Legacy система: Восемь секретов модернизации унаследованных информационных систем
Содержание
Восемь секретов модернизации унаследованных информационных систем
Оригинал: 8 tips for streamlining legacy IT
Автор: Мэри К. Пратт (Mary K. Pratt)
Несмотря на ускорение прогресса в сфере цифровых технологий и продолжающийся курс на модернизацию, многие ИТ-директора все еще имеют дело с унаследованными приложениями, работающими на устаревшем оборудовании.
Типичные причины, по которым компании вынуждены использовать такие технологии: «они стабильны, экономичны и, наконец, за них заплачены деньги», — говорит Абхи Бхатнагар (Abhi Bhatnagar), партнер в консалтинговой компании McKinsey & Co. Однажды он работал с компанией, которая приняла решение сохранить массивный мейнфрейм, поскольку он «хорошо работает, отлично интегрирован в процессы, содержит множество заказных доработок, а его стоимость полностью амортизирована».
Зачастую ИТ-директору очевидно, что замена устаревшей технологии не настолько выгодна, чтобы ставить модернизацию во главу угла. «Сегодня популярна точка зрения, что все ИТ необходимо перенести в облако или использовать SaaS. Однако в действительности далеко не все системы нуждаются в этом, особенно если они работают стабильно и эффективно», — замечает Бхатнагар.
«Сегодня популярна точка зрения, что все ИТ необходимо перенести в облако или использовать SaaS. Однако в действительности далеко не все системы нуждаются в этом, особенно если они работают стабильно и эффективно», — замечает Бхатнагар.
Так или иначе, многие ИТ-директора сохраняют у себя унаследованные приложения и инфраструктуру. В такой ситуации важно уметь использовать то, что есть, заставить унаследованные технологии работать максимально эффективно, получить максимальную отдачу при минимальных затратах и рисках. Вот восемь полезных советов:
1. Задействуйте автоматизацию
Автоматизация рутинных задач в унаследованных ИТ-системах повышает производительность за счет сокращения ручного труда, устраняет или сокращает число ошибок, повышает качество, устраняет расхождения в данных.
«Неважно, идет ли речь о Unix, Linux, мейнфреймах или трехуровневой архитектуре, возможности для автоматизации есть всегда», — уверен Хуан Орландини (Juan Orlandini), главный ИТ-архитектор компании Insight Enterprises, специализирующейся на оказании ИТ услуг.
Он поясняет, что многие бизнес-процессы, которые поддерживаются унаследованными информационными системами, содержат повторяющиеся структурированные задачи. Кроме того, много повторяющихся задач в собственных процессах ИТ, например таких, как управление дисковым пространством или создание резервных копий.
При этом Орландини отмечает, что прежде чем автоматизировать процессы, их необходимо проанализировать и оптимизировать – автоматизация неоптимального процесса не даст ожидаемого эффекта. Также он предостерегает ИТ-руководителей от завышенных ожиданий: автоматизация способна ускорить унаследованные системы и процессы, которые на них базируются, но это не панацея и не замена полноценной модернизации.
2. Воспользуйтесь облачными подходами
Орландини отмечает, что, по его опыту, перенос унаследованных систем и связанных с ними данных в облако «как есть» чаще всего себя не окупает. По его словам, «конечно, ситуации, когда такой подход оправдан, возможны, но, как показывают статистика и опыт, обычно затраты в результате возрастают. Если вы таким образом пытаетесь оптимизировать ИТ-инфраструктуру, то лучше поискать другие варианты.»
Если вы таким образом пытаетесь оптимизировать ИТ-инфраструктуру, то лучше поискать другие варианты.»
Можно применить к унаследованным ИТ-системам принципы управления облачной инфраструктурой. Например, чтобы упростить процесс, в облаке выделяется дисковое пространство предопределенного размера. Этот же подход могут использовать и администраторы локальной серверной инфраструктуры.
«Может показаться, что часть дискового пространства при этом будет тратиться впустую. Это так и есть, но за счет упрощения процесса вы сэкономите массу трудозатрат. А дисковое пространство сегодня стоит меньше, чем рабочее время сотрудника, так что в итоге получится выигрыш», — говорит Орландини.
3. Внедрите продуктовый подход
По мнению Абхи Бхатнагара, ИТ-руководитель может также перенять и применить к унаследованным технологиям современные продуктовые подходы. Он позволит ИТ-службе и бизнесу сконцентрироваться на бизнес-целях, будь то скорость, экономичность, быстрота реакции или инновации. Таким образом, объясняет эксперт, реорганизация и оптимизация унаследованной инфраструктуры будут подчинены выбранным бизнес-целям.
Таким образом, объясняет эксперт, реорганизация и оптимизация унаследованной инфраструктуры будут подчинены выбранным бизнес-целям.
Продуктовый подход дает техническим специалистам, поддерживающим унаследованные системы, более четкое понимание проблем через призму достижения конечной цели. «Они знают ИТ-инфраструктуру и хорошо понимают как риски, связанные с комплаенсом и скоростью, так и пользу, которую получает от их платформ бизнес», — считает Бхатнагар. Это позволяет ИТ-командам находить и отстаивать оптимальные подходы к добавлению новой функциональности, обеспечивающие достижение требуемых результатов. «Здесь как раз оказывается востребовано продуктовое мышление», — добавляет Бхатнагар.
Более того, когда настанет пора практических шагов по модернизации, такой подход поможет ИТ и бизнесу прийти к единому пониманию ожидаемой пользы.
4. Модернизируйте по частям
Компании продолжают использовать унаследованные технологии из-за того, что от них зависит множество ключевых бизнес-процессов. По этой причине модернизация – дело сложное и сопряженное с рисками.
По этой причине модернизация – дело сложное и сопряженное с рисками.
Но повысить эффективность ИТ-систем можно, проводя модернизацию поэтапно, полагает Баладжи Рагхаван (Balaji Raghavan), главный консультант по банковским, финансовым услугам и страхованию в Tata Consultancy Services. «Многого можно добиться, действуя тактически», — считает он.
Например, компания может продолжать использовать унаследованную многофункциональную финансовую систему для задач, мало подверженных изменениям, таких как ведение бухгалтерской отчетности. Но при этом выписку счетов и ценообразование – задачи, которые меняются быстро, следуя динамике рынка и запросам клиентов – можно вынести наружу. Рагхаван отмечает, что благодаря такому подходу компания сможет продвигаться вперед по пути модернизации, одновременно снижая сложность остающихся строю унаследованных ИТ-систем.
Кэти Кэй (Kathy Kay), ИТ-директор Principal Financial Group, использует подобный подхода по отношению к системам, используемым в подразделении по страхованию жизни ее компании. Кэти считает, что замена этих систем на единую современную не окупит затраты, но она видит потенциал улучшения в том, как пользователи взаимодействуют с системами. Поэтому она нацелилась на модернизацию пользовательского интерфейса, интегрируя его c унаследованной системой посредством API.
Кэти считает, что замена этих систем на единую современную не окупит затраты, но она видит потенциал улучшения в том, как пользователи взаимодействуют с системами. Поэтому она нацелилась на модернизацию пользовательского интерфейса, интегрируя его c унаследованной системой посредством API.
«Мы автоматизируем все что можно автоматизировать, мы сократили бумажный документооборот, но в основе – все те же унаследованные системы. Они будут работать пока работают и, как выразился автор одной из книг, уйдут на пенсию в свой черед», — говорит Кэй.
5. Разработайте стратегию привлечения талантов
В апреле 2020 губернатор штата Нью-Джерси Фил Мерфи (Phil Murphy) обратился к техническим специалистам, владеющим навыками разработки на языке программирования COBOL, с просьбой помочь оптимизировать работу вычислительного центра Бюро занятости, чьи компьютеры не справлялись с нагрузкой, сильно возросшей из-за пандемии и связанной с ней волны сокращений рабочих мест.
Вам смешно, но штат Нью-Джерси вовсе не единственный полагается на программные продукты 60-летней давности. COBOL стойко удерживает свои позиции – активно используемое ПО на нем насчитывает более 200 миллиардов строк кода, и отказываться от него никто в ближайшее время не собирается. Разработчик ПО компания MicroFocus в 2020 г. в своем исследовании COBOL сообщает, что «70 процентов организаций предпочитают внедрять стратегические изменения эволюционным путем, а не выбрасывать или заменять ключевые приложения на COBOL. Такой подход оправдывает себя в силу низкого риска и эффективен с точки зрения трансформации ИТ в рамках инициатив цифровой трансформации».
COBOL стойко удерживает свои позиции – активно используемое ПО на нем насчитывает более 200 миллиардов строк кода, и отказываться от него никто в ближайшее время не собирается. Разработчик ПО компания MicroFocus в 2020 г. в своем исследовании COBOL сообщает, что «70 процентов организаций предпочитают внедрять стратегические изменения эволюционным путем, а не выбрасывать или заменять ключевые приложения на COBOL. Такой подход оправдывает себя в силу низкого риска и эффективен с точки зрения трансформации ИТ в рамках инициатив цифровой трансформации».
Пока COBOL и другие унаследованные технологии остаются в строю, ИТ-директорам требуются сотрудники, способные обеспечивать их нормальную работу, говорит Орландини.
