процессора, если программа заставляет его работать больше, чем процессор.
Однако, если это вызывает проблемы с вашими играми или программами, которые вы используете, или вам нужно часто их использовать, возможно, пришло время подумать об обновлении графического процессора.
Хороший графический процессор прослужит несколько лет, даже если вы получите постоянный коэффициент использования 90%.
В большинстве случаев вам потребуется заменить видеокарту только потому, что она устарела и уже испытывает проблемы с отображением графики для ваших игр или программ.
Высокие настройки графики в играх
Если вы играете в игры и видите значительную разницу между коэффициентом использования графического процессора и процессора, вы можете заглянуть в настройки графики.
Когда вы включаете автоматический режим в большинстве игр, программа определяет для вас наилучшие настройки графики, что может привести к тому, что ваш графический процессор будет работать намного интенсивнее, чем ваш процессор.
Это не должно быть проблемой, потому что ваш графический процессор должен обеспечивать наилучшую графику, особенно в играх.
Тем не менее, вы можете заглянуть в него, если вам интересно, почему использование вашего графического процессора намного выше, чем использование вашего процессора.
Проблема возникает только тогда, когда ваши игры начинают лагать.
Когда это произойдет, подумайте об обновлении вашего графического процессора, чтобы сделать ваш компьютер более сбалансированным.
Если обновление невозможно, но вы все равно хотите, чтобы ваши игры были более плавными, вы можете вручную настроить параметры графики, чтобы снизить нагрузку на видеокарту.
Аппаратное ускорение в приложениях
Некоторые приложения для редактирования видео предлагают аппаратное ускорение, обеспечивающее более плавную работу в обмен на более высокую нагрузку на графический процессор.
Вы можете отключить эту опцию на странице настроек внутри программы, чтобы уменьшить нагрузку на GPU. Однако ваш опыт работы с программой будет сильно отличаться, если вы отключите эту опцию.
Однако ваш опыт работы с программой будет сильно отличаться, если вы отключите эту опцию.
Веб-браузеры не требуют большой вычислительной мощности. Однако некоторые из них также имеют функции аппаратного ускорения, которые могут обеспечить более плавную работу в Интернете.
Вам не нужно беспокоиться об этом, если вы только просматриваете веб-страницы. Однако, если вы используете другую программу, интенсивно использующую графику, рассмотрите возможность ее отключения, чтобы перераспределить ресурсы графического процессора.
Аппаратное ускорение редко вызывает проблемы с вашим компьютером, поскольку оно автоматически настраивается в зависимости от доступных ресурсов.
Это всего лишь одна из вещей, на которые вы можете обратить внимание, если использование вашего графического процессора значительно выше, чем использование вашего процессора.
Фоновые приложения используют ресурсы графического процессора
В большинстве случаев приложения, работающие в фоновом режиме, не требуют много ресурсов графического процессора. Однако некоторые приложения могут потреблять ресурсы графического процессора, даже если они работают только в фоновом режиме.
Однако некоторые приложения могут потреблять ресурсы графического процессора, даже если они работают только в фоновом режиме.
Есть даже некоторые собственные приложения Microsoft, которые используют графический процессор, даже если вы их не используете!
Если у вас возникают проблемы с графическим процессором во время игр, возможно, одно из этих приложений вызывает всплеск коэффициента использования.
Закрытие этих фоновых приложений высвободит часть ресурсов графического процессора, что даст активным приложениям больше вычислительной мощности.
Вот как вы можете закрыть фоновые приложения, вызывающие всплеск использования графического процессора:
- Перейдите в окно поиска Windows и введите «Диспетчер задач». Другой способ открыть его — щелкнуть правой кнопкой мыши на панели задач и выбрать «Диспетчер задач».
- Перейдите на вкладку GPU, чтобы отсортировать программы, использующие GPU, в порядке возрастания.
