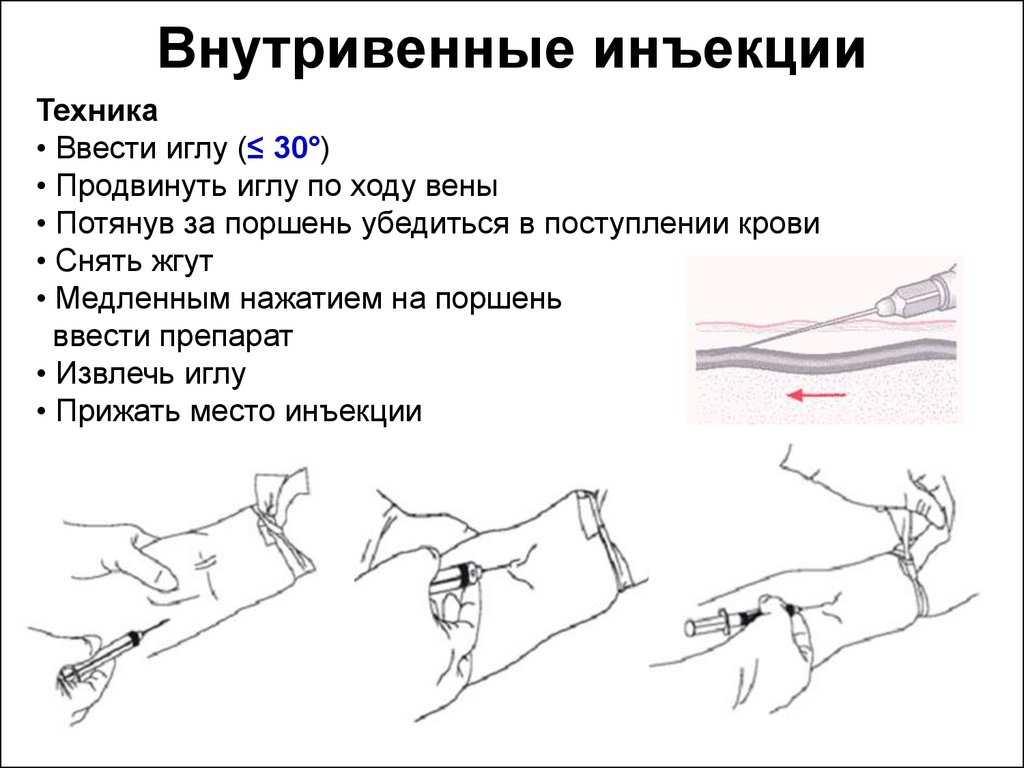
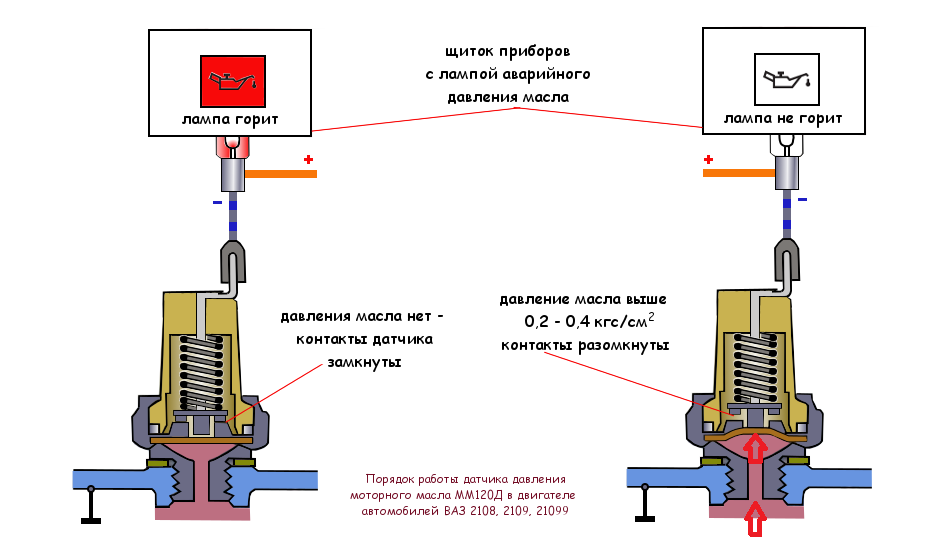
Как проверить медленно: МедлеННо проверочное слово — ответ на Uchi.ru
Содержание
Сведения о производительности iOS или iPadOS на iPhone, iPad или iPod touch
Если ваше устройство iOS или iPadOS медленно работает или зависает, воспользуйтесь этими советами.
Проверьте состояние сети
Чтобы просматривать содержимое и использовать другие функции, для многих приложений на вашем устройстве требуется подключение к Интернету. Если сеть, к которой вы подключены, перегружена (например, ее одновременно использует большое количество пользователей), приложения могут открываться или отображать содержимое с задержкой. Когда вы едете куда-то в транспорте, может также показаться, что ваше устройство медленно работает, поскольку оно каждый раз подключается к новым вышкам сотовой связи.
Даже если на вашем устройстве хороший уровень сигнала подключения к сети, возможно, нужно немного подождать, а потом попробовать подключиться снова в другом месте или воспользоваться доступной сетью Wi-Fi. Если проблемы со скоростью передачи данных в сотовой сети, ее доступностью или производительностью в разных местах продолжают возникать, свяжитесь со своим оператором.
Подробнее о передаче данных в сотовой сети.
Закройте приложения, которые не отвечают
Если приложение перестает отвечать или зависает, возможно, потребуется принудительно завершить его работу, а затем открыть снова*.
- На экране «Домой» iPhone X или более поздних моделей либо на iPad: смахните вверх от нижней части экрана и ненадолго задержите палец в центре экрана. На iPhone 8 или более ранних моделей: дважды нажмите кнопку «Домой», чтобы отобразить недавно открытые приложения.
- Смахивайте вправо или влево, пока не найдете приложение, работу которого требуется завершить.
- Чтобы завершить работу приложения, смахните вверх экран его предварительного просмотра.