«Увеличивается дефицит специалистов, разбирающихся в старых технологиях, по-прежнему актуальных для бизнеса. Молодежь предпочитает делать крутые вещи на современных технологиях, а старыми не владеют. Очень важно мотивировать часть ваших сотрудников сохранять навыки работы с унаследованным ПО и оборудованием. Это не должно выглядеть как наказание или конец карьеры. Вам нужен кто-то, кто будет поддерживать в строю вашу систему, опытный специалист, который знает, как устранить любую неполадку», — добавляет он.
Это не должно выглядеть как наказание или конец карьеры. Вам нужен кто-то, кто будет поддерживать в строю вашу систему, опытный специалист, который знает, как устранить любую неполадку», — добавляет он.
6. Примените к унаследованным технологиям современные подходы
Кэти Кэй рекомендует ИТ-директорам использовать для поиска решений по модернизации унаследованных систем современные методики и подходы. В ее компании специалисты, работающие с унаследованными системами, повысили свою квалификацию и обучились работе с современными ИТ-системами. В результате, будучи специалистами как в старых, так и в новых технологиях, сотрудники находят возможности для модернизации унаследованной ИТ-инфраструктуры, о которых не знали раньше.
«Люди, искушенные в старых технологиях, хорошо представляют себе, как устроен бизнес. Как следствие профессионального роста они начинают иначе смотреть на вещи и быстро находят свежие решения», —отмечает Кэй. Недавно компания Кэй приобрела фирму, клиентскую базу которой потребовалось импортировать в существующую систему. Новые знания и навыки позволили разработать для миграции данных современное решение, оказавшееся более эффективным, продуктивным и масштабируемым, чем использовавшиеся в прошлом.
Новые знания и навыки позволили разработать для миграции данных современное решение, оказавшееся более эффективным, продуктивным и масштабируемым, чем использовавшиеся в прошлом.
7. Вытащите данные наружу
Как и большинство ИТ-директоров, Кэй вместе с остальными руководителями разрабатывают стратегию улучшению клиентского опыта. Ее частью является возможность оперативного доступа к данным для анализа, чтобы компания смогла персонализировать клиентский опыт.
Но часть данных остается в унаследованных системах. Кэй говорит, что что планирует модернизацию этих систем, но это займет много лет. А пока компания извлекает данные из старой системы и копирует в облако, где их удобно обрабатывать с помощью современных аналитических инструментов. «Тем самым мы сокращаем нашу зависимость от унаследованных систем, что позволит легче расстаться с ними, когда придет время», — замечает Кэй.
8. Выключайте
Джоне Тил Джонсон (Johna Till Johnson), исполнительному директору и основателю консалтинговой фирмы Nemertes, приходилось встречать компании, которые держатся за унаследованные приложения и технологии из-за бизнес-процессов, которые они обеспечивают.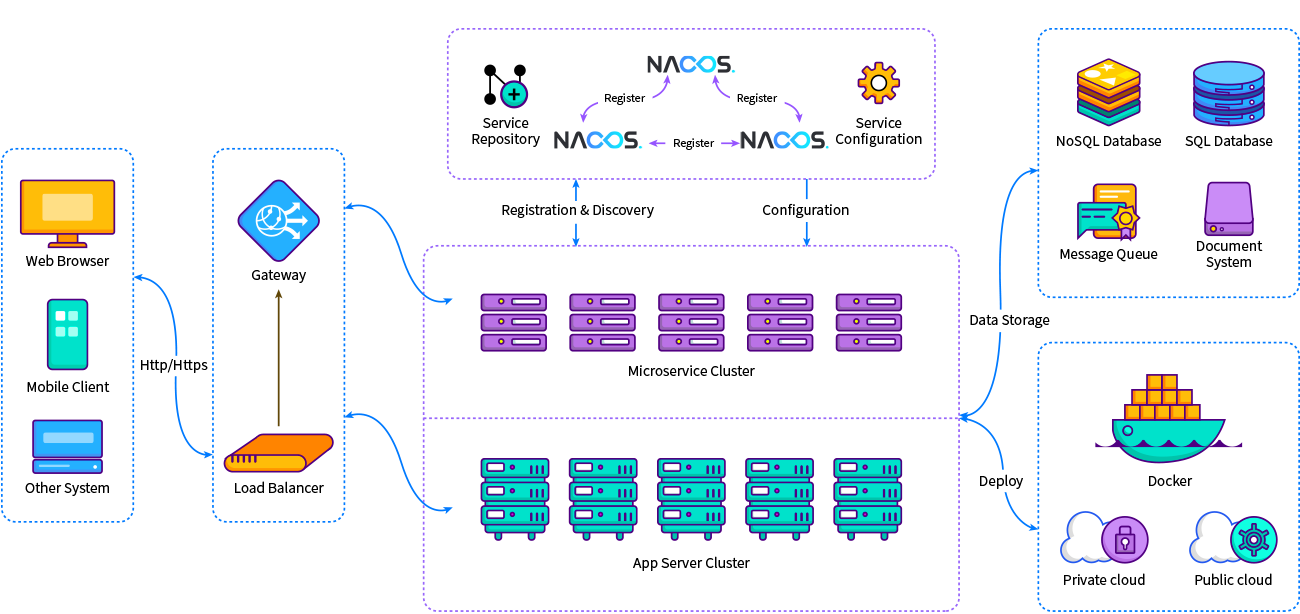 Но изучив ситуацию, компании часто обнаруживают, что тот или иной процесс остается в строю только из-за использования технологии.
Но изучив ситуацию, компании часто обнаруживают, что тот или иной процесс остается в строю только из-за использования технологии.
«Все-таки ИТ-директора ближе к технологии, и они не могут так просто заявить, следует переделать бизнес-процесс. Но когда они на это решались, то в 99 случаях из 100 оказывалось, что бизнес-процесс существовал по инерции, только из-за технологии в его основе», — отмечает Джонсон.
В качестве примера она приводит компанию, которая сохраняла парк принтеров ради живых подписей на документах. Руководители бизнес-направлений могут не понимать, что такую ситуацию надо менять. Но для ИТ-директора, борющегося за упрощение операций, масса устаревших принтеров — как бельмо в глазу, даже если они и не в списке приоритетных изменений. «Сегодня больше нет необходимости распечатывать документ на принтере, чтобы воспользоваться всеми преимуществами живой подписи. ИТ-руководитель вполне может подтолкнуть бизнес и скорее избавиться от принтеров», — говорит Джона.
Также она замечает, что этот простой пример показывает, что «если нельзя избавиться от унаследованной технологии, надо избавиться от процесса.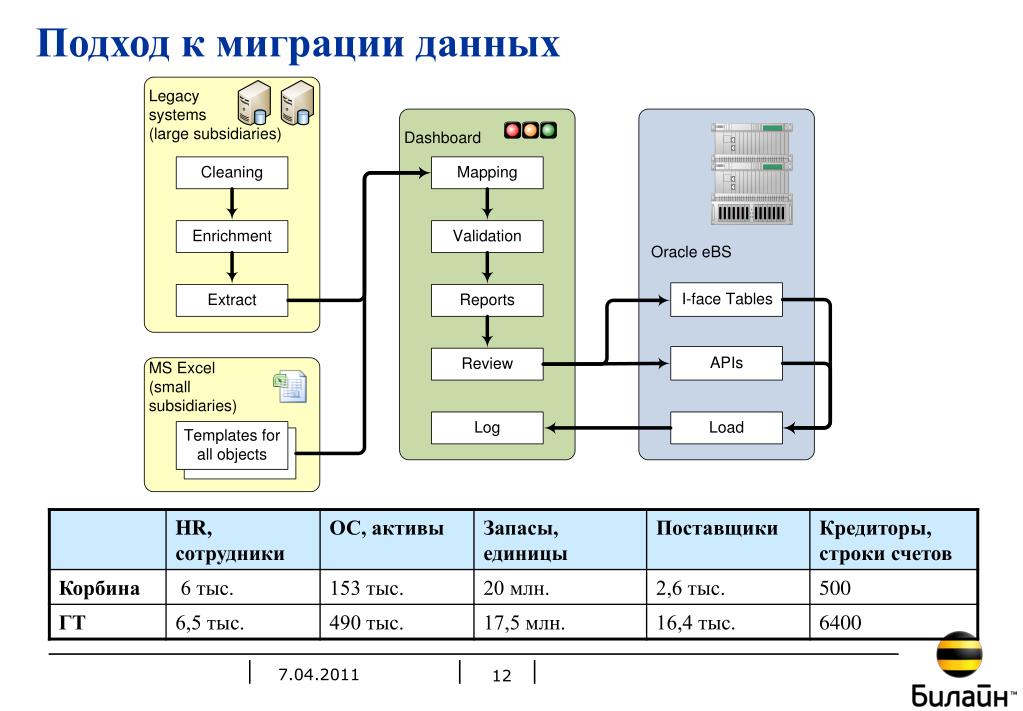 В таких ситуациях надо просто, что называется, выдернуть шнур из розетки. Не тратьте время и силы на поддержку унаследованных технологий, которые поддерживают жизнь в устаревших процессах. Выключите и посмотрите, заметит ли кто-нибудь разницу».
В таких ситуациях надо просто, что называется, выдернуть шнур из розетки. Не тратьте время и силы на поддержку унаследованных технологий, которые поддерживают жизнь в устаревших процессах. Выключите и посмотрите, заметит ли кто-нибудь разницу».