- Щелкните правой кнопкой мыши все программы, которые вы не используете, затем щелкните Завершить задачу. Вы также можете нажать на программу, а затем нажать кнопку «Завершить задачу» в правом нижнем углу окна.
 Вы также можете нажать на программу, а затем нажать кнопку «Завершить задачу» в правом нижнем углу окна.
Вы также можете нажать на программу, а затем нажать кнопку «Завершить задачу» в правом нижнем углу окна.Закрытие этих фоновых программ должно освободить ваш графический процессор от ненужной рабочей нагрузки, что может восстановить баланс между использованием вашего графического процессора и процессора.
Установленный драйвер графического процессора не соответствует или устарел
Если вы недавно обновили свой графический процессор, несоответствие драйвера может быть причиной значительной разницы в коэффициенте использования.
Драйвер графического процессора обеспечивает бесперебойную работу ЦП, и если вы используете неправильный драйвер, он всегда будет иметь высокий коэффициент использования, даже если вы не используете программы, интенсивно использующие графику.
Если вы годами используете один и тот же графический процессор и только недавно заметили разницу, возможно, драйвер, который вы используете для графического процессора, устарел.
Если ваш компьютер начинает тормозить, особенно когда вы играете в игры или редактируете фотографии и видео, обновление драйвера должно помочь вам получить больше от вашей видеокарты.
Вы можете найти последнюю версию драйвера для своего графического процессора, зайдя на веб-сайт производителя и найдя раздел загрузок для используемой видеокарты.
У вас должна быть последняя версия драйвера, если вы хотите, чтобы ваш графический процессор работал хорошо и не отставал от вычислительной мощности вашего процессора.
Если у вас по-прежнему возникают те же проблемы с видеокартой даже после обновления драйвера, вы также можете попробовать очистить BIOS.
Вы можете сделать это, удалив аккумулятор из материнской платы, что удалит все настройки, которые у вас есть для компонентов вашего компьютера, включая новый графический процессор.
Когда вы обновляете свой графический процессор, ваш BIOS может по-прежнему загружать старые настройки для вашей графики, что приводит к тому, что он имеет значительно более высокий коэффициент использования, чем ваш процессор.
Сброс позволит BIOS создать новые инструкции для вашего компьютера, включая вашу видеокарту.
Вредоносное ПО для графического процессора, вызывающее высокую степень использования
Последняя причина, по которой ваш графический процессор имеет очень высокий коэффициент использования, — это вредоносное ПО внутри видеокарты.
Это также вызывает наибольшую тревогу, поскольку большинство антивирусных программ не могут обнаруживать вредоносное ПО на основе графического процессора, что затрудняет борьбу с ним.
Любой может удаленно управлять зараженным графическим процессором для выполнения различных задач, включая майнинг криптовалюты.
Это действие заставляет ваш графический процессор использовать свои ресурсы для продолжения майнинга всякий раз, когда вы включаете компьютер. Это не требует многого от вашего процессора, что может привести к резкому увеличению использования графического процессора.
Существует множество других угроз безопасности, связанных с вредоносными программами на основе графического процессора, поскольку они могут содержать один из следующих элементов:
- Кейлоггер, который может записывать нажатия клавиш на вашем компьютере.
- Руткит пользовательского режима, который можно использовать для атаки на ваш компьютер и вашу сеть.
- Инструмент удаленного доступа, который позволяет удаленно контролировать и просматривать ваш компьютер.
К счастью, для работы GPU по-прежнему необходимо обмениваться данными с CPU.
Таким образом, если ваш графический процессор заражен вредоносным ПО, он все равно оставит следы в процессоре. Однако вам понадобится высококлассная антивирусная программа, чтобы обнаружить и удалить его из вашей системы.
Существует два способа заражения графического процессора:
- Физический доступ к графическому процессору для заражения его вредоносным ПО.
- Открытие программы, которая выпускает вредоносное ПО в память графического процессора.