* В нормальных условиях нет необходимости в принудительном закрытии приложений. От этого ваше устройство не станет работать быстрее. На самом деле после принудительного закрытия приложения открываются дольше, потому что им необходимо повторно загрузить все свои данные.
Узнайте, что делать, если приложение по-прежнему не отвечает.
Убедитесь, что в хранилище достаточно свободного места
Если на устройстве осталось мало свободного места, iOS или iPadOS автоматически освобождает его при установке приложений, обновлении операционной системы, загрузке музыки, записи видео и т. д. iOS или iPadOS удаляет только элементы, которые больше не нужны или могут быть загружены повторно.
Количество свободного места на устройстве можно узнать в меню «Настройки» > «Основные» > «Хранилище [устройства]». Для оптимальной производительности требуется не менее 1 ГБ свободного пространства. Если свободного места на устройстве всегда меньше 1 ГБ, оно может начать работать медленнее, так как iOS регулярно освобождает место для нового содержимого.
Если необходимо освободить место, следуйте инструкциям, чтобы включить встроенные в iOS или iPadOS рекомендации по экономии места на устройстве.
- Перейдите в меню «Настройки» > «Основные» > «Хранилище [устройства]» и ознакомьтесь с возможными рекомендациями iOS или iPadOS.

- Нажмите «Вкл.», чтобы включить рекомендацию, или ее название, чтобы просмотреть содержимое, которое можно удалить.
Если рекомендации не отображаются или нужно освободить еще больше места, можно просмотреть приложения на устройстве. Они перечислены в том же разделе «Хранилище [устройства]», где также указан объем памяти, который они занимают.
Выберите приложение, а затем — нужный вариант.
- Выгрузить приложение, что позволит освободить занимаемое им пространство, но при этом останутся документы и данные этого приложения.
- Удалить приложение и связанные с ним данные.
- В зависимости от приложения может потребоваться удалить также некоторые связанные документы и данные.
Другие способы оптимизации хранилища.
Если вы не используете режим энергосбережения, выключайте его
Режим энергосбережения — это функция iPhone и iPad, которая продлевает время работы от аккумулятора, сокращая количество потребляемой вашим устройством энергии.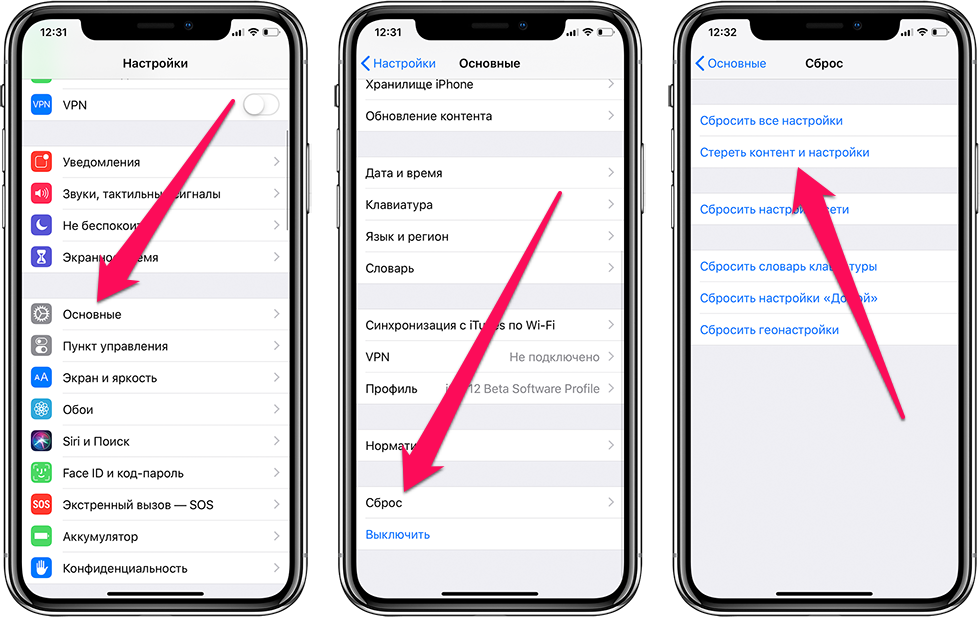 В этом режиме некоторые функции отключены, а на выполнение некоторых задач может уходить больше времени. Если отображается желтый значок аккумулятора, это означает, что включен режим энергосбережения.
В этом режиме некоторые функции отключены, а на выполнение некоторых задач может уходить больше времени. Если отображается желтый значок аккумулятора, это означает, что включен режим энергосбережения.
Если вам не нужны ограничения в отношении энергосбережения для iPhone или iPad, рекомендуется выключать этот режим. Включить или выключить режим энергосбережения можно в меню «Настройки» > «Аккумулятор».
Подробнее о режиме энергосбережения.
Не давайте устройству перегреваться или переохлаждаться
iOS или iPadOS регулирует производительность устройства, если оно перегревается из-за воздействия внешних условий, например в нагретом автомобиле или в результате длительного попадания на него прямого солнечного света. Перенесите устройство в более прохладное место и дайте время ему остыть.
Очень низкие температуры также могут замедлить работу вашего устройства. Если устройство медленно работает после нахождения на холоде, переместите его в более теплое место.