Обсудить
Как работать с legacy-системами | DOU
На самом деле, по-хорошему статью следовало бы назвать так: «Как работать с legacy-системами и сохранять психическое здоровье». Любой, кто имеет с ними дело, меня поймет. Эта статья — попытка обобщения многолетнего опыта знакомства с legacy-системами в виде набора подходов и практических советов. Примеры буду приводить из собственного опыта — в частности, работы с унаследованной Java-системой.
Кстати, материалов о работе с legacy в структурированном виде почти нет — оба источника, посвященных именно ей, приведены в конце материала. И это при том, что на legacy приходится чуть ли не половина всего аутсорсинга.
Особенности legacy
Legacy — в переводе с английского «наследство», и наследственность эта тяжелая. Почти всем доводилось, придя в проект, получить код десятилетней давности, написанный кем-то другим. Это и есть унаследованный код — то есть код исто(е)рический, который часто бывает ужасен настолько, что оказывается вообще непонятно, как с ним работать. И если нам достается legacy-система, то мы, кроме старого кода, также имеем:
Почти всем доводилось, придя в проект, получить код десятилетней давности, написанный кем-то другим. Это и есть унаследованный код — то есть код исто(е)рический, который часто бывает ужасен настолько, что оказывается вообще непонятно, как с ним работать. И если нам достается legacy-система, то мы, кроме старого кода, также имеем:
— устаревшие технологии;
— неоднородную архитектуру;
— недостаток или даже полное отсутствие документации.
Со всем этим нам нужно разбираться и как-то жить дальше. И тут без хорошего чувства юмора, пожалуй, не обойтись — те, кто воспринимают жизнь слишком серьезно, обычно сбегают сразу же, как только увидят настоящее legacy.
На самом деле, legacy-система — это не так уж страшно, и вот почему: если система жила все эти десять лет и до сих пор работает, значит, какой-то толк от нее есть. Может быть, она приносит хорошие деньги (в отличие от вашего последнего стартапа на новейших технологиях). Кроме того, код такой системы относительно надежен, если он смог так долго выживать в продакшне. Поэтому вносить в него изменения нужно с осторожностью.
Поэтому вносить в него изменения нужно с осторожностью.
Прежде всего, нужно понять две вещи:
1. Мы не можем неуважительно относиться к системе, которая зарабатывает миллионы, или к которой обращаются тысячи людей в день. Как бы плохо она ни была написана, этот отвратительный код дожил до продакшна и работает в режиме 24/7.
2. Раз эта система приносит реальные деньги, работа с ней сопряжена с большой ответственностью. С самого начала ясно, что это не стартап в стол, а то, с чем пользователи будут работать уже завтра. Это подразумевает и очень высокую цену ошибки, причем дело здесь не в претензиях клиента, а в реальном положении вещей.
Какие задачи нам придется решать, работая с такой системой? Во-первых, мы, очевидно, будем разрабатывать новую функциональность, раз система жива, а значит развивается. Во-вторых, мы будем исправлять ошибки, и это тоже очевидно. И наконец, хотя многие предпочитают про это забыть, мы будем заниматься оптимизацией и стабилизацией системы, даже если напрямую такой задачи перед нами в начале проекта никто не ставил.
Обратный инжиниринг
Для успешной работы с унаследованными системами нам придется много пользоваться приемами reverse engineering.
Прежде всего, нужно внимательно читать код, чтобы точно понимать, как именно он работает. Это обязательно — ведь достаточной документации у нас, скорее всего, не будет. Если мы не поймем хода мыслей автора, то будем делать изменения, последствия которых окажутся не вполне предсказуемыми. Чтобы обезопасить себя от этого, нужно вникать еще и в смежный код. И при этом двигаться не только вширь, но и вглубь, докапываясь до самого нутра. Откуда вызывается метод с ошибкой? Откуда вызывается вызывающий его код? В legacy-проекте «call hierarchy» и «type hierarchy» используется чаще, чем что бы то ни было другое.
Конечно, придется проводить много времени с отладчиком — во-первых, чтобы находить ошибки, и во-вторых, чтобы понять, как все работает — потому что логика обязательно будет такой, что по-человечески прочитать ее мы не сможем. Собственно говоря, дебажить нужно будет вообще все, в том числе и open source-библиотеки.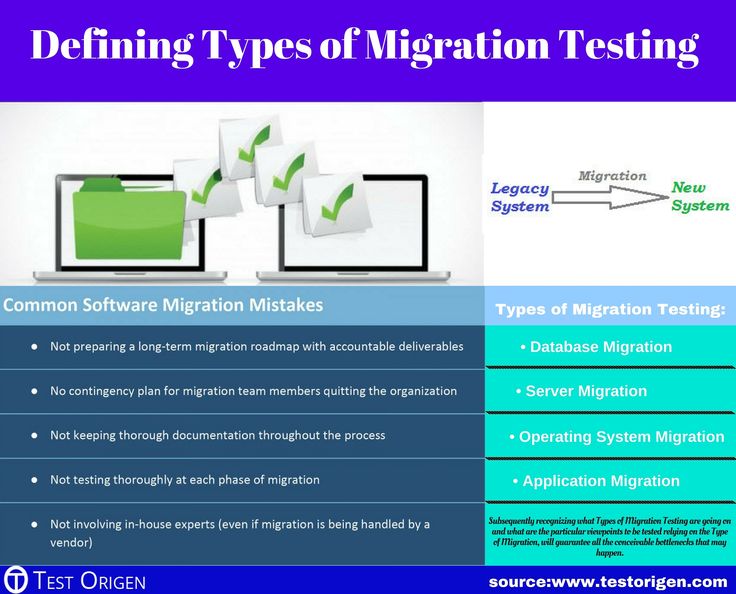 Даже если проблема где-то в Spring, значит, придется отлаживать и, возможно, пересобирать Spring, если возможности его обновить не окажется. Именно так нам неоднократно приходилось делать, причем не только со Spring.
Даже если проблема где-то в Spring, значит, придется отлаживать и, возможно, пересобирать Spring, если возможности его обновить не окажется. Именно так нам неоднократно приходилось делать, причем не только со Spring.
Что касается документации, не лишним будет прибегнуть к тому, что я бы назвал промышленной археологией. Очень полезно бывает откопать где-нибудь старую документацию и поговорить с теми, кто помнит, как писался доставшийся вам код. Возможно, где-то есть старый Confluence, возможно, хотя бы дамп его базы, где вы что-то, может быть, и найдете. Иногда это бывает проще, чем сидеть с дебаггером. Но нередко там окажутся только документы, не имеющие прямого отношения к коду, например, руководства по настройке серверов, которые все в принципе боятся трогать.
Используя эти приемы, рано или поздно вы начнете более или менее понимать код. Но чтобы ваши усилия не пошли прахом, вы должны обязательно сразу же документировать результаты своих изысканий — для этого я советую рисовать блок-схемы или диаграммы последовательности (sequence diagrams). Конечно, вам будет лень, но делать это точно нужно — через полгода без документации вы сами в этом коде будете копаться как в первый раз. А если через полгода с кодом будете работать уже не вы, ваши последователи будут очень благодарны вам за имеющуюся документацию.
Конечно, вам будет лень, но делать это точно нужно — через полгода без документации вы сами в этом коде будете копаться как в первый раз. А если через полгода с кодом будете работать уже не вы, ваши последователи будут очень благодарны вам за имеющуюся документацию.
Кстати, зачастую для себя и для бизнеса документацию нужно готовить разную: в вашей, рассчитанной на инженеров, представители бизнеса ничего не поймут. Им потребуется что-то понятное, описывающее функционирование системы на верхнем уровне. И наконец, нужно не забывать самим пользоваться этой документацией и читать ее. Однажды, решив проблему после двух дней героической борьбы, мы обнаружили собственный документ, подробно описывающий точно такой же случай.
Процесс разработки
Итак, что нужно и что не нужно делать:
— Не переписывать. Самое важное здесь — вовремя бить себя по рукам и не пытаться переписать весь код заново. Прикиньте, сколько человеко-лет для этого потребуется — вряд ли заказчик захочет потратить столько денег на переделывание того, что уже и так работает. Это касается не только системы в целом, но и любой ее части. Вам, конечно, могут дать неделю на то, чтобы во всем разобраться, и еще неделю на то, чтобы что-то исправить. Но вряд ли дадут два месяца на написание части системы заново.
Это касается не только системы в целом, но и любой ее части. Вам, конечно, могут дать неделю на то, чтобы во всем разобраться, и еще неделю на то, чтобы что-то исправить. Но вряд ли дадут два месяца на написание части системы заново.
Вместо этого реализуйте новый функционал в том же стиле, в каком написан остальной код. Другими словами, если код старый, не стоит поддаваться соблазну использовать новые красивые технологии — такой код потом будет очень тяжело читать. Например, вы можете столкнуться с ситуацией, которая была у нас — часть системы написана на Spring MVC, а часть — на голых сервлетах. И если в части, написанной на сервлетах, нужно дописать еще что-то, то дописываем мы это так же — на сервлетах.
— Соблюдать бизнес-интересы. Нужно всегда помнить, что любые задачи обусловлены прежде всего ценностью для бизнеса. Если вы не докажете заказчику необходимость тех или иных изменений с точки зрения бизнеса, этих изменений не будет. А для того, чтобы убедить заказчика, вы должны попробовать встать на его место и понять его интересы. В частности, если вам хочется провести рефакторинг только потому, что код плохо читается, вам не дадут этого сделать, и с этим нужно смириться. Если совсем уж невмоготу, реорганизовывать код можно по-тихому и понемногу, размазывая работу по бизнес-тикетам. Либо убедить заказчика в том, что это, например, сократит время, необходимое для поиска ошибок, а значит, в конечном итоге сократит расходы.