За исключением покупки подержанных графических процессоров или у неавторизованных реселлеров, единственный способ заражения видеокарты — загрузка и открытие вредоносных файлов.
Вот почему вам нужно быть особенно осторожным при загрузке файлов в Интернете.
Заключение
Существует несколько причин резкого увеличения коэффициента использования графического процессора. Однако большинство из них находятся в пределах своей нормальной работы.
На самом деле, если вы используете графический процессор, вы хотите, чтобы он имел высокий коэффициент использования, поскольку это означает, что ваша видеокарта работает должным образом.
Вам следует беспокоиться о необычно высоком коэффициенте использования только в том случае, если используемый для него драйвер несовместим или устарел.
Помимо этого, заражение вредоносным ПО также может вызвать всплеск использования графического процессора, создавая множество угроз безопасности для вашего компьютера.
Что тормозит мой компьютер и как это исправить?
Узкое место. Термин, кажется, используют все в мире настраиваемых компьютеров, но он не совсем понятен для широкой публики. Что означает узкое место? Как это влияет на меня? Как я могу исправить узкое место, если это проблема?
Что означает узкое место? Как это влияет на меня? Как я могу исправить узкое место, если это проблема?
Все это хорошие вопросы, и мы здесь, чтобы дать вам хорошее представление о узких местах и выяснить, как решить проблему с узкими местами вашего ПК.
Что такое узкое место?
Применительно к ПК узкое место относится к компоненту, который ограничивает вычислительную мощность или графическую производительность. Узкие места обычно возникают из-за различий в максимальных возможностях двух компонентов, когда максимальная мощность одной части превышает другую, вызывая эффект узкого места, при котором производительность снижается.
Вы можете визуализировать это так, будто из бутылки вырывается много воды. Если вода не может выйти из бутылки из-за слишком тонкого горлышка, она не будет служить своей цели. Однако, если узкое место довольно толстое по ширине, вода может быстро уйти, а это именно то, что вам нужно. Эта метафора сравнима с частями компьютера, где, если одна часть не может быстро «перетекать» в другую, вы получаете эффект узкого места.
Узкое место ПК не обязательно связано с маркой, возрастом или качеством деталей, а связано с их производительностью по отношению к другим частям. Это может произойти не только в сделанных на заказ высокопроизводительных системах. Это может произойти в устройствах с меньшим бюджетом, если не будет проведено тщательное планирование.
4 Примеры узких мест на ПК
Одно из наиболее распространенных узких мест, с которыми вы столкнетесь, возникает в компьютерных играх и касается вашего ЦП (центрального процессора).
1. Узкие места ЦП/ГП
ЦП отвечает за всю нагрузку важных вычислительных операций и отправляет графическому процессору (ГП) инструкции по рендерингу. Часто процессор слишком слаб, чтобы не отставать от мощной видеокарты на плохо спланированных устройствах, что сильно ограничивает количество кадров в секунду.
Вы могли бы использовать 100% вашего графического процессора, если бы ваш процессор был более мощным, но он тратит время на холостой ход из-за этой конкретной ситуации с узким местом.
2. Узкое место GPU/CPU
Если у вас мощный процессор, но меньший GPU, ваш процессор обрабатывает игру быстрее, чем ваш GPU может ее отрисовать. Однако, хотя это звучит плохо, на самом деле это означает, что ваш компьютер будет отображать 100% кадров, которые он может сделать, а это именно то, что вам нужно в играх. Вот почему всегда полезно обратиться к руководству по сборке игрового ПК, прежде чем начинать сборку ПК!
3. Узкие места жесткого диска
Один из примеров узких мест касается хранилища. Если вы используете более старое устройство, но обновили ЦП, ГП и ОЗУ, следующее обновление — это старый жесткий диск (HDD). Старые жесткие диски имеют более длительное время загрузки или зависания, поскольку ваша программа пытается извлечь информацию с жесткого диска, который вы можете заменить более быстрым твердотельным накопителем.