Подробнее о допустимой рабочей температуре.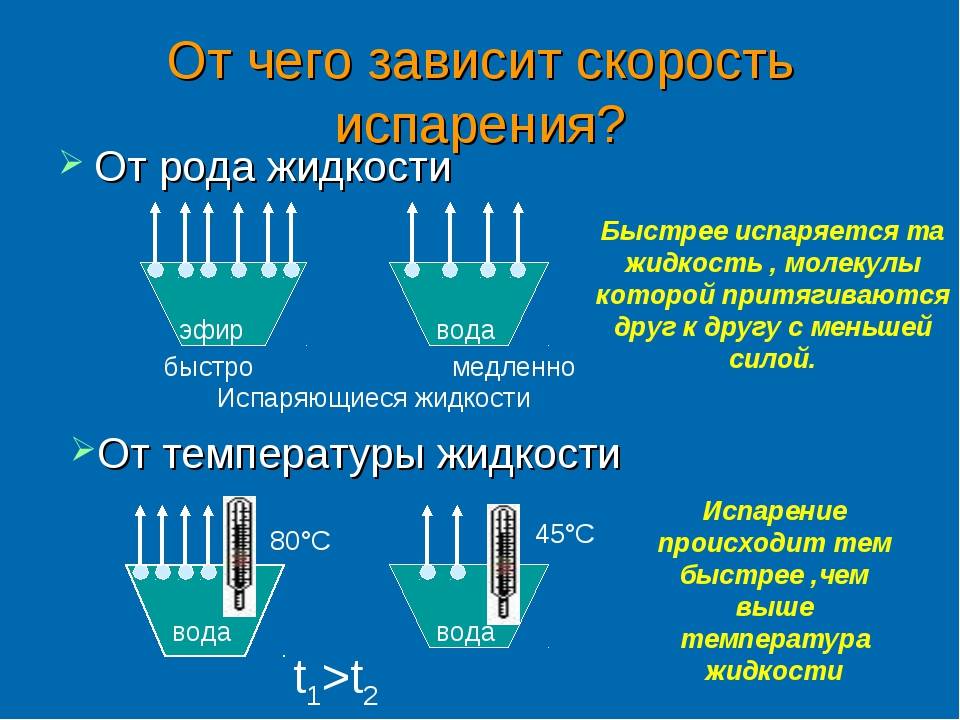
Следите за состоянием аккумулятора
Все перезаряжаемые аккумуляторы являются расходными компонентами, производительность которых снижается по мере химического старения. С течением времени емкость и пиковая производительность аккумулятора на любых моделях iPhone снижаются, в связи с чем требуется замена аккумулятора. В iOS можно просмотреть состояние аккумулятора iPhone и узнать, следует ли его заменить. Перейдите в меню «Настройки» > «Аккумулятор» и выберите «Состояние аккумулятора». Информация о состоянии аккумулятора доступна только на iPhone.
Проверьте состояние аккумулятора iPhone.
Дополнительная помощь
- Если сенсорный экран неправильно реагирует на касания, может сложиться впечатление, что устройство медленно работает. Если вы считаете, что сенсорный экран неправильно реагирует на касания, попробуйте перезагрузить свой iPhone, iPad или iPod touch. Если это не помогает и проблема возникает в одной и той же области экрана в нескольких приложениях, возможно, вам придется обратиться в службу поддержки Apple.
- Если после выполнения указанных действий ваш iPhone, iPad или iPod touch все еще работает медленно или продолжает зависать, обратитесь в службу поддержки Apple.

Информация о продуктах, произведенных не компанией Apple, или о независимых веб-сайтах, неподконтрольных и не тестируемых компанией Apple, не носит рекомендательного или одобрительного характера. Компания Apple не несет никакой ответственности за выбор, функциональность и использование веб-сайтов или продукции сторонних производителей. Компания Apple также не несет ответственности за точность или достоверность данных, размещенных на веб-сайтах сторонних производителей. Обратитесь к поставщику за дополнительной информацией.
Дата публикации:
Устранение неполадок с медленно выполняемыми запросами — SQL Server
-
Статья -
- Чтение занимает 10 мин
-
Оригинальная версия продукта: SQL Server
Исходный номер базы знаний: 243589
Введение
В этой статье описывается, как устранить проблемы с производительностью, с которыми могут столкнуться приложения базы данных при использовании SQL Server: низкая производительность определенного запроса или группы запросов. Следующая методология поможет вам сузить причину проблемы с медленными запросами и направить вас на решение.
Следующая методология поможет вам сузить причину проблемы с медленными запросами и направить вас на решение.
Поиск медленных запросов
Чтобы определить проблемы с производительностью запросов в экземпляре SQL Server, начните с изучения запросов по времени их выполнения (затраченное время). Проверьте, превышает ли время установленное пороговое значение (в миллисекундах) на основе установленного базового плана производительности. Например, в среде нагрузочного тестирования может быть установлено пороговое значение для рабочей нагрузки, не превышающее 300 мс, и вы можете использовать это пороговое значение. Затем можно определить все запросы, которые превышают это пороговое значение, сосредоточившись на каждом отдельном запросе и его предварительно установленной базовой продолжительности производительности. В конечном счете, бизнес-пользователи заботятся об общей продолжительности запросов к базе данных; Поэтому основное внимание уделяется длительности выполнения. Другие метрики, такие как время ЦП и логические операции чтения, собираются для сужения области исследования.
Для текущего выполнения инструкций проверьте total_elapsed_time и cpu_time столбцы в sys.dm_exec_requests. Выполните следующий запрос, чтобы получить данные:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;Проверьте, last_elapsed_time и last_worker_time столбцы в sys.dm_exec_query_stats.
‘ in the query should be escaped.
ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCПримечание.
Если
avg_wait_timeотображается отрицательное значение, это параллельный запрос.Если вы можете выполнить запрос по запросу в SQL Server Management Studio (SSMS) или Azure Data Studio, выполните его с помощью команды SET STATISTICS TIME
ONи SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFF
Затем в разделе Сообщения вы увидите время ЦП, затраченное время и логические операции чтения следующим образом:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.
Если вы можете собрать план запроса, проверьте данные из свойств плана выполнения.
Выполните запрос с включением фактического плана выполнения в.
Выберите самый левый оператор в разделе План выполнения.
В разделе Свойства разверните свойство QueryTimeStats .
Установите флажки ElapsedTime и CpuTime.
 ‘ in the query should be escaped.