В частности, если вам хочется провести рефакторинг только потому, что код плохо читается, вам не дадут этого сделать, и с этим нужно смириться. Если совсем уж невмоготу, реорганизовывать код можно по-тихому и понемногу, размазывая работу по бизнес-тикетам. Либо убедить заказчика в том, что это, например, сократит время, необходимое для поиска ошибок, а значит, в конечном итоге сократит расходы.
— Тестировать. Понятно, что тестирование необходимо в любом проекте. Но при работе с legacy-системами тестированию нужно уделять особое внимание еще и потому, что влияние вносимых изменений не всегда предсказуемо. Тестировщиков потребуется не меньше, чем разработчиков, в противном случае у вас должно быть все просто невероятно хорошо с автоматизацией.
В нашем проекте тестирование состояло из следующих фаз:
1. Верификация, когда реализованный функционал фичи проверяется в отдельной ветке.
2. Стабилизация, когда проверяется ветка релиза, в которой все фичи слиты вместе.
3. Сертификация, когда все то же самое прогоняется еще раз на немного других тест-кейсах в сертификационном окружении, максимально приближенном к продакшну по характеристикам железа и конфигурации.
И только после прохождения всех этих трех фаз мы можем делать релиз. Кто-то наверняка считает, что сертификация — лишняя фаза, так как на стадии стабилизации все уже выяснено, но наш опыт говорит о том, что это не так — иногда во время регрессионного теста, который прогоняется по второму кругу на другой машине, что-нибудь да вылезет.
— Формализовать DevOps и релиз. При работе с legacy-системой важно наладить все, что касается DevOps и прочих практик, напрямую не связанных с разработкой. В частности, очень хорошо совместно с девопсами на стороне заказчика прописать определенную процедуру релиза, каждый шаг которой будет строго документирован. Только тогда процесс становится предсказуемым и ясным для каждого из участников.
Релизная процедура может быть, например, следующей. Когда заканчивается разработка и пройдены две или три фазы тестирования, мы пишем письмо DevOps-команде за 36 часов до предполагаемого времени релиза. После этого созваниваемся с девопсами и обсуждаем все изменения окружений (мы сообщаем им обо всех изменениях в БД и конфигурации). На каждое изменение у нас есть документ (тикет в Jira). Затем во время релиза все причастные к этому собираются вместе, и каждый говорит, что он сейчас делает: «Мы залили базу», «Мы перезапустили такие-то серверы», «Мы пошли прогонять регрессионные тесты в рабочем окружении». Если же что-то идет не так, запускается процедура отката релиза, точно описанная в изначальном документе на релиз — без такого документа мы обязательно что-нибудь забудем или напутаем (вспомните, в какое время суток обычно происходят релизы).
Когда заканчивается разработка и пройдены две или три фазы тестирования, мы пишем письмо DevOps-команде за 36 часов до предполагаемого времени релиза. После этого созваниваемся с девопсами и обсуждаем все изменения окружений (мы сообщаем им обо всех изменениях в БД и конфигурации). На каждое изменение у нас есть документ (тикет в Jira). Затем во время релиза все причастные к этому собираются вместе, и каждый говорит, что он сейчас делает: «Мы залили базу», «Мы перезапустили такие-то серверы», «Мы пошли прогонять регрессионные тесты в рабочем окружении». Если же что-то идет не так, запускается процедура отката релиза, точно описанная в изначальном документе на релиз — без такого документа мы обязательно что-нибудь забудем или напутаем (вспомните, в какое время суток обычно происходят релизы).
— Выстроить branching strategy. Основные модели бренчинга давно описаны на сайте того же Atlassian, их можно адаптировать под ваши нужды. Главное — ни в коем случае не коммитить изменения сразу в транк: должны быть stable trunk и feature branches. Я советую делать релизы из релизных веток, а не из транка. То есть у вас есть транк, от которого отходят ветки на конкретные фичи, соответствующие тикетам в Jira. Когда вы закончили разработку в спринте, вы собираете отдельную релизную ветку из готовых фич и ее сертифицируете. Если же что-то пойдет не так, из такой ветки можно будет легко устранить то, что по какой-то причине из релиза в итоге выпадает. Когда же релиз произошел, релизная ветка вливается в stable trunk.
Я советую делать релизы из релизных веток, а не из транка. То есть у вас есть транк, от которого отходят ветки на конкретные фичи, соответствующие тикетам в Jira. Когда вы закончили разработку в спринте, вы собираете отдельную релизную ветку из готовых фич и ее сертифицируете. Если же что-то пойдет не так, из такой ветки можно будет легко устранить то, что по какой-то причине из релиза в итоге выпадает. Когда же релиз произошел, релизная ветка вливается в stable trunk.
— Контролировать качество кода. И наконец, code review — это, казалось бы, достаточно очевидная практика, к которой прибегают почему-то далеко не во всех проектах. Очень хорошо, если каждая часть кода проверяется более чем одним человеком. Даже в очень сильной команде в процессе code review обязательно обнаруживаются какие-то косяки, а если смотрят несколько человек, количество выявленных косяков возрастает. Иногда самое страшное находит третий или четвертый reviewer. Но во избежание как саботажа, так и излишнего фанатизма, необходимо договориться, сколько review достаточно для того, чтобы считать фичу готовой.
Для проверки можно использовать пул-реквесты (конечно, если у вас Git), далее есть Crucible и FishEye — оба прикручиваются к Jira. И наконец существует очень удобный инструмент Review Board, который работает и с SVN, и с Git. Он позволяет послать запрос на проверку кода, который соберет в себе все изменения в данном feauture branch.
Управление проектом
Подбор команды. Самое первое, что должен помнить Team Lead или PM при наборе людей в проект — далеко не всем разработчикам подходит работа с legacy-системами. Даже если человек пишет замечательный код, не факт, что он сможет целыми днями сидеть с дебаггером или документировать чужой код. Для работы с legacy, кроме технических навыков, требуются еще определенные личностные качества — хорошее чувство юмора, самоирония и, конечно же, терпение. На эти качества нужно обращать внимание при подборе людей в команду, а если кто-то не сошелся с legacy характерами, то не воевать с ним, а заменять. Замена человека в проекте в подобном случае не волчий билет, а облегчение и для него, и для команды.
Глупые вопросы. Тимлид не должен стесняться задавать команде «глупые» вопросы и напоминать обо всех вышеперечисленных приемах работы. «Я накатил свежий код, и теперь ничего не работает!» — «А какую ветку ты взял? А базу обновил? А что в логах? А дебажил?» Несмотря на всю свою простоту, такие диалоги — неотъемлемый элемент нашей работы, и в особенности с legacy-проектами. Нужно удерживать все в голове и не уставать снова и снова напоминать о каких-то очевидных и не очень очевидных вещах. Без этого, поверьте, не обойтись!
Процесс, или «здесь так принято». В силу американской текучки кадров новые менеджеры со стороны заказчика приходят в проект чаще, чем нам хотелось бы. И многие из них, еще не разобравшись в специфике legacy, пытаются внедрять практики и решения из своего предыдущего опыта. Им нужно терпеливо объяснять, почему здесь принято именно так, а не по книжке. Сначала такие вещи донести бывает трудно, но в конечном итоге либо заказчик согласится с вами, либо вы вместе придете к компромиссному решению.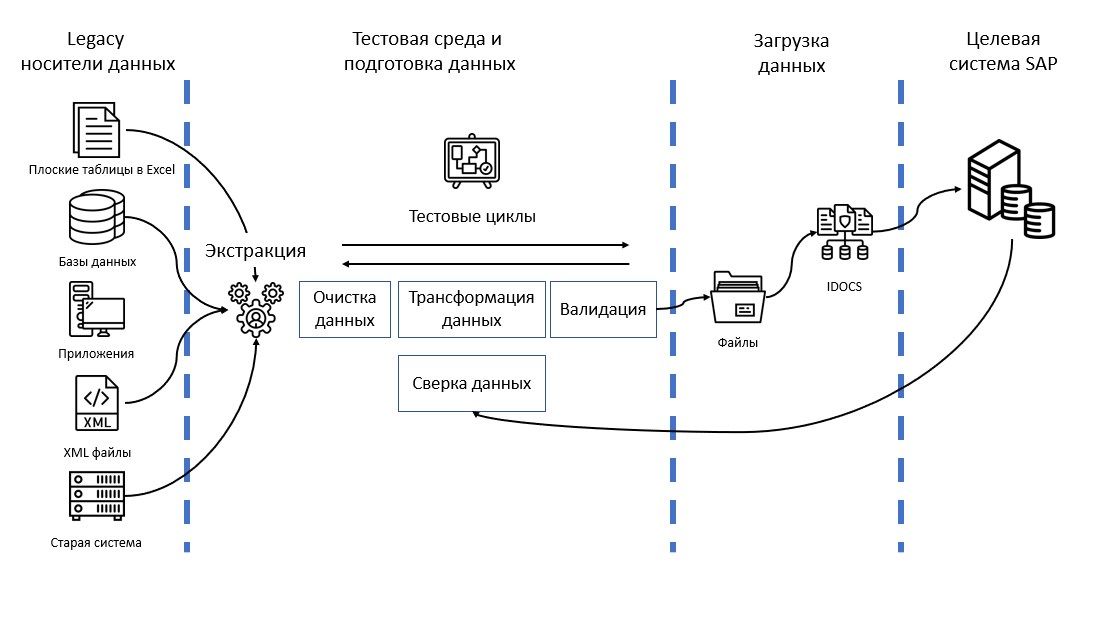
В работе с legacy-системами действительно важен правильно выстроенный, понятный и прозрачный процесс: Jira (или аналог) обязательно должна отражать реальное положение дел в данный момент. Все требования должны быть ясно сформулированы, а процессы четко прописаны. Вся эта Jira-бюрократия точно окупится, сильно снизив степень энтропии в проекте. Так, когда к вам придет заказчик и потребует срочно сделать новую фичу, вы сможете просто показать заполненное расписание. Тогда он легче сможет понять, что чем-то придется пожертвовать.