4. Узкие места дисплея
Не только внутренние компоненты вызывают узкие места. Допустим, у вас есть первоклассная Nvidia RTX 3080, но вы все еще играете на мониторе с частотой 60 Гц и разрешением 1080p. Хотя ваш видеовыход будет исключительным, и вы будете играть в игры на ультра настройках, вы не получите максимум от своего оборудования, что является еще одним узким местом.
Хотя ваш видеовыход будет исключительным, и вы будете играть в игры на ультра настройках, вы не получите максимум от своего оборудования, что является еще одним узким местом.
Как определить узкое место ПК с помощью калькулятора узких мест
Если вы уверены, что ваш компьютер не работает должным образом, возможно, у вас есть системное узкое место. Но выяснить, как компоненты вашего ПК работают вместе и какие компоненты не работают хорошо, не так просто, как открыть корпус вашего ПК и поковыряться. Есть несколько способов, которыми вы можете проверить наличие узких мест в компонентах вашего ПК, не прибегая к практическим усилиям — по крайней мере, пока не прибегая к помощи!
Существует несколько онлайн-калькуляторов узких мест, которые вы можете использовать, чтобы выяснить, что сдерживает вашу машину. Одним из вариантов для этого примера является вычисление FPS агента ЦП и калькулятор узких мест. Это простой процесс; зайдите на сайт, введите информацию о своем процессоре, графическом процессоре и оперативной памяти, затем нажмите Кнопка «Рассчитать FPS и узкое место» . Не уверены в характеристиках своего ПК? Есть несколько способов быстро проверить характеристики ПК, а затем заполнить форму.
Не уверены в характеристиках своего ПК? Есть несколько способов быстро проверить характеристики ПК, а затем заполнить форму.
Вторым вариантом является Калькулятор узких мест сборки ПК, который следует аналогичному процессу с некоторыми небольшими отличиями. В частности, PC Builds не запрашивает информацию о вашей оперативной памяти, но запрашивает информацию о вашем предполагаемом использовании системы, которую он использует, чтобы выяснить, в чем заключаются ваши проблемы. Например, как вы можете видеть на изображениях ниже, мой графический процессор GTX 1070 является узким местом моего гораздо более мощного процессора AMD Ryzen 7 5800X, показывая, что требуется новый графический процессор.
3 Изображения
Как устранить узкое место на ПК?
Самое простое решение проблем с узкими местами, какие бы вы ни искали в настраиваемом ПК, — это убедиться, что вы выбрали сбалансированную сборку компонентов. Какое бы оборудование вы ни выбрали, планирование предотвратит узкие места оборудования и обеспечит оптимальную производительность по всем направлениям. Вместо того, чтобы покупать сильно перегруженные отдельные детали, вам будет гораздо лучше купить сбалансированные части комплекта, которые подходят друг к другу. В противном случае ваша система будет тормозить.
Вместо того, чтобы покупать сильно перегруженные отдельные детали, вам будет гораздо лучше купить сбалансированные части комплекта, которые подходят друг к другу. В противном случае ваша система будет тормозить.
Такие веб-сайты, как PCPartPicker, отлично подходят для планирования новой сборки ПК, поскольку они позволяют гипотетически вставлять части и части и смотреть, что работает вместе, а что нет. Используя такие сайты, вы можете создать систему, которая всегда будет работать, независимо от того, какие программы вы запускаете или в какие игры играете. Также важно помнить, что вы всегда можете обновить некоторые детали позже и что вы должны оптимизировать сейчас, прежде чем обновлять что-то позже.
Однако единственная проблема таких сайтов, как PCPartPicker, заключается в том, что хотя они и показывают вам совместимые детали, они не иллюстрируют проблемы, которые могут возникнуть в дальнейшем. Таким образом, лучший способ избежать создания новой системы с узким местом — это ввести свои потенциальные компоненты в одну из вышеупомянутых онлайн-проверок и проверить результат.