‘ in the query should be escaped.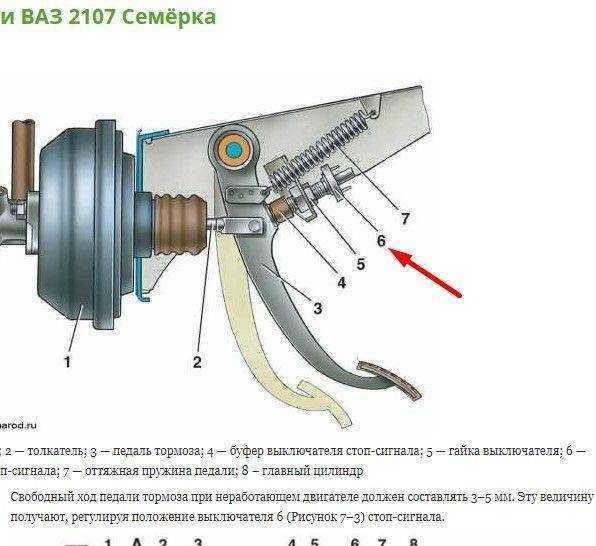
Выполнение и ожидание: почему запросы выполняются медленно?
Если вы нашли запросы, которые превышают предопределенное пороговое значение, проверьте, почему они могут быть медленными. Причины проблем с производительностью можно сгруппировать в две категории: выполняющаяся или ожидающая:
ОЖИДАНИЕ. Запросы могут выполняться медленно, так как они долго ждут узкого места. См. подробный список узких мест в типах ожиданий.
ВЫПОЛНЕНИЕ.
Запросы могут выполняться медленно, так как они выполняются (выполняются) в течение длительного времени. Другими словами, эти запросы активно используют ресурсы ЦП.
 Запросы могут выполняться медленно, так как они выполняются (выполняются) в течение длительного времени. Другими словами, эти запросы активно используют ресурсы ЦП.
Запросы могут выполняться медленно, так как они выполняются (выполняются) в течение длительного времени. Другими словами, эти запросы активно используют ресурсы ЦП.Запрос может выполняться в течение некоторого времени и ожидать некоторое время в течение своего времени существования (длительности). Тем не менее, ваше внимание заключается в том, чтобы определить, какая из них является доминирующей категорией, которая вносит свой вклад в его длительное время. Поэтому первая задача заключается в том, чтобы определить, в какую категорию попадают запросы. Все просто: если запрос не выполняется, он ожидает. В идеале запрос тратит большую часть затраченного времени в состоянии выполнения и очень мало времени на ожидание ресурсов. Кроме того, в лучшем случае запрос выполняется в пределах предопределенного базового плана или ниже нее. Сравните затраченное время и время ЦП запроса, чтобы определить тип проблемы.
Тип 1: привязанный к ЦП (средство выполнения)
Если время ЦП близко, равно или больше затраченного времени, его можно рассматривать как запрос, связанный с ЦП. Например, если затраченное время составляет 3000 миллисекунда (мс), а время ЦП — 2900 мс, это означает, что большая часть затраченного времени тратится на ЦП. Затем можно сказать, что это запрос, привязанный к ЦП.
Например, если затраченное время составляет 3000 миллисекунда (мс), а время ЦП — 2900 мс, это означает, что большая часть затраченного времени тратится на ЦП. Затем можно сказать, что это запрос, привязанный к ЦП.
Примеры выполнения запросов (привязанных к ЦП):
| Затраченное время (мс) | Время ЦП (мс) | Чтение (логическое) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
Логические операции чтения — чтение страниц данных и индексов в кэше — чаще всего являются драйверами использования ЦП в SQL Server. Могут быть сценарии, в которых использование ЦП происходит из других источников: цикл while (в T-SQL или другом коде, например XProcs или объектах SQL CRL). Второй пример в таблице иллюстрирует такой сценарий, в котором большая часть ЦП не является результатом операций чтения.
Примечание.
Если время ЦП больше длительности, это означает, что выполняется параллельный запрос; несколько потоков используют ЦП одновременно. Дополнительные сведения см. в разделе Параллельные запросы — средство выполнения или официант.
Дополнительные сведения см. в разделе Параллельные запросы — средство выполнения или официант.
Тип 2: ожидание на узком месте (официант)
Запрос ожидает узкого места, если затраченное время значительно больше времени ЦП. Затраченное время включает время выполнения запроса на ЦП (время ЦП) и время ожидания освобождения ресурса (время ожидания). Например, если затраченное время составляет 2000 мс, а время ЦП — 300 мс, время ожидания — 1700 мс (2000 – 300 = 1700). Дополнительные сведения см. в разделе Типы ожиданий.
Примеры ожидающих запросов:
| Затраченное время (мс) | Время ЦП (мс) | Чтение (логическое) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Параллельные запросы — средство выполнения или официант
Параллельные запросы могут использовать больше времени ЦП, чем общая длительность. Цель параллелизма — разрешить нескольким потокам одновременно выполнять части запроса. За одну секунду часов запрос может использовать восемь секунд времени ЦП, выполнив восемь параллельных потоков. Поэтому становится сложно определить привязанный к ЦП или ожидающий запрос на основе затраченного времени и разницы во времени ЦП. Однако, как правило, следуйте принципам, перечисленным в двух разделах выше. Сводка:
За одну секунду часов запрос может использовать восемь секунд времени ЦП, выполнив восемь параллельных потоков. Поэтому становится сложно определить привязанный к ЦП или ожидающий запрос на основе затраченного времени и разницы во времени ЦП. Однако, как правило, следуйте принципам, перечисленным в двух разделах выше. Сводка:
- Если затраченное время гораздо больше времени ЦП, считайте его официантом.
- Если время ЦП гораздо больше, чем затраченное время, считайте его средствами выполнения.
Примеры параллельных запросов:
| Затраченное время (мс) | Время ЦП (мс) | Чтение (логическое) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
Общее визуальное представление методологии
Диагностика и разрешение ожидающих запросов
Если вы установили, что интересующие вас запросы являются официантами, следующим шагом будет решение проблем с узким местом. В противном случае перейдите к шагу 4. Диагностика и разрешение выполняемых запросов.
В противном случае перейдите к шагу 4. Диагностика и разрешение выполняемых запросов.
Чтобы оптимизировать запрос, ожидающий узких мест, определите, сколько времени ожидания и где находится узкое место (тип ожидания). После подтверждения типа ожидания сократите время ожидания или полностью исключите его.
Чтобы вычислить приблизительное время ожидания, вычесть время ЦП (время рабочей роли) из затраченного времени запроса. Как правило, время ЦП — это фактическое время выполнения, а оставшаяся часть времени существования запроса ожидается.