Что касается эстимэйта (вы же используете Planning Poker, правда?), то оценивать всегда нужно с запасом, чтобы быть готовым к сюрпризам — как мы уже говорили, влияния в незнакомом нам коде зачастую неясны, и порой может вылезать что-то совершенно неожиданное и в неожиданных местах. Так, у нас в проекте был случай, когда изменения в простом CSS сломали часть бизнес-логики: кто-то поставил в JS проверку на цвет элемента интерфейса.
Бизнес, tech debt и SWAT. При работе с legacy-системами нужно стараться противостоять потоку бизнес-требований, которые заказчик будет вам непрерывно поставлять. Заказчик не всегда осознает риски, связанные со стабильностью системы, поэтому вам придется постоянно о них напоминать. Бороться с этими рисками можно двумя способами: балансированием бизнес и стабилизационных задач в каждом спринте или отдельными стабилизационными проектами. Оптимальным кажется баланс 70 на 30, когда 30% времени каждого спринта вы занимаетесь стабилизацией. Впрочем, заказчик скорее всего не даст вам сделать все, что вы хотите — поэтому записывайте технический долг по мере обнаружения. Из этого tech debt вы будете брать задачи на вышеупомянутые 30%. А может, заказчик согласится на стабилизационный проект, особенно если вы покажете ему tech debt в ответ на вопрос, почему все в очередной раз упало.
При работе с legacy-системами нужно стараться противостоять потоку бизнес-требований, которые заказчик будет вам непрерывно поставлять. Заказчик не всегда осознает риски, связанные со стабильностью системы, поэтому вам придется постоянно о них напоминать. Бороться с этими рисками можно двумя способами: балансированием бизнес и стабилизационных задач в каждом спринте или отдельными стабилизационными проектами. Оптимальным кажется баланс 70 на 30, когда 30% времени каждого спринта вы занимаетесь стабилизацией. Впрочем, заказчик скорее всего не даст вам сделать все, что вы хотите — поэтому записывайте технический долг по мере обнаружения. Из этого tech debt вы будете брать задачи на вышеупомянутые 30%. А может, заказчик согласится на стабилизационный проект, особенно если вы покажете ему tech debt в ответ на вопрос, почему все в очередной раз упало.
Для экстренных случаев я советую иметь SWAT — «группы специального назначения», которые смогут быстро решать непредвиденные проблемы в любое время суток. Ведь если система вдруг завалится, заказчик тут же начнет вам звонить и в 2 часа ночи, и в 4 утра — это мы проверили на своем опыте. Поэтому хорошо бывает договориться, кто в какое время дежурит на случай таких происшествий. Это должны быть быстро соображающие люди, которые могут сидеть допоздна, соответственно, чаще всего, не семейные. Но основная их задача — это все-таки, брейнсторминг днем. В этом есть особый инженерный кайф — в стрессовой ситуации оперативно находить ошибки в чужом коде, понимая, что спасаешь мир в рамках отдельно взятой системы.
Ведь если система вдруг завалится, заказчик тут же начнет вам звонить и в 2 часа ночи, и в 4 утра — это мы проверили на своем опыте. Поэтому хорошо бывает договориться, кто в какое время дежурит на случай таких происшествий. Это должны быть быстро соображающие люди, которые могут сидеть допоздна, соответственно, чаще всего, не семейные. Но основная их задача — это все-таки, брейнсторминг днем. В этом есть особый инженерный кайф — в стрессовой ситуации оперативно находить ошибки в чужом коде, понимая, что спасаешь мир в рамках отдельно взятой системы.
Примеры оптимизации
А теперь вкратце расскажу о способах оптимизации, которыми мы пользовались в разное время.
Во-первых, нужно уйти от традиции ежедневных перезапусков, если так было принято в проекте. Однако делать это нужно, конечно, с осторожностью — продолжать проверять логи и следить за всем, что может привести к падению системы, и бороться с этим. У нас была система, которые перезапускалась каждую ночь, так как не могла прожить и двух суток из-за memory и других leaks — теперь же она совершенно стабильно работает от релиза до релиза две-три недели (за редкими исключениями, о которых мы обычно узнаем в 4 утра).
А вот хороший пример того, как делать не нужно. У нас была система, несколько компонентов которой периодически отваливались. Тогда со стороны заказчика пришел девопс и написал скрипты, которые по логам анализируют активность этих компонентов, и если в логе три минуты нет записей, то эти службы перезапускаются. Это, конечно, сработало, но такие вещи должны однажды плохо кончиться.
Очень важный момент — проход по всем логам и составление отдельного эпика. Бывают, конечно, заказчики, которые долго не дают доступа к продакшн-логу. У нас, например, так продолжалось полгода, после чего случился переломный момент, когда нас самих попросили посмотреть логи продакшна. Просмотр затянулся на всю ночь. В системе, работавшей, как считалось, штатно и стабильно, нормальные логи попадались лишь иногда — в основном же записи были со сдвигом вправо и начинались с «at». Это были сплошные стектрейсы, и их набиралось на десятки мегабайт в сутки. Конечно, мы завели эпик в Jira и создали тикеты на отдельные exceptions. Затем нам пришлось несколько месяцев выбивать время на стабилизационный проект. В итоге мы исправили множество ошибок, о которых никто не догадывался, и сделали логи информативными. Теперь любой стектрейс в них — действительно признак нештатной ситуации.
Затем нам пришлось несколько месяцев выбивать время на стабилизационный проект. В итоге мы исправили множество ошибок, о которых никто не догадывался, и сделали логи информативными. Теперь любой стектрейс в них — действительно признак нештатной ситуации.
Еще советую обращать внимание на третьесторонние зависимости как на front-end (Google Tag Manager, Adobe Tag Manager и т. п.), так и на back-end. Например, если у нас на странице есть JavaScript со сторонних ресурсов, нужно посмотреть, завернуты ли эти скрипты в try..catch блоки. У нас были случаи, когда сайт падал из-за того, что ломался какой-то скрипт на стороне. Также важно предусматривать возможность недоступности любых внешних ресурсов.
Ну и последнее: следите за всем, за чем только можно, и грамотно агрегируйте логи. Ведь у вас может быть 12 продакшн-серверов, и вас могут попросить их логи посмотреть, что точно нужно делать не через tail. Мы использовали ELK — связку Elastic search — Logstash — Kibana. Очень полезен мониторинг: мы навесили Java Melody на все серверы и получили огромное количество новой информации, на основании которой многое исправили, осчастливив заказчика.
Очень полезен мониторинг: мы навесили Java Melody на все серверы и получили огромное количество новой информации, на основании которой многое исправили, осчастливив заказчика.
P.S. Полезные ссылки:
— Виктор Полищук: «Legacy Projects. How To Win The Race» — доклад на русском о работе с унаследованными системами, основанный на конкретных примерах из опыта докладчика.
— Michael Feathers: «Working Effectively with Legacy Code» — книга по теме, которую я, честно говоря, не читал. В основном она про рефакторинг. В открытом доступе есть обширная презентация автора с тем же названием, по которой вы сможете понять, стоит ли вам покупать эту книгу.
Все про українське ІТ в Телеграмі — підписуйтеся на канал редакції DOU
Теми:
legacy, аутсорсинг, розробка
Что такое устаревшая система?
Статьи по теме
- Что такое MySQL? Все, что вам нужно знать
- Что такое промежуточное ПО? Технологический посредник
- Что такое Shadow IT? Определение, риски и примеры
- Что такое бессерверная архитектура?
- Что такое SAP?
Устаревшая система — это устаревшее программное и/или аппаратное обеспечение, которое все еще используется. Система по-прежнему отвечает потребностям, для которых она была изначально разработана, но не допускает роста. То, что унаследованная система делает для компании сейчас, это все, что она когда-либо будет делать. Старая технология устаревшей системы не позволит ей взаимодействовать с более новыми системами.
Система по-прежнему отвечает потребностям, для которых она была изначально разработана, но не допускает роста. То, что унаследованная система делает для компании сейчас, это все, что она когда-либо будет делать. Старая технология устаревшей системы не позволит ей взаимодействовать с более новыми системами.
По мере развития технологий большинство компаний сталкиваются с проблемами, вызванными существующей устаревшей системой. Вместо того, чтобы предлагать компаниям новейшие возможности и услуги, такие как облачные вычисления и улучшенная интеграция данных, устаревшая система удерживает компанию в рутинном бизнесе.
Причины, по которым компания продолжает использовать устаревшую систему, разнообразны.