Примеры вычисления приблизительной продолжительности ожидания:
| Затраченное время (мс) | Время ЦП (мс) | Время ожидания (мс) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Определение узкого места или ожидания
Чтобы определить исторические запросы с длительным ожиданием (например, >20 % от общего затраченного времени составляет время ожидания), выполните следующий запрос.
Этот запрос использует статистику производительности для кэшированных планов запросов с начала SQL Server.SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCЧтобы определить выполняемые в настоящее время запросы с ожиданиями более 500 мс, выполните следующий запрос:
SELECT r.
session_id, r.wait_type, r.wait_time AS wait_time_ms
FROM sys.dm_exec_requests r
JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id
WHERE wait_time > 500
AND is_user_process = 1
Если вы можете собрать план запроса, проверьте WaitStats из свойств плана выполнения в SSMS:
- Выполните запрос с включением фактического плана выполнения в.
- Щелкните правой кнопкой мыши левый оператор на вкладке План выполнения .
- Выберите Свойства , а затем — Свойство WaitStats .
- Проверьте Значения WaitTimeMs и WaitType.
Если вы знакомы со сценариями PSSDiag/SQLdiag или SQL LogScout LightPerf/GeneralPerf, рассмотрите возможность использования любого из них для сбора статистики производительности и определения ожидающих запросов на экземпляре SQL Server. Вы можете импортировать собранные файлы данных и анализировать данные о производительности с помощью SQL Nexus.
 Этот запрос использует статистику производительности для кэшированных планов запросов с начала SQL Server.
Этот запрос использует статистику производительности для кэшированных планов запросов с начала SQL Server. session_id, r.wait_type, r.wait_time AS wait_time_ms
FROM sys.dm_exec_requests r
JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id
WHERE wait_time > 500
AND is_user_process = 1
session_id, r.wait_type, r.wait_time AS wait_time_ms
FROM sys.dm_exec_requests r
JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id
WHERE wait_time > 500
AND is_user_process = 1

Ссылки для устранения или сокращения ожиданий
Причины и способы их устранения для каждого типа ожидания различаются. Не существует единого общего метода для разрешения всех типов ожидания. Ниже приведены статьи по устранению неполадок и устранению распространенных проблем с типом ожидания:
- Общие сведения и устранение проблем с блокировкой (LCK_M_*)
- Общие сведения и устранение проблем с блокировкой базы данных Azure SQL
- Устранение неполадок с низкой производительностью SQL Server, вызванных проблемами ввода-вывода (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- ОЖИДАНИЙ WRITELOG и распространенных причин
- Разрешение конфликтов по вставке последней страницы PAGELATCH_EX в SQL Server
- Объяснения и решения, предоставляемые памятью (RESOURCE_SEMAPHORE)
- Устранение неполадок с медленными запросами, возникающими в результате ASYNC_NETWORK_IO типа ожидания
- Устранение неполадок с типом ожидания высокого HADR_SYNC_COMMIT в группах доступности Always On
- Как это работает: CMEMTHREAD и отладка
- Обеспечение того, чтобы параллельные ожидания были практическими
- ОЖИДАНИЕ THREADPOOL
Описание многих типов ожиданий и то, что они указывают, см. в таблице Типы ожиданий.
в таблице Типы ожиданий.
Диагностика и разрешение выполняемых запросов
Если время ЦП (рабочей роли) очень близко к общей затраченной длительности, запрос тратит большую часть времени выполнения. Как правило, когда подсистема SQL Server обеспечивает высокую загрузку ЦП, высокая загрузка ЦП приходится на запросы, которые выполняют большое количество логических операций чтения (наиболее распространенная причина).
Чтобы определить запросы, отвечающие за высокую активность ЦП, выполните следующую инструкцию:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st. dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
 dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Если в настоящее время запросы не управляют ЦП, можно выполнить следующую инструкцию, чтобы найти прошлые запросы с привязкой к ЦП:
SELECT TOP 10 st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs. total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
 total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Распространенные методы для разрешения длительных запросов, привязанных к ЦП
- Изучение плана запроса запроса
- Обновление статистики
- Определение и применение отсутствующих индексов. Дополнительные действия по выявлению отсутствующих индексов см. в разделе Настройка некластеризованных индексов с предложениями отсутствующих индексов.
- Перепроектирование или перезапись запросов
- Определение и разрешение планов с учетом параметров
- Выявление и устранение проблем с возможностью SARG
- Выявление и устранение проблем с целью строки , из-за которых длительные вложенные циклы могут быть вызваны top, EXISTS, IN, FAST, SET ROWCOUNT, OPTION (FAST N). Дополнительные сведения см. в разделах Цели строк ушли изгоев и Улучшения Showplan — Оценка цели строкиRowsWithoutRowGoal
- Оценка и устранение проблем с оценкой кратности . Дополнительные сведения см. в статье Снижение производительности запросов после обновления с SQL Server 2012 г. или более поздней версии до 2014 г.
- Определение и разрешение кубов, которые кажутся никогда не полными, см. статью Устранение неполадок с запросами, которые, кажется, никогда не заканчиваются в SQL Server
- Определение и разрешение медленных запросов, на которые влияет время ожидания оптимизатора
- Выявление проблем с высокой производительностью ЦП. Дополнительные сведения см. в статье Устранение неполадок с высокой загрузкой ЦП в SQL Server
- Устранение неполадок с запросом, который показывает значительную разницу в производительности между двумя серверами
- Увеличение вычислительных ресурсов в системе (ЦП)
- Устранение проблем с производительностью UPDATE с помощью узких и широких планов
 Дополнительные сведения см. в разделах Цели строк ушли изгоев и Улучшения Showplan — Оценка цели строкиRowsWithoutRowGoal
Дополнительные сведения см. в разделах Цели строк ушли изгоев и Улучшения Showplan — Оценка цели строкиRowsWithoutRowGoal- Обнаруживаемые типы узких мест производительности запросов в SQL Server и Управляемый экземпляр SQL Azure
- Средства для отслеживания и настройки производительности
- Параметры автоматической настройки в SQL Server
- Рекомендации по архитектуре индексирования и проектированию
- Устранение ошибок времени ожидания запроса
- Устранение проблем в SQL Server с высокой загрузкой ЦП
- Снижение производительности запросов после обновления с SQL Server 2012 или более ранней версии до 2014 или более поздней версии
Устранение неполадок медленных серверов: как проверить ЦП, ОЗУ и дисковый ввод-вывод
Изображение
Фото Дэвида Марка с Pixabay
Если вы достаточно долго выполняли работу системного администратора, вы видели ужасные инциденты «Сервер работает медленно». Долгое время подобные инциденты вызывали у меня комок в животе. Как, черт возьми, вы устраняете неполадки в чем-то настолько субъективном? «Замедление» обычного пользователя может быть просто вызвано другими процессами (запланированными или нет), работающими и потребляющими больше ресурсов, чем обычно, или что-то действительно может быть не так с сервером.