- Инвестиции : Хотя поддержка устаревшей системы со временем обходится дорого, обновление до новой системы требует предварительных инвестиций, как в долларах, так и в рабочей силе.
- Страх: Меняться тяжело, и перевод целой компании или даже одного отдела на новую систему может вызвать внутреннее сопротивление.

- Сложность : Устаревшее программное обеспечение может быть создано с использованием устаревшего языка программирования, что затрудняет поиск персонала, обладающего навыками для выполнения миграции. Документации по системе может быть мало, а первоначальные разработчики покинули компанию. Иногда простое планирование переноса данных из устаревшей системы и определение объема требований для новой системы является непосильной задачей.
Проблемы, вызванные устаревшими системами
Устаревшая система может вызвать множество проблем, таких как непомерные затраты на обслуживание, хранилища данных, которые препятствуют интеграции между системами, несоблюдение государственных норм и снижение безопасности. Эти проблемы в конечном итоге перевешивают удобство продолжения использования существующей устаревшей системы.
1. Обслуживание дорого (и бесполезно)
Обслуживание требуется для любой системы, но стоимость обслуживания устаревшей системы высока.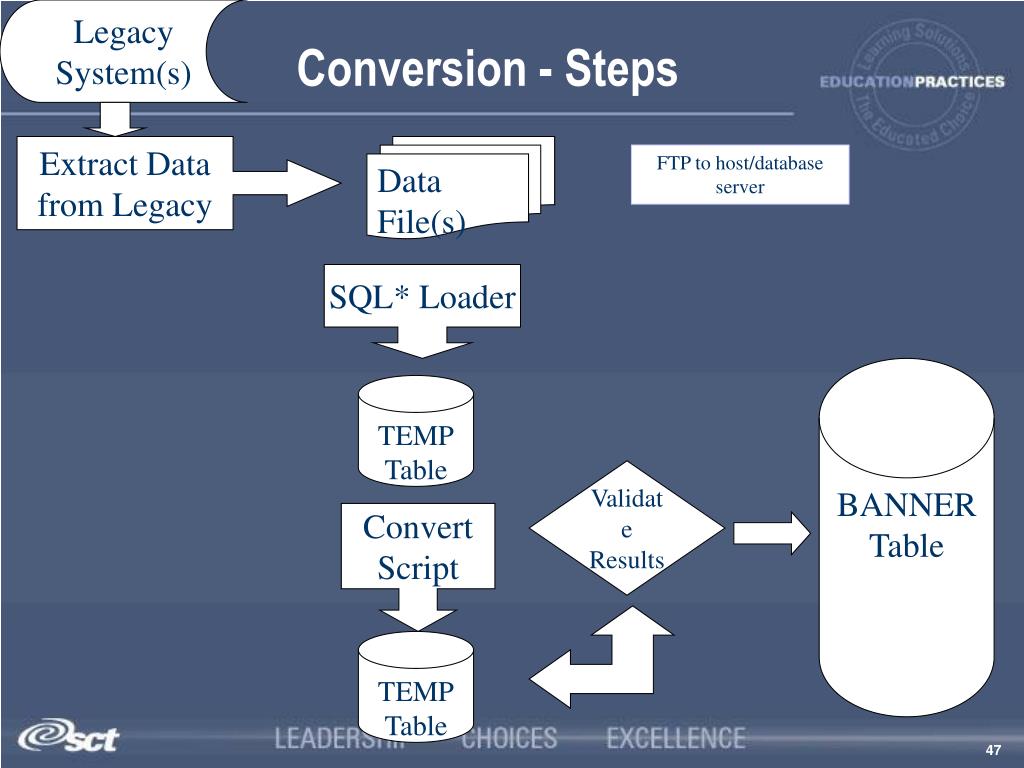 Техническое обслуживание поддерживает устаревшую систему в рабочем состоянии, но в то же время компания выбрасывает хорошие деньги за плохие. Статус-кво сохраняется, но у старой системы нет шансов на рост.
Техническое обслуживание поддерживает устаревшую систему в рабочем состоянии, но в то же время компания выбрасывает хорошие деньги за плохие. Статус-кво сохраняется, но у старой системы нет шансов на рост.
В какой-то момент прекратится поддержка устаревшей системы и обновлений. Если система дает сбой, деваться некуда.
Подумайте о слабой плотине с дырами, которые вы продолжаете затыкать и затыкать, но вода продолжает просачиваться сквозь них. Устаревшая система по-прежнему требует от компании денег на обслуживание, но никогда не предоставляет новых и инновационных услуг.
2. Данные застряли в разрозненных хранилищах
Разрозненные хранилища данных являются побочным продуктом устаревших систем. Многие старые системы никогда не были предназначены для интеграции друг с другом, а многие устаревшие программные решения построены на платформах, которые не могут интегрироваться с более новыми системами. Это означает, что каждая устаревшая система представляет собой хранилище данных.
В дополнение к разделению данных, которые они содержат, устаревшие системы не позволяют отделам, которые их используют, интегрировать данные, происходящие в остальной части организации. Если одна команда поддерживает устаревшую систему, а остальная часть компании обновляет ее, эта команда изолирована от бизнес-аналитики и информации, создаваемой в интегрированных системах.
3. Соответствие требованиям намного сложнее
Сегодня организации должны соблюдать строгие правила соответствия. Поскольку эти правила продолжают развиваться, устаревшая система может не соответствовать им.
Нормативно-правовые акты, такие как GDPR, например, требуют, чтобы компания знала (и доказывала), какие данные о клиентах у них есть, где они находятся и кто к ним обращается. Компании, располагающие данными о клиентах, должны вести хорошо управляемые записи, что намного сложнее (если вообще возможно) в устаревших, разрозненных системах.
4. Безопасность с каждым днем становится все слабее
Утечка данных может дорого обойтись компании, а устаревшие системы более уязвимы для хакеров, чем новые системы. Устаревшие системы по определению имеют устаревшие меры безопасности данных, такие как жестко закодированные пароли. Это не было проблемой, когда система была построена, но она есть сейчас.
Устаревшие системы по определению имеют устаревшие меры безопасности данных, такие как жестко закодированные пароли. Это не было проблемой, когда система была построена, но она есть сейчас.
Устаревшая система не только оставляет компанию со старыми технологиями, но и может серьезно повредить репутации компании, подвергая данные риску взлома. В какой-то момент поставщик больше не поддерживает устаревшую систему или не предоставляет столь необходимые обновления, подвергая устаревшую систему угрозе безопасности. Даже если доступно критическое обновление, его установка может быть рискованной и откладывается из-за боязни поломки системы. По мере развития технологий риски для устаревших систем возрастают.
5. Новые системы не интегрируются
По мере взросления компании необходимо добавлять новые системы, чтобы оставаться конкурентоспособными в современном мире. Но более старая технология устаревшей системы может быть не в состоянии взаимодействовать с новой системой. Отдел, все еще использующий устаревшую систему, не получит всех преимуществ, которые предлагает новая система.
Отдел, все еще использующий устаревшую систему, не получит всех преимуществ, которые предлагает новая система.
Разработка процессов, обеспечивающих совместную работу систем, обременительна и по-прежнему подвергает компанию рискам безопасности. Это вызывает неспособность к технологическому росту внутри компании.
Ключ к обновлению устаревших систем: успешный перенос данных
Самое главное при обновлении устаревшей системы — защитить уже существующие данные. Это можно сделать только путем успешной миграции данных.
Представьте себе больницу с десятками тысяч исторических записей о пациентах в устаревшей системе. Было бы разрушительно потерять эту информацию из-за небезопасной устаревшей системы. Было бы не менее разрушительно потерять эту информацию из-за плохой миграции данных.
Успешный перенос данных включает:
- Извлечение существующих данных. Данные в существующих устаревших системах могут быть разрозненными, раздробленными, дублированными или неполными. Он может существовать в различных хранилищах данных и в различных форматах. Миграция данных из устаревшей системы начинается с обеспечения безопасного извлечения всех данных.
- Преобразование данных для соответствия новым форматам. Данные преобразуются в соответствии с требованиями новой системы посредством отображения данных. Редко данные из устаревших систем точно соответствуют новой системе. Этот шаг жизненно важен для обеспечения того, чтобы новая система понимала данные из устаревшей системы.
- Очистка данных для устранения проблем с качеством. Во время процесса миграции самое время очистить данные, избавившись от дубликатов, неполных данных и данных, которые не отформатированы должным образом. Устаревшая система с телефонными номерами, содержащими тире, не будет работать с новой системой, которая их не допускает.
- Проверка данных, чтобы убедиться, что перемещение идет по плану. После извлечения, преобразования и очистки данных импортируется выборочный набор данных для проверки на наличие проблем и ошибок. Это устраняет потенциальные проблемы до запуска новой системы.
- Загрузка данных в новую систему. Последним шагом к успешному переносу данных является загрузка всех данных в новую систему, чтобы она была готова к использованию.
 Он может существовать в различных хранилищах данных и в различных форматах. Миграция данных из устаревшей системы начинается с обеспечения безопасного извлечения всех данных.
Он может существовать в различных хранилищах данных и в различных форматах. Миграция данных из устаревшей системы начинается с обеспечения безопасного извлечения всех данных. Это устраняет потенциальные проблемы до запуска новой системы.
Это устраняет потенциальные проблемы до запуска новой системы.Миграция устаревшей системы финансовой отрасли
Money Super Market необходимо обновить свою устаревшую ETL до современной, более конкурентоспособной системы. Было необходимо предложить своим клиентам более быстрое обслуживание, а их устаревшая система не могла этого сделать.