Долгое время подобные инциденты вызывали у меня комок в животе. Как, черт возьми, вы устраняете неполадки в чем-то настолько субъективном? «Замедление» обычного пользователя может быть просто вызвано другими процессами (запланированными или нет), работающими и потребляющими больше ресурсов, чем обычно, или что-то действительно может быть не так с сервером.
Когда я впервые начал работать системным администратором, я сразу же ответил: «Мне нужно больше информации об этом». Ну, обычно пользователь не может предоставить больше информации, потому что он не знает, что происходит за кулисами или как объяснить то, что он видит, кроме как «это просто медленно». В настоящее время, прежде чем я даже отвечу пользователю, я кое-что проверяю.
Начальный вход в систему
Вы можете многое узнать, войдя на хост. Вы вообще можете войти? Вход медленный или зависает? 9Команда 0015 ssh имеет три уровня отладки, каждый из которых предоставляет вам массу информации еще до того, как вы войдете в систему. Чтобы включить отладку, просто добавьте дополнительные
Чтобы включить отладку, просто добавьте дополнительные v к опции -v . Например, отладка третьего уровня, которую я использую исключительно, будет выглядеть так:
[~]$ ssh -vvv hostname.domain.com
«Большая тройка» (также известная как ЦП, ОЗУ и дисковый ввод-вывод)
Теперь давайте рассмотрим три основные причины замедления работы сервера: ЦП, ОЗУ и дисковый ввод-вывод. Использование ЦП может вызвать общую медлительность хоста и трудности со своевременным выполнением задач. Некоторые инструменты, которые я использую при анализе процессора, — 9.0015 топ и сар .
Проверка загрузки ЦП с помощью top
Утилита top позволяет в режиме реального времени отслеживать, что происходит с сервером. По умолчанию при запуске top отображается активность всех ЦП:
Изображение
Это представление можно изменить, нажав цифровую клавишу 1, которая добавляет дополнительные сведения о значениях использования для каждого ЦП:
Изображение
В этом представлении следует обратить внимание на среднюю загрузку (отображается в правой части верхней строки) и следующее значение для каждого ЦП:
-
us: Этот процент представляет собой количество ЦП, потребляемое пользовательскими процессами. -
sy: этот процент представляет собой количество ЦП, потребляемое системными процессами. -
id: этот процент показывает, насколько бездействует каждый ЦП.

Каждое из этих трех значений может дать вам довольно хорошее представление в режиме реального времени о том, связаны ли процессоры с пользовательскими или системными процессами.
Чтобы по-настоящему объяснить среднюю нагрузку, потребуется отдельная статья. Для целей этой статьи я буду говорить в общих чертах. Три средних значения нагрузки слева направо представляют собой одноминутные, пятиминутные и 15-минутные средние значения. Еще раз говорю очень В общем, если вы видите, что среднее значение за одну минуту превышает количество имеющихся у вас физических ЦП, то система, скорее всего, привязана к ЦП.
Примечание: Для получения дополнительной информации о средней нагрузке и о том, почему некоторые люди считают это число глупым, ознакомьтесь с подробным исследованием Брендана Грегга.
Проверка всей «большой тройки» с помощью sar
Для исторических данных о производительности ЦП я полагаюсь на команду sar , которая предоставляется пакетом sysstat . В большинстве серверных версий Linux sysstat установлен по умолчанию, но если это не так, вы можете добавить его с помощью диспетчера пакетов вашего дистрибутива. Утилита sar собирает системные данные каждые 10 минут с помощью задания cron, расположенного в /etc/cron.d/sysstat (CentOS 7.6). Вот как проверить всю «большую тройку», используя sar .
Примечание: Если вы только что установили sar в соответствии с этой статьей, сначала дайте команде некоторое время для записи данных.
Команда sar -u дает вам информацию обо всех процессорах в системе, начиная с полуночи:
Image
Как и в случае с top , здесь главное проверить %user , %system , %iowait и % простоя . Эта информация может сказать вам, как давно у сервера были проблемы.
Эта информация может сказать вам, как давно у сервера были проблемы.
В целом, команда sar может предоставить много информации. Поскольку в этой статье объясняется только быстрая проверка того, что происходит на сервере, проверьте man sar , чтобы еще больше разбить эту информацию.
Чтобы проверить производительность ОЗУ, я использую sar -r , что дает вам использование памяти в этот день:
Изображение
Главное, что нужно искать в использовании ОЗУ, это %memused и %commit . Несколько слов о поле %commit : в этом поле может отображаться значение выше 100%, так как ядро Linux обычно использует избыточный объем оперативной памяти. Если %commit постоянно превышает 100%, этот результат может указывать на то, что системе требуется больше оперативной памяти.
Для производительности дискового ввода-вывода я использую sar -d , что дает вам вывод дискового ввода-вывода, используя только имя устройства. Чтобы получить имя устройства, используйте
Чтобы получить имя устройства, используйте sar -dP :
Image
Для этого вывода просмотр %util и %await даст вам хорошую общую картину дискового ввода-вывода в системе. . Поле %util говорит само за себя: это использование этого устройства. Поле await содержит количество времени, в течение которого ввод-вывод находится в планировщике. Ожидание измеряется в миллисекундах, и в моей среде я видел, что все, что превышает 50 мс, начинает вызывать проблемы. Этот порог может отличаться в вашей среде.