После простого перехода от устаревшей системы Money Super Market улучшила свои инструменты сравнения продуктов для клиентов, а также увеличила продажи.
Миграция устаревшей системы государственного сектора
Региональный совет Лангедок-Руссильона занимается экономическим ростом в пяти регионах Франции. Его успех может затронуть до 2,5 миллионов человек и 127 000 компаний.
Совет отказался от своей устаревшей системы в пользу решения с открытым исходным кодом, которое обеспечивает доступный постепенный рост. Совет теперь тратит меньше времени и денег на техническое обслуживание и имеет гораздо более четкое представление о том, что происходит в каждом регионе.
Совет теперь тратит меньше времени и денег на техническое обслуживание и имеет гораздо более четкое представление о том, что происходит в каждом регионе.
Начните миграцию устаревшей системы
Устаревшие системы часто встраиваются из-за удобства. Но правда в том, что это стоит времени и денег и обрекает компанию на провал.
Одним из ключей к успешной миграции является интеграция данных — объединение данных, находящихся в разных источниках. Это поощряет сотрудничество как между внутренними пользователями, так и между внешними пользователями. Еще один ключ — безопасность. Подумайте, сколько компаний в последнее время столкнулись с коллективными исками из-за утечки данных, не говоря уже об ущербе, который эти нарушения наносят репутации компании. Перед любой миграцией должны быть проведены проверки безопасности.
Перспективные решения для интеграции данных, такие как Talend Data Fabric, упрощают, казалось бы, непосильную задачу переноса данных. Talend Data Fabric защищает компанию:
- Управление данными во всех средах (включая мультиоблачные и локальные).
- Предоставление встроенных возможностей машинного обучения, качества данных и управления.
- Предоставление полной поддержки жизненного цикла разработки API.
- Предлагается модель ценообразования на основе пользователей без скрытых платежей.

Не позволяйте страху отказа от устаревшей системы поставить под угрозу вашу компанию. Миграция данных может быть выполнена гладко с помощью правильных инструментов. Попробуйте Talend Data Fabric сегодня, чтобы безопасно перенести данные со скоростью бизнеса.
Что такое устаревшая система и устаревшие приложения?
ITОперации
К
- Ник Барни,
Технический писатель - Маргарет Роуз
- Эмили Мелл,
Бывший редактор сайта
Что такое устаревшая система?
Устаревшая система — это любая устаревшая вычислительная система, аппаратное или программное обеспечение, которое все еще используется. Устаревшие системы включают в себя компьютерное оборудование, программные приложения, форматы файлов и языки программирования. Однако не все устаревшие системы являются устаревшими технологиями. Большинство устаревших систем работают, даже если они устарели, и предприятия часто продолжают использовать устаревшие системы, которые имеют решающее значение для их повседневных функций и бизнес-потребностей.
Устаревшие системы включают в себя компьютерное оборудование, программные приложения, форматы файлов и языки программирования. Однако не все устаревшие системы являются устаревшими технологиями. Большинство устаревших систем работают, даже если они устарели, и предприятия часто продолжают использовать устаревшие системы, которые имеют решающее значение для их повседневных функций и бизнес-потребностей.
Приложения, системы и другие технологии становятся устаревшими ИТ-системами по следующим причинам:
- Они больше не получают обновления, поддержку или техническое обслуживание от своих разработчиков или создателей программного обеспечения.
- Они больше не доступны для покупки или зависят от устаревшей технологии для запуска и обслуживания.
- В случае аппаратного обеспечения, такого как мэйнфреймы, они больше не могут поддерживать программное обеспечение организации.
- Для обслуживания системы требуются ИТ-специалисты со сложными, в значительной степени устаревшими технологическими навыками, такими как Common Business-Oriented Language или COBOL, программирование. Таких специалистов бывает трудно найти, а их найм обходится дорого.
- Ремонт занимает слишком много времени по сравнению с новыми системами.
- Затраты на техническое обслуживание становятся слишком высокими для продолжения.
- Они чрезмерно подвержены уязвимостям безопасности и не могут быть обновлены для соответствия современным стандартам кибербезопасности.
 Таких специалистов бывает трудно найти, а их найм обходится дорого.
Таких специалистов бывает трудно найти, а их найм обходится дорого.Продажа, техническое обслуживание и обслуживание клиентов — все это влияет на то, устарела ли система.
Что такое устаревшие приложения?
Устаревшее приложение или устаревшее приложение — это программа, которая устарела или устарела. Хотя устаревшее приложение все еще работает, оно может быть нестабильным из-за проблем совместимости с текущими операционными системами (ОС), браузерами и ИТ-инфраструктурами.
Большинство предприятий используют устаревшие приложения и компьютерные системы, которые продолжают удовлетворять критически важные потребности бизнеса. Как правило, задача состоит в том, чтобы поддерживать работоспособность устаревшего приложения при его преобразовании в новый, более эффективный код, использующий современные технологии и языки программирования.
Как правило, задача состоит в том, чтобы поддерживать работоспособность устаревшего приложения при его преобразовании в новый, более эффективный код, использующий современные технологии и языки программирования.
Устаревшее приложение часто привязано к определенной версии ОС или языку программирования. Например, приложение, созданное для работы в Windows 7, может не работать в Windows 10, несмотря на промежуточное ПО или связующий код, добавленный группой разработчиков приложений, или ОС, как правило, обратно совместима.
Типы устаревших систем
Ниже приведены четыре распространенных типа устаревших систем:
- Конец срока службы (EOL). Устаревшие системы EOL — это системы, для которых поставщик или разработчик прекратил поддержку или предложения обновлений или которые больше нельзя приобрести.
- Невозможность масштабирования. Эти устаревшие системы больше не обладают масштабируемостью для поддержки растущих потребностей бизнеса в данных, производительности или безопасности.
- Сильно исправленное программное обеспечение. Большая часть устаревшего программного обеспечения — это устаревшее программное обеспечение, которое в прошлом было исправлено, чтобы поддерживать его в актуальном состоянии. Обширное исправление — и особенно неполное исправление — может сделать программное обеспечение более уязвимым для нарушений безопасности, чем современные приложения, и привести к его прекращению.
- Никто не знает, как его обслуживать. Для обслуживания многих устаревших систем требуются устаревшие знания. Это затрудняет и удорожает поиск ИТ-эксперта, который знает, как его поддерживать.
 Устаревшие системы EOL — это системы, для которых поставщик или разработчик прекратил поддержку или предложения обновлений или которые больше нельзя приобрести.
Устаревшие системы EOL — это системы, для которых поставщик или разработчик прекратил поддержку или предложения обновлений или которые больше нельзя приобрести.
Классификация устаревших систем — это первый шаг к пониманию того, следует ли их модернизировать или нет.
Почему до сих пор используются устаревшие системы и приложения?
Организации продолжают использовать устаревшие системы и приложения по следующим причинам:
- Они все еще работают. Многие устаревшие системы и приложения работают и важны для повседневной работы бизнеса. Замена систем и технологий, которые все еще работают просто потому, что они устарели, не всегда необходима.
- Затраты. Стоимость замены устаревшей системы или приложения может быть высокой. Хотя поддержка устаревших систем может стоить предприятиям больше денег в долгосрочной перспективе, некоторые организации не имеют немедленных ресурсов для модернизации своих систем. Модернизация также может потребовать длительных периодов времени, переподготовки персонала или найма персонала для изучения и внедрения новых технологий. Некоторые организации также хранят устаревшие системы, потому что они еще не окупили инвестиции в них.
- Сложности и проблемы. Модернизация устаревших систем может быть сложной задачей. Некоторые организации не обладают необходимыми навыками для модернизации своих систем и решения проблем, которые могут возникнуть при этом. Задержки обслуживания, потеря данных и плохое взаимодействие с пользователем также могут быть результатом миграции.
 Некоторые организации также хранят устаревшие системы, потому что они еще не окупили инвестиции в них.
Некоторые организации также хранят устаревшие системы, потому что они еще не окупили инвестиции в них.Риски сохранения устаревших систем и приложений
Существует несколько рисков, связанных с сохранением устаревших систем и приложений, в том числе следующие:
- Техническое обслуживание и эксплуатационные расходы. Многие организации сохраняют устаревшие системы и приложения из-за высоких затрат на их замену. Однако поддержание устаревших технологий в долгосрочной перспективе может быть дорогостоящим. Устаревшие системы не будут обновляться их разработчиками. В результате они требуют постоянного обслуживания со стороны ИТ-специалистов. Со временем эти затраты могут перевесить преимущества сохранения статус-кво.
- Производительность. Когда группа разработчиков программного обеспечения поставщика больше не поддерживает приложение, операционной группе может быть сложно поддерживать работу программного обеспечения. По мере старения устаревших систем их дальнейшее использование может привести к снижению производительности, увеличению потребления ресурсов и более частым сбоям и сбоям. Сохранение старых технологий также не позволяет организациям использовать преимущества новых технологий и может ослабить их конкурентное преимущество по сравнению с более модернизированными конкурентами. Многие устаревшие системы также не могут интегрироваться с более новыми системами, что может снизить функциональность организаций, использующих сочетание старых и новых технологий.
- Хранилища данных. Хранилище данных — это хранилище данных, которое нельзя интегрировать или использовать совместно с различными подразделениями бизнеса. Многие устаревшие программные системы не могут интегрироваться с новым программным обеспечением, а это означает, что данные, хранящиеся в более старой системе в рамках бизнеса, не могут быть переданы другим отделам, использующим более новые технологии.
- Соответствие. Устаревшие системы могут не соответствовать стандартам правил соответствия данных, таких как Закон о переносимости и подотчетности медицинского страхования и Общее положение о защите данных. Несоблюдение этих правил может привести к штрафам и другим наказаниям, а также к негативной рекламе и нарушениям безопасности.
- Поддержка и безопасность. Устаревшие системы не получают техническую поддержку или обновления от своих разработчиков и зависят от устаревших мер безопасности или исправлений для предотвращения нарушений. Это делает их уязвимыми к утечкам данных, которые обходятся организациям в среднем в 4,35 миллиона долларов, согласно отчету IBM «Стоимость утечки данных» за 2022 год, подготовленному Ponemon Institute.
 В результате они требуют постоянного обслуживания со стороны ИТ-специалистов. Со временем эти затраты могут перевесить преимущества сохранения статус-кво.
В результате они требуют постоянного обслуживания со стороны ИТ-специалистов. Со временем эти затраты могут перевесить преимущества сохранения статус-кво. Многие устаревшие программные системы не могут интегрироваться с новым программным обеспечением, а это означает, что данные, хранящиеся в более старой системе в рамках бизнеса, не могут быть переданы другим отделам, использующим более новые технологии.
Многие устаревшие программные системы не могут интегрироваться с новым программным обеспечением, а это означает, что данные, хранящиеся в более старой системе в рамках бизнеса, не могут быть переданы другим отделам, использующим более новые технологии.
Модернизация и миграция устаревших систем
Устаревшие системы и приложения не могут поддерживаться на функциональном уровне вечно. В какой-то момент большинство предприятий обновят или заменят устаревшее оборудование, язык кодирования, ОС и программное обеспечение.
Модернизация и миграция устаревшей системы и программного обеспечения часто включает рефакторинг, то есть реструктуризацию кода системы для обеспечения его совместимости с новой платформой. Предприятие, проводящее модернизацию или миграцию устаревшей системы, должно сначала оценить, какие компоненты его системы нуждаются в решении. Исследовательские фирмы, такие как Gartner, предлагают организациям выполнить следующие шаги:
- Определите, какие компоненты системы или приложения больше не соответствуют стандартам или требованиям для бизнес-процессов и должны быть модернизированы или обновлены. Организации должны учитывать функциональность и стоимость.
- Оцените варианты модернизации или миграции. Например, команда рассматривает возможность перехода к подходу «программное обеспечение как услуга» с интерфейсами прикладного программирования или API, которые освобождают приложение от привязки к конкретной ОС и упрощают будущие обновления. Предприятие также может перераспределять расположение своего приложения и данных между локальными центрами обработки данных и общедоступными облачными платформами, используя инфраструктуру как услугу.
- Выберите вариант, который наиболее выгоден для архитектуры, масштабируемости и функциональности организации.
Рефакторинг — это лишь один из нескольких полезных методов модернизации устаревших систем.
После выбора метода становится важным перенос данных. Это также часто включает в себя преобразование данных и следующие шаги:
- Добыча. Извлечение данных может быть затруднено, поскольку многие данные, хранящиеся в устаревших системах, разрознены или хранятся в устаревших форматах. Прежде чем начать миграцию данных, организации должны убедиться, что критически важные для бизнеса данные могут быть извлечены.
- Отображение данных. Данные должны быть преобразованы в форматы и требования новой системы с помощью преобразования данных. Часто старые данные не соответствуют точно новой информационной системе.
- Обновление данных. Все неполные и не подлежащие передаче данные должны быть удалены, а все повторяющиеся данные дедуплицированы.
- Протестируйте миграцию. Организации должны провести тест на примере набора данных. Таким образом, ошибки и ошибки могут быть выявлены до того, как начнется реальный перенос данных.
- Перенос данных. После того, как организации извлекли, сопоставили, обновили и протестировали свои данные, они могут безопасно перенести их на новую платформу.
Это шаги, которые предпринимают предприятия при модернизации устаревшей системы.
Примеры устаревшей системы
Устаревшие системы имеют решающее значение для многих организаций, таких как банки и государственные учреждения. Эти организации зависят от проверенных, последовательных и многоразовых технологий, разработка которых часто требует больших затрат, а замена — непомерно дорого. Примеры включают следующее:
- Космический корабль NASA Orion . Космический корабль NASA Orion работает на устаревших одноядерных процессорах IBM PowerPC 750X, разработанных в 2002 году.
- Microsoft Internet Explorer (IE). Microsoft прекратила поддержку всех версий Internet Explorer до версии 11 в январе 2020 года. Поддержка IE11 закончилась в июне 2022 года. Организации могут использовать режим IE в Microsoft Edge для доступа к приложениям и веб-сайтам, которые по-прежнему используют IE.
Устаревшие системы часто переносятся в облако. Выясните, какая служба миграции в облако соответствует вашим потребностям в данных и сервере.
Последнее обновление: ноябрь 2022 г.
Продолжить чтение О устаревшей системе (устаревшее приложение)
- 12 лучших практик переноса данных ERP в облако
- Контрольный список миграции данных HR и советы по успешному внедрению
- Устаревшие уязвимости могут быть самым большим корпоративным киберриском
- Виртуализация приложений вдохнет цифровую жизнь в устаревшие приложения
- Решение обновить устаревшую систему ERP или заменить ее
Углубитесь в управление и мониторинг ИТ-систем
5 советов по созданию плана миграции приложений ИТ-операций
Автор: Стюарт Бернс
разрастание контента
Автор: TechTarget Contributor
Как финансовые услуги могут ускорить переход к более экологичному миру
Столкнувшись с растущим спросом, 3 компании обращаются к S/4HANA Cloud
Автор: Джим О’Доннелл
Качество ПО
-
Тестовые фреймворки и примеры для модульного тестирования кода PythonМодульное тестирование является важным аспектом разработки программного обеспечения.
Команды могут использовать Python для модульного тестирования, чтобы оптимизировать преимущества Python… -
Атрибуты эффективной стратегии тестирования базы данныхКоманды должны внедрить правильную стратегию тестирования базы данных для оптимизации результатов. Изучите эффективные атрибуты тестирования базы данных…
-
Обновления Java 20 Project Loom готовят почву для Java LTSJava 20 повторно инкубирует две функции масштабируемости Project Loom, что делает их главными кандидатами на то, чтобы стать стандартом в сентябрьском Java…
Архитектура приложения
-
Необработанный, но растущий потенциал банковского обслуживания без ядраХотя банковское обслуживание без ядра все еще является новой концепцией, оно демонстрирует большой потенциал для освобождения банков от жестких программных систем, которые…
-
Основы достижения высокой сплоченности и низкой связанностиЛегко сказать: «высокая сплоченность, низкая связанность», но так ли легко это реализовать на практике? Мы рассмотрим некоторые основы.
.. -
Как обнаружить и контролировать распространение теневых APIТеперь, когда проникновение через API стало излюбленным методом хакеров, ИТ-специалистам необходимо предпринять дополнительные шаги для защиты этих…
Облачные вычисления
-
4 рекомендации, чтобы избежать привязки к поставщику облачных услугБез надлежащего планирования организация может оказаться в ловушке отношений с облачным провайдером. Следуйте этим …
-
Подходит ли вам облачная стратегия?Стратегия, ориентированная на облачные технологии, имеет свои преимущества и недостатки. Узнайте, как избежать рисков и построить стратегию, которая …
-
Как использовать сценарии запуска в Google CloudGoogle Cloud позволяет использовать сценарии запуска при загрузке виртуальных машин для повышения безопасности и надежности.
Выполните следующие действия, чтобы создать свой…
ПоискAWS
-
AWS Control Tower стремится упростить управление несколькими учетными записямиМногие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Сервис автоматизирует …
-
Разбираем модель ценообразования Amazon EKSВ модели ценообразования Amazon EKS есть несколько важных переменных. Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу…
-
Сравните EKS и самоуправляемый Kubernetes на AWSПользователи AWS сталкиваются с выбором при развертывании Kubernetes: запускать его самостоятельно на EC2 или позволить Amazon выполнять тяжелую работу с помощью EKS. См…
TheServerSide.com
-
Как применить принцип единой ответственности в JavaКак работает модель единой ответственности в программе Java? Здесь мы покажем вам, что означает этот принцип SOLID и как .
.. -
3 ежедневных вопроса ScrumВ Руководстве по Scrum 2020 удалены все ссылки на три ежедневных вопроса Scrum, но означает ли это, что вам больше не следует их задавать?
-
Почему WebAssembly? 11 основных преимуществ WasmЗадержка и время задержки досаждают веб-приложениям, которые запускают JavaScript в браузере. Вот 11 причин, по которым WebAssembly имеет …
Центр обработки данных
-
4 модуля PowerShell, которые должен знать каждый ИТ-специалистУзнайте, как использовать четыре самых популярных модуля сообщества PowerShell в галерее PowerShell, чтобы лучше управлять своим …
-
Система Nvidia DGX Quantum объединяет процессоры, графические процессоры с CUDANvidia и Quantum Machines предлагают новую архитектуру, сочетающую центральные и графические процессоры с квантовыми технологиями.