Если какая-либо из этих команд показывает проблему, вы можете вернуться, чтобы увидеть, когда начались проблемы с сервером, используя sar {-u, -r, -d, -dP} -f /var/log/sa/sa< XX> (где XX — это число месяца, который вы хотите найти).
К этому моменту у меня обычно есть хорошее представление о том, что сейчас происходит на сервере и что происходило последние 48 часов или около того. Я отвечу пользователю более информированными ответами. Например: «Я не вижу признаков медлительности хоста за последние 24 часа. Попробуйте использовать новый профиль шпатлевки для
Я отвечу пользователю более информированными ответами. Например: «Я не вижу признаков медлительности хоста за последние 24 часа. Попробуйте использовать новый профиль шпатлевки для ssh , и дайте мне знать, если у вас по-прежнему возникнут проблемы.»
Другой пример: «Я не вижу ничего, что в настоящее время вызывает проблемы на этом хосте, но я заметил некоторую более высокую загрузку ЦП $time . Это когда вы увидели проблемы? Если это так, пожалуйста, попробуйте сейчас и дайте мне знать, если вы по-прежнему будете сталкиваться с проблемами». 10 минут на прогон — это очень помогает избежать новых вопросов и быстрее прийти к решению.0003
Темы:
линукс
Устранение неполадок
Как диагностировать медлительность приложений
Дориан Мартин Советы, рекомендации и ресурсы для разработчиков
Когда бизнес-приложение замедляется, случаются плохие вещи. Ваша служба поддержки забита запросами на обслуживание. Ваш начальник созывает экстренное совещание, чтобы поговорить с командой разработчиков и разработчиков. Все задают один и тот же вопрос: что случилось?
Ваша служба поддержки забита запросами на обслуживание. Ваш начальник созывает экстренное совещание, чтобы поговорить с командой разработчиков и разработчиков. Все задают один и тот же вопрос: что случилось?
Диагностика медленного приложения и поиск причины проблемы — это то, что разработчики должны делать быстро. Проблемы, связанные с производительностью, входят в первую пятерку оттока пользователей SaaS, что является серьезной предотвратимой потерей дохода.
Чтобы не потерять пользователей и сохранить положительный опыт, давайте узнаем, как диагностировать медлительность приложений.
1. Анализ типа замедления
Знание типа замедления работы приложения может помочь понять основной источник проблемы. Медлительность приложения может быть:
- Одноразовое
- Повторяющееся
В случае однократного замедления работы пользователь приложения, скорее всего, свяжется с вашей службой поддержки. Они могут отправить чат, электронное письмо или сообщение в социальных сетях или позвонить, чтобы сообщить вам о проблеме.
Но в случае повторяющегося замедления поведение пользователя может быть другим. Поскольку проблема не устранена, они могут обратиться непосредственно к команде разработчиков. После попытки решить ее самостоятельно — чтения статей базы знаний и т. д. — и обращения в службу поддержки, они, скорее всего, обратятся за помощью к разработчикам.
Почему так важно это знать?
Дэн Махоумс, технический обозреватель BestWritingAdvisor: «Когда пользователь сообщает о замедлении работы приложения, всегда спрашивайте, как долго это происходит. Повторяющаяся проблема может указывать на гораздо более сложную проблему, поэтому знание временной шкалы даст вам лучшее представление о том, к какой команде обратиться для устранения неполадок».
2. Проверьте производительность сервера
Неполадки с сервером являются распространенной причиной замедления работы приложений. Большинство современных приложений развертываются в сложной многоуровневой инфраструктуре с несколькими серверами, что создает множество потенциальных проблем. Инструмент, такой как Netreo, может помочь вам быстро и легко отслеживать, создавать отчеты и оповещения на вашем сервере и внутренних системах.
Инструмент, такой как Netreo, может помочь вам быстро и легко отслеживать, создавать отчеты и оповещения на вашем сервере и внутренних системах.
В дополнение к лучшему обзору производительности, работоспособности и использования серверов, Netreo обеспечивает полную прозрачность управления ИТ, которая измеряет состояние, рабочее состояние и влияние на бизнес всех компонентов в вашем технологическом стеке. Отслеживая весь стек технологий на одной платформе, вы получаете комплексные глобальные представления, которые позволяют быстро определить истинную причину сбоя и избежать параллельной траты времени несколькими командами на устранение неполадок.
Если говорить только о серверах, на скорость работы приложений могут влиять:
- Проблемы с производительностью сервера
- Недостаток оперативной памяти сервера
- Перегруженный сервер DNS, AD или LDAP.
Многие называют это «внешними зависимостями», и это именно то, чем они являются. Чтобы быть готовым к проблемам, связанным с сервером, вы можете визуально обозначить зависимости.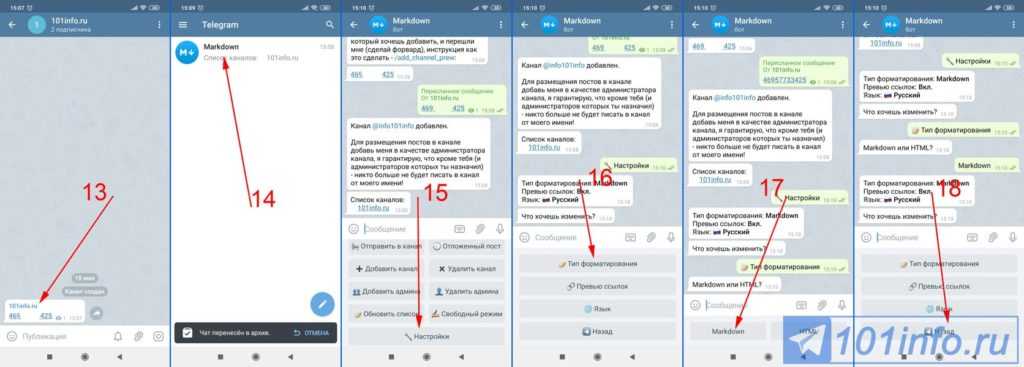
Этот метод называется сопоставлением зависимостей приложений (ADM).
Карта ADM включает все внешние зависимости приложения — хранилище, сети и серверы, конечно — и взаимодействия между ними. Взаимодействия показывают, как каждый компонент заставляет приложение работать.
Вот пример ADM для приложения Stackify. Он классифицирует все зависимости, влияющие на производительность приложения, и показывает, как они «общаются друг с другом».
Карта зависимостей приложения Stackify. Источник: блог Stackify
Наличие такой карты может помочь разработчикам выявить потенциальные проблемы. Если скорость приложения снижается, ADM является хорошим ресурсом для поиска узких мест и понимания того, какие ресурсы могут быть перегружены.
Рассмотрим пример.
Поставщик SaaS сталкивается с такими проблемами, как замедление работы облака и низкая производительность сети. В результате скорость приложения снижается, вызывая всевозможные проблемы у пользователей. Если провайдер выбирает традиционные методы устранения неполадок, сетевой команде требуется много времени, чтобы отследить проблему.
Если провайдер выбирает традиционные методы устранения неполадок, сетевой команде требуется много времени, чтобы отследить проблему.
Однако с помощью ADM ИТ-персонал может быстрее определить проблему. Они могут получить четкое представление о «большой картине», что означает понимание того, как взаимосвязаны службы и компоненты. В конечном счете, анализ ADM может занять гораздо меньше времени.
Связано: Оптимизация веб-производительности: 3 основных совета по повышению производительности сервера и клиента
3. Исследование проблем на стороне клиента
В некоторых случаях производительность приложения снижается из-за проблем, возникающих на клиентских конечных точках. Это может быть одним из самых сложных для диагностики, но вы должны быть готовы.
Вот несколько сценариев.
- Устаревшие клиентские системы . Многие компании, использующие ваше пользовательское приложение, могут использовать старое оборудование, что часто означает нехватку мощности для его эффективной работы. В результате основной причиной замедления может быть устаревшая локальная дисковая система хранения, медленный ЦП или нехватка памяти
- Архитектура приложения . Приложение может использовать ненормальные объемы памяти или много ресурсов ЦП на стороне клиента исключительно из-за архитектуры. В этом случае под диагностикой понимается проверка функций и возможностей на стороне пользователя, которая осуществляется путем получения доступа от клиента 9.0052
- Конкурс ресурсов . В некоторых случаях причиной низкой скорости является обилие программ, конкурирующих за дисковый ввод-вывод и пропускную способность сети, память, процессор и другие ресурсы. Тщательный анализ шаблонов использования ресурсов обычно показывает, как «конкуренция» может повлиять на возможность корректного запуска бизнес-приложений.
 В результате основной причиной замедления может быть устаревшая локальная дисковая система хранения, медленный ЦП или нехватка памяти
В результате основной причиной замедления может быть устаревшая локальная дисковая система хранения, медленный ЦП или нехватка памяти Лучший способ решить подобные проблемы — получить доступ к клиентским системам. Если вы уверены, что с вашей стороны что-то работает правильно, всегда учитывайте возможность того, что это может произойти в системах конечного пользователя. Один из способов диагностировать это — установить такую систему, как Retrace, для мониторинга вашей клиентской стороны с помощью Real User Monitoring.
Один из способов диагностировать это — установить такую систему, как Retrace, для мониторинга вашей клиентской стороны с помощью Real User Monitoring.
4. Напишите достойную базу знаний
Некоторые причины медленной работы приложения можно легко устранить. Например, браузер пользователя или мобильное устройство потенциально могут быть источником проблем с производительностью.
Вот почему важно иметь ресурс самопомощи для клиентов. Для поставщиков SaaS этот ресурс называется базой знаний.
База знаний — это набор статей с пошаговыми инструкциями по устранению неполадок. Для ваших пользователей это место, где они могут получить помощь в устранении различных проблем с производительностью. Не всегда возможно связаться с вашей службой поддержки или командой разработчиков, поэтому пользователи должны получить возможность диагностировать их самостоятельно.
Вот пример статьи базы знаний от Salesforce, платформы управления взаимоотношениями с клиентами.
Статья базы знаний о низкой производительности приложений (Salesforce).
Подобный контент может быть полезен для решения простых проблем с производительностью, которые не должны отнимать время у вашей службы поддержки.
5. Инвестируйте в инструмент мониторинга производительности приложений (APM)
Ищете более автоматизированный подход к отслеживанию работоспособности вашего приложения? Как всегда, для этого есть приложение. И это может значительно облегчить жизнь вашим разработчикам (по крайней мере, в офисе).
Мониторинг производительности приложений (APM) — это инструмент, который обеспечивает непрерывный мониторинг приложений для диагностики проблем с производительностью и обеспечения согласованного времени отклика и доступности.
По сути, APM — это все ранее упомянутые подходы, автоматизированные для разработчиков, чтобы сделать работу по мониторингу более эффективной.
Решение Stackify APM Retrace может помочь им:
- Отслеживание времени отклика и количества ошибок
- Просмотр наиболее трудоемких транзакций для обнаружения медленных
- Ведите журнал приложений
- Разбивайте каждую транзакцию на среднее число вызовов, время и другие сведения о производительности.

Попробуйте бесплатную двухнедельную пробную версию Retrace уже сегодня.
Таким образом, APM — это панель управления, на которой можно просмотреть все показатели и тенденции производительности приложений. Отслеживая каждую транзакцию, вы будете точно знать, работает ли приложение идеально.
Связано: 8 ключевых показателей производительности приложений и способы их измерения
Мониторинг производительности приложений: заключение
Когда бизнес-приложения замедляются, страдают все. Свести к минимуму влияние этой проблемы можно за счет быстрой диагностики и устранения неполадок, чего пользователи ожидают от поставщиков SaaS.
Используйте эти советы, чтобы улучшить мониторинг производительности приложений и реагировать на возникающие проблемы. Ваши пользователи будут рады, что вы это сделали.
- Об авторе
- Последние сообщения
О Дориане Мартине
Дориан Мартин — автор контента для малого бизнеса в EssaySupply